 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideLight: "Industrial Solution" Guidance for More Practical Traffic Signal Control Agents
Jul 15, 2024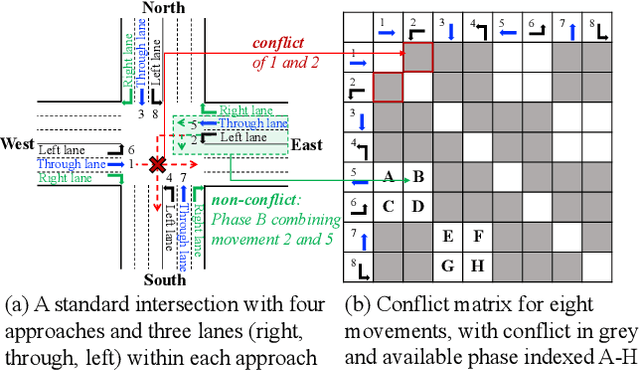
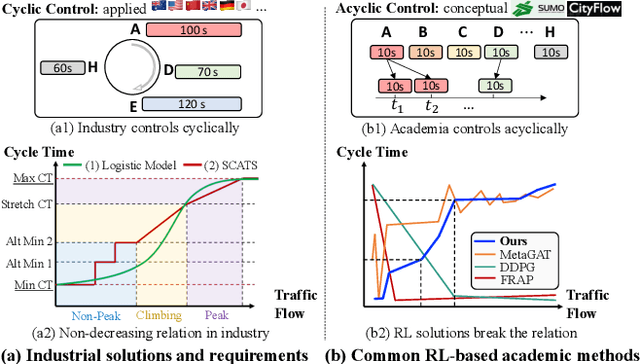
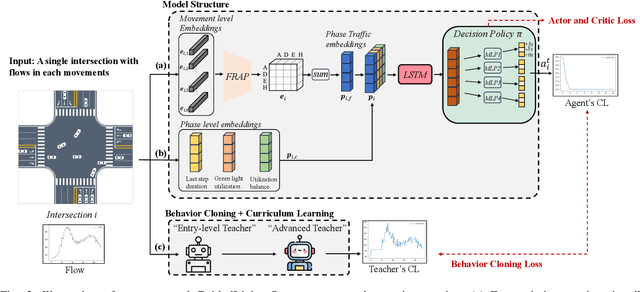
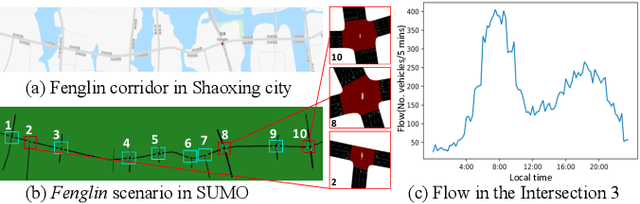
Currently, traffic signal control (TSC) methods based on reinforcement learning (RL) have proven superior to traditional methods. However, most RL methods face difficulties when applied in the real world due to three factors: input, output, and the cycle-flow relation. The industry's observable input is much more limited than simulation-based RL methods. For real-world solutions, only flow can be reliably collected, whereas common RL methods need more. For the output action, most RL methods focus on acyclic control, which real-world signal controllers do not support. Most importantly, industry standards require a consistent cycle-flow relationship: non-decreasing and different response strategies for low, medium, and high-level flows, which is ignored by the RL methods. To narrow the gap between RL methods and industry standards, we innovatively propose to use industry solutions to guide the RL agent. Specifically, we design behavior cloning and curriculum learning to guide the agent to mimic and meet industry requirements and, at the same time, leverage the power of exploration and exploitation in RL for better performance. We theoretically prove that such guidance can largely decrease the sample complexity to polynomials in the horizon when searching for an optimal policy. Our rigid experiments show that our method has good cycle-flow relation and superior performance.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Oct 31, 2023

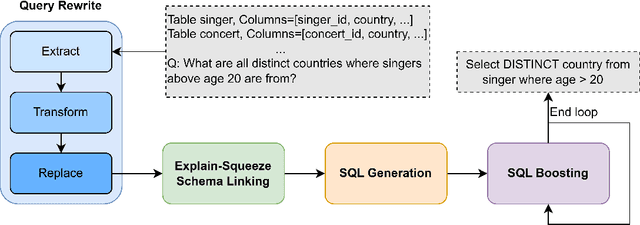

The previous state-of-the-art (SOTA) method achieved a remarkable execution accuracy on the Spider dataset, which is one of the largest and most diverse datasets in the Text-to-SQL domain. However, during our reproduction of the business dataset, we observed a significant drop in performance. We examined the differences in dataset complexity, as well as the clarity of questions' intentions, and assessed how those differences could impact the performance of prompting methods. Subsequently, We develop a more adaptable and more general prompting method, involving mainly query rewriting and SQL boosting, which respectively transform vague information into exact and precise information and enhance the SQL itself by incorporating execution feedback and the query results from the database content. In order to prevent information gaps, we include the comments, value types, and value samples for columns as part of the database description in the prompt. Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method. In terms of execution accuracy on the business dataset, the SOTA method scored 21.05, while our approach scored 65.79. As a result, our approach achieved a notable performance improvement even when using a less capable pre-trained language model. Last but not least, we also explore the Text-to-Python and Text-to-Function options, and we deeply analyze the pros and cons among them, offering valuable insights to the community.