 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Causal Dynamics Models in Object-Oriented Environments
May 21, 2024



Causal dynamics models (CDMs) have demonstrated significant potential in addressing various challenges in reinforcement learning. To learn CDMs, recent studies have performed causal discovery to capture the causal dependencies among environmental variables. However, the learning of CDMs is still confined to small-scale environments due to computational complexity and sample efficiency constraints. This paper aims to extend CDMs to large-scale object-oriented environments, which consist of a multitude of objects classified into different categories. We introduce the Object-Oriented CDM (OOCDM) that shares causalities and parameters among objects belonging to the same class. Furthermore, we propose a learning method for OOCDM that enables it to adapt to a varying number of objects. Experiments on large-scale tasks indicate that OOCDM outperforms existing CDMs in terms of causal discovery, prediction accuracy, generalization, and computational efficiency.
Learning Top-k Subtask Planning Tree based on Discriminative Representation Pre-training for Decision Making
Dec 18, 2023Many complicated real-world tasks can be broken down into smaller, more manageable parts, and planning with prior knowledge extracted from these simplified pieces is crucial for humans to make accurate decisions. However, replicating this process remains a challenge for AI agents and naturally raises two questions: How to extract discriminative knowledge representation from priors? How to develop a rational plan to decompose complex problems? Most existing representation learning methods employing a single encoder structure are fragile and sensitive to complex and diverse dynamics. To address this issue, we introduce a multiple-encoder and individual-predictor regime to learn task-essential representations from sufficient data for simple subtasks. Multiple encoders can extract adequate task-relevant dynamics without confusion, and the shared predictor can discriminate the task characteristics. We also use the attention mechanism to generate a top-k subtask planning tree, which customizes subtask execution plans in guiding complex decisions on unseen tasks. This process enables forward-looking and globality by flexibly adjusting the depth and width of the planning tree. Empirical results on a challenging platform composed of some basic simple tasks and combinatorially rich synthetic tasks consistently outperform some competitive baselines and demonstrate the benefits of our design.
Balancing Exploration and Exploitation in Hierarchical Reinforcement Learning via Latent Landmark Graphs
Jul 22, 2023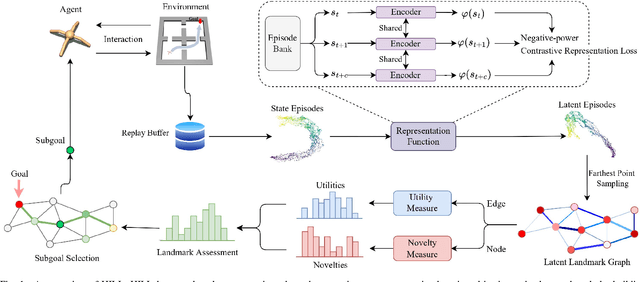
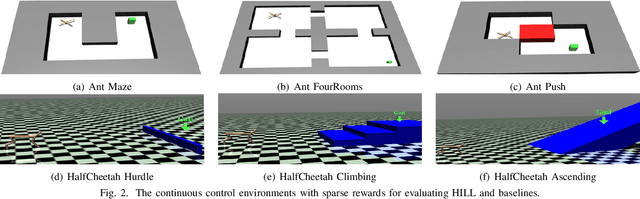
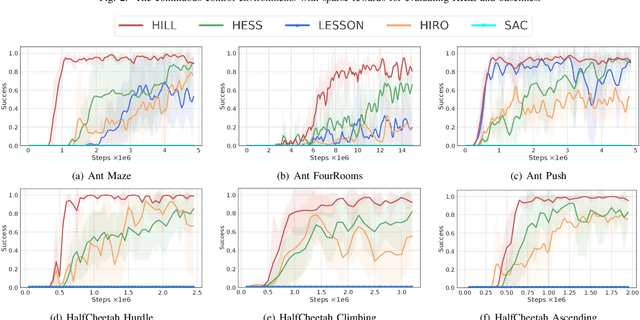
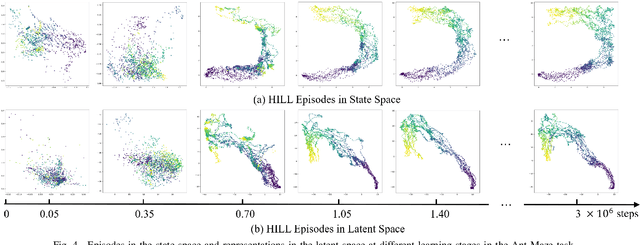
Goal-Conditioned Hierarchical Reinforcement Learning (GCHRL) is a promising paradigm to address the exploration-exploitation dilemma in reinforcement learning. It decomposes the source task into subgoal conditional subtasks and conducts exploration and exploitation in the subgoal space. The effectiveness of GCHRL heavily relies on subgoal representation functions and subgoal selection strategy. However, existing works often overlook the temporal coherence in GCHRL when learning latent subgoal representations and lack an efficient subgoal selection strategy that balances exploration and exploitation. This paper proposes HIerarchical reinforcement learning via dynamically building Latent Landmark graphs (HILL) to overcome these limitations. HILL learns latent subgoal representations that satisfy temporal coherence using a contrastive representation learning objective. Based on these representations, HILL dynamically builds latent landmark graphs and employs a novelty measure on nodes and a utility measure on edges. Finally, HILL develops a subgoal selection strategy that balances exploration and exploitation by jointly considering both measures. Experimental results demonstrate that HILL outperforms state-of-the-art baselines on continuous control tasks with sparse rewards in sample efficiency and asymptotic performance. Our code is available at https://github.com/papercode2022/HILL.
