 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Conditional Likelihood Rewards for Multiagent Exploration
Feb 12, 2026Efficient exploration is critical for multiagent systems to discover coordinated strategies, particularly in open-ended domains such as search and rescue or planetary surveying. However, when exploration is encouraged only at the individual agent level, it often leads to redundancy, as agents act without awareness of how their teammates are exploring. In this work, we introduce Counterfactual Conditional Likelihood (CCL) rewards, which score each agent's exploration by isolating its unique contribution to team exploration. Unlike prior methods that reward agents solely for the novelty of their individual observations, CCL emphasizes observations that are informative with respect to the joint exploration of the team. Experiments in continuous multiagent domains show that CCL rewards accelerate learning for domains with sparse team rewards, where most joint actions yield zero rewards, and are particularly effective in tasks that require tight coordination among agents.
How Does the Lagrangian Guide Safe Reinforcement Learning through Diffusion Models?
Feb 02, 2026Diffusion policy sampling enables reinforcement learning (RL) to represent multimodal action distributions beyond suboptimal unimodal Gaussian policies. However, existing diffusion-based RL methods primarily focus on offline settings for reward maximization, with limited consideration of safety in online settings. To address this gap, we propose Augmented Lagrangian-Guided Diffusion (ALGD), a novel algorithm for off-policy safe RL. By revisiting optimization theory and energy-based model, we show that the instability of primal-dual methods arises from the non-convex Lagrangian landscape. In diffusion-based safe RL, the Lagrangian can be interpreted as an energy function guiding the denoising dynamics. Counterintuitively, direct usage destabilizes both policy generation and training. ALGD resolves this issue by introducing an augmented Lagrangian that locally convexifies the energy landscape, yielding a stabilized policy generation and training process without altering the distribution of the optimal policy. Theoretical analysis and extensive experiments demonstrate that ALGD is both theoretically grounded and empirically effective, achieving strong and stable performance across diverse environments.
