 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction
Feb 05, 2026Large Language Models have shown strong capabilities in complex problem solving, yet many agentic systems remain difficult to interpret and control due to opaque internal workflows. While some frameworks offer explicit architectures for collaboration, many deployed agentic systems operate as black boxes to users. We address this by introducing Agentic Workflow Reconstruction (AWR), a new task aiming to synthesize an explicit, interpretable stand-in workflow that approximates a black-box system using only input--output access. We propose AgentXRay, a search-based framework that formulates AWR as a combinatorial optimization problem over discrete agent roles and tool invocations in a chain-structured workflow space. Unlike model distillation, AgentXRay produces editable white-box workflows that match target outputs under an observable, output-based proxy metric, without accessing model parameters. To navigate the vast search space, AgentXRay employs Monte Carlo Tree Search enhanced by a scoring-based Red-Black Pruning mechanism, which dynamically integrates proxy quality with search depth. Experiments across diverse domains demonstrate that AgentXRay achieves higher proxy similarity and reduces token consumption compared to unpruned search, enabling deeper workflow exploration under fixed iteration budgets.
Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science
Feb 05, 2026Recent advancements in Large Language Models (LLMs) have greatly extended the capabilities of Multi-Agent Systems (MAS), demonstrating significant effectiveness across a wide range of complex and open-ended domains. However, despite this rapid progress, the field still relies heavily on empirical trial-and-error. It lacks a unified and principled scientific framework necessary for systematic optimization and improvement. This bottleneck stems from the ambiguity of attribution: first, the absence of a structured taxonomy of factors leaves researchers restricted to unguided adjustments; second, the lack of a unified metric fails to distinguish genuine collaboration gain from mere resource accumulation. In this paper, we advocate for a transition to design science through an integrated framework. We advocate to establish the collaboration gain metric ($Γ$) as the scientific standard to isolate intrinsic gains from increased budgets. Leveraging $Γ$, we propose a factor attribution paradigm to systematically identify collaboration-driving factors. To support this, we construct a systematic MAS factor library, structuring the design space into control-level presets and information-level dynamics. Ultimately, this framework facilitates the transition from blind experimentation to rigorous science, paving the way towards a true science of Collective AI.
Multi-Agent Collaboration via Evolving Orchestration
May 26, 2025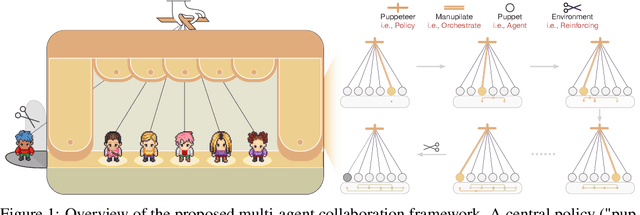
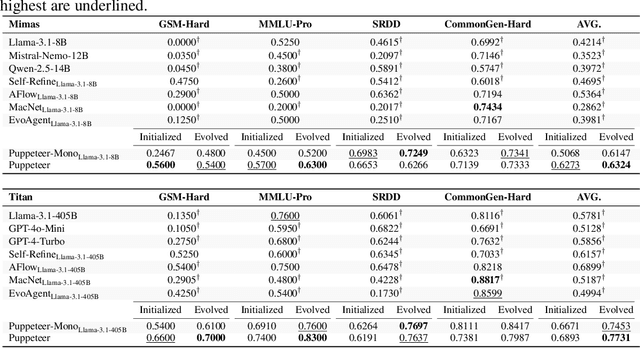
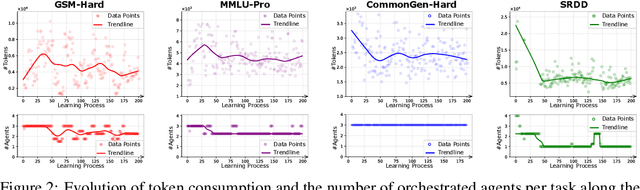
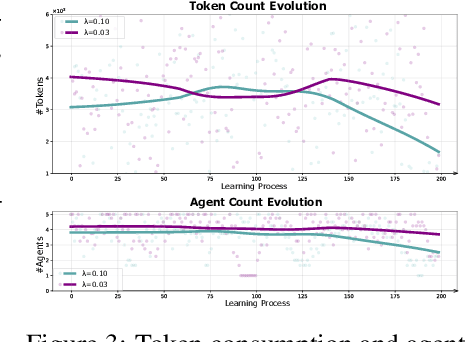
Large language models (LLMs) have achieved remarkable results across diverse downstream tasks, but their monolithic nature restricts scalability and efficiency in complex problem-solving. While recent research explores multi-agent collaboration among LLMs, most approaches rely on static organizational structures that struggle to adapt as task complexity and agent numbers grow, resulting in coordination overhead and inefficiencies. To this end, we propose a puppeteer-style paradigm for LLM-based multi-agent collaboration, where a centralized orchestrator ("puppeteer") dynamically directs agents ("puppets") in response to evolving task states. This orchestrator is trained via reinforcement learning to adaptively sequence and prioritize agents, enabling flexible and evolvable collective reasoning. Experiments on closed- and open-domain scenarios show that this method achieves superior performance with reduced computational costs. Analyses further reveal that the key improvements consistently stem from the emergence of more compact, cyclic reasoning structures under the orchestrator's evolution.
AgentRM: Enhancing Agent Generalization with Reward Modeling
Feb 25, 2025Existing LLM-based agents have achieved strong performance on held-in tasks, but their generalizability to unseen tasks remains poor. Hence, some recent work focus on fine-tuning the policy model with more diverse tasks to improve the generalizability. In this work, we find that finetuning a reward model to guide the policy model is more robust than directly finetuning the policy model. Based on this finding, we propose AgentRM, a generalizable reward model, to guide the policy model for effective test-time search. We comprehensively investigate three approaches to construct the reward model, including explicit reward modeling, implicit reward modeling and LLM-as-a-judge. We then use AgentRM to guide the answer generation with Best-of-N sampling and step-level beam search. On four types of nine agent tasks, AgentRM enhances the base policy model by $8.8$ points on average, surpassing the top general agent by $4.0$. Moreover, it demonstrates weak-to-strong generalization, yielding greater improvement of $12.6$ on LLaMA-3-70B policy model. As for the specializability, AgentRM can also boost a finetuned policy model and outperform the top specialized agent by $11.4$ on three held-in tasks. Further analysis verifies its effectiveness in test-time scaling. Codes will be released to facilitate the research in this area.