Explainable Reinforcement Learning via a Causal World Model
May 15, 2023


Generating explanations for reinforcement learning (RL) is challenging as actions may produce long-term effects on the future. In this paper, we develop a novel framework for explainable RL by learning a causal world model without prior knowledge of the causal structure of the environment. The model captures the influence of actions, allowing us to interpret the long-term effects of actions through causal chains, which present how actions influence environmental variables and finally lead to rewards. Different from most explanatory models which suffer from low accuracy, our model remains accurate while improving explainability, making it applicable in model-based learning. As a result, we demonstrate that our causal model can serve as the bridge between explainability and learning.
General Robot Dynamics Learning and Gen2Real
Apr 06, 2021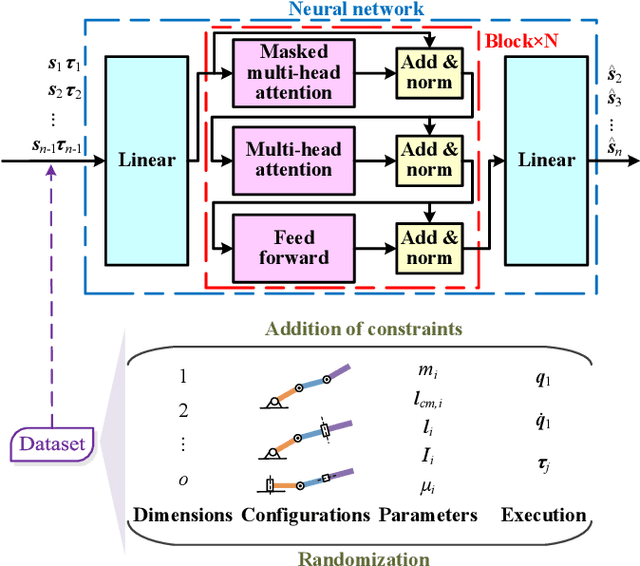
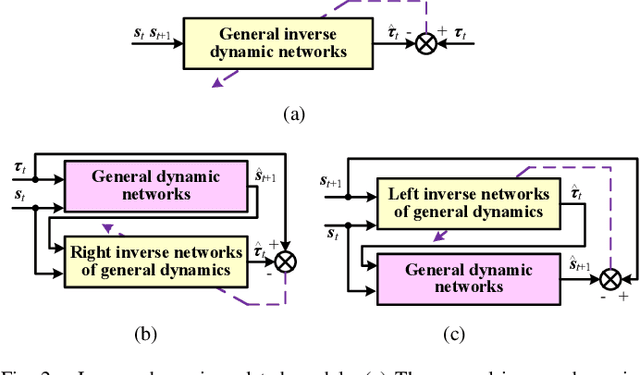
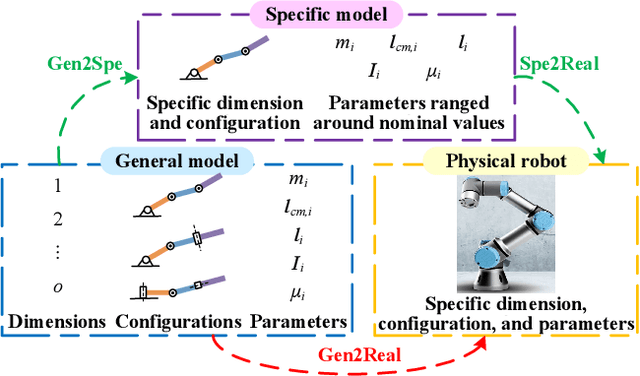
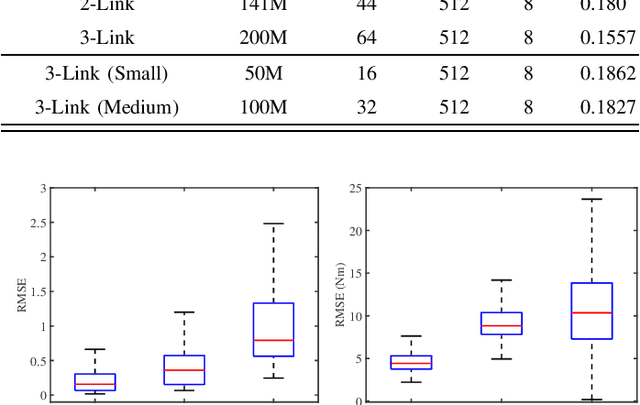
Acquiring dynamics is an essential topic in robot learning, but up-to-date methods, such as dynamics randomization, need to restart to check nominal parameters, generate simulation data, and train networks whenever they face different robots. To improve it, we novelly investigate general robot dynamics, its inverse models, and Gen2Real, which means transferring to reality. Our motivations are to build a model that learns the intrinsic dynamics of various robots and lower the threshold of dynamics learning by enabling an amateur to obtain robot models without being trapped in details. This paper achieves the "generality" by randomizing dynamics parameters, topology configurations, and model dimensions, which in sequence cover the property, the connection, and the number of robot links. A structure modified from GPT is applied to access the pre-training model of general dynamics. We also study various inverse models of dynamics to facilitate different applications. We step further to investigate a new concept, "Gen2Real", to transfer simulated, general models to physical, specific robots. Simulation and experiment results demonstrate the validity of the proposed models and method.\footnote{ These authors contribute equally.