 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continually by Spectral Regularization
Paper and Code
Jun 10, 2024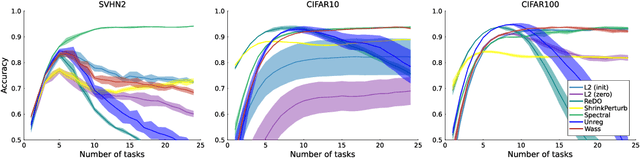

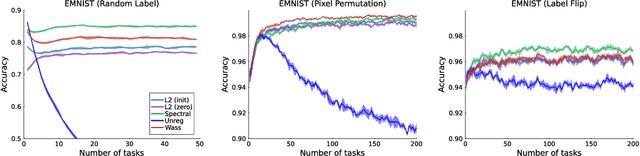
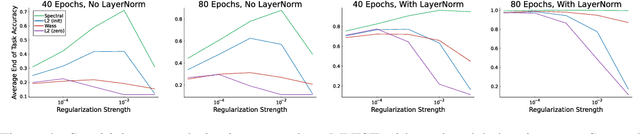
Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.