 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Paper and Code
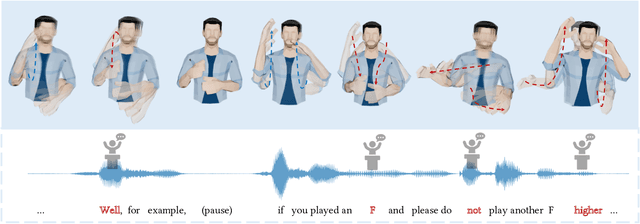
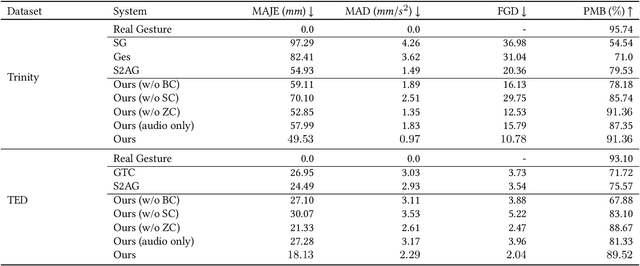
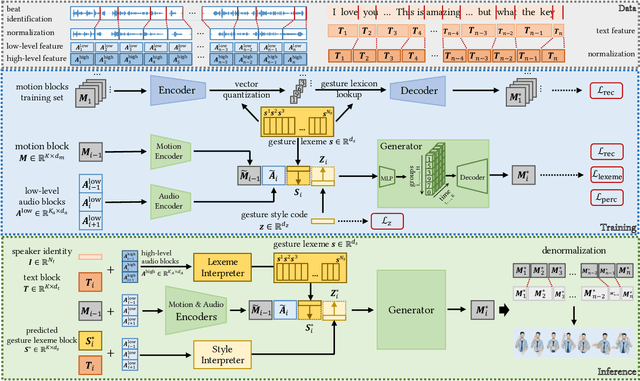

Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.