Safe Multiagent Coordination via Entropic Exploration
Dec 29, 2024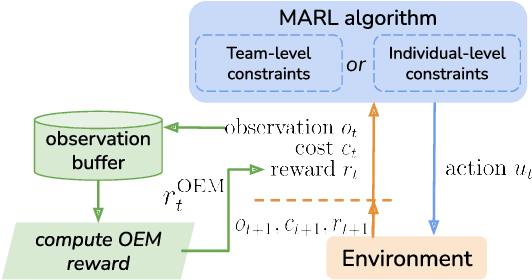
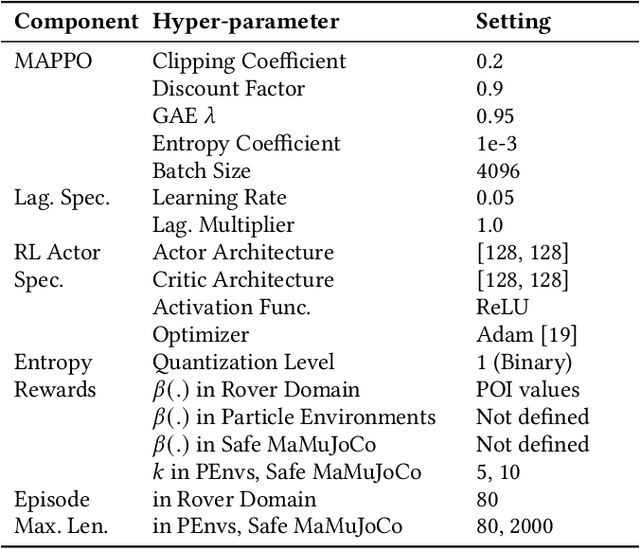
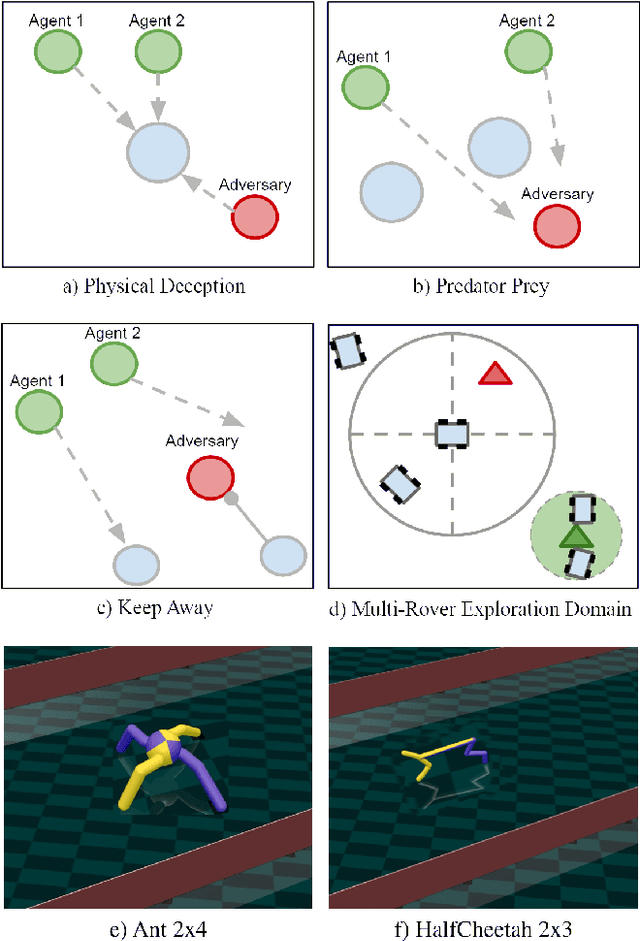
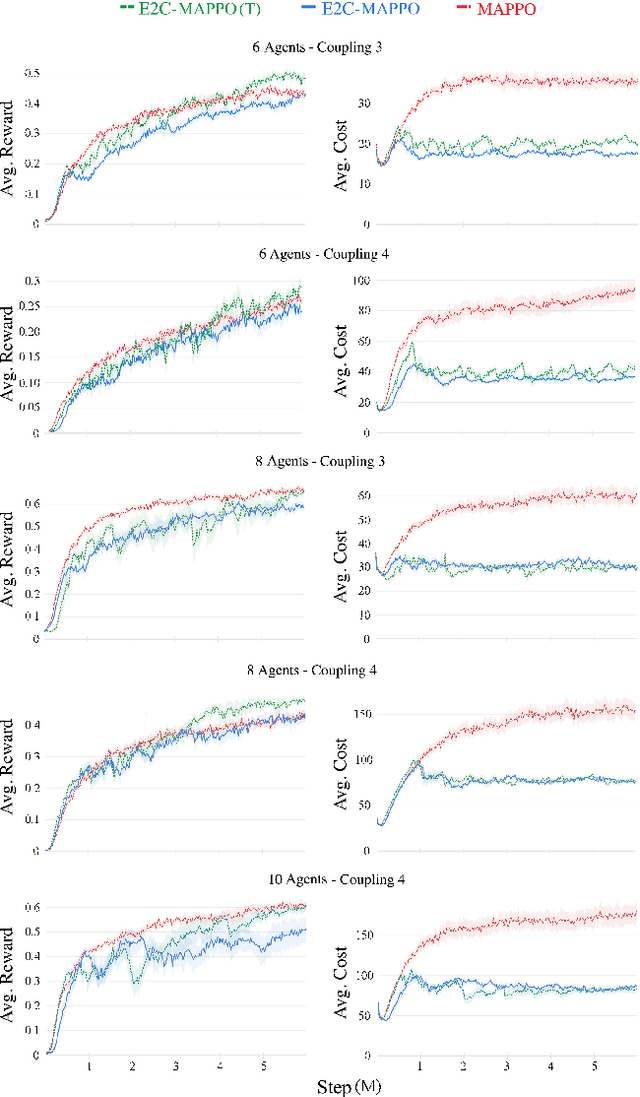
Many real-world multiagent learning problems involve safety concerns. In these setups, typical safe reinforcement learning algorithms constrain agents' behavior, limiting exploration -- a crucial component for discovering effective cooperative multiagent behaviors. Moreover, the multiagent literature typically models individual constraints for each agent and has yet to investigate the benefits of using joint team constraints. In this work, we analyze these team constraints from a theoretical and practical perspective and propose entropic exploration for constrained multiagent reinforcement learning (E2C) to address the exploration issue. E2C leverages observation entropy maximization to incentivize exploration and facilitate learning safe and effective cooperative behaviors. Experiments across increasingly complex domains show that E2C agents match or surpass common unconstrained and constrained baselines in task performance while reducing unsafe behaviors by up to $50\%$.
On the Complexity of Learning to Cooperate with Populations of Socially Rational Agents
Jun 29, 2024
Artificially intelligent agents deployed in the real-world will require the ability to reliably \textit{cooperate} with humans (as well as other, heterogeneous AI agents). To provide formal guarantees of successful cooperation, we must make some assumptions about how partner agents could plausibly behave. Any realistic set of assumptions must account for the fact that other agents may be just as adaptable as our agent is. In this work, we consider the problem of cooperating with a \textit{population} of agents in a finitely-repeated, two player general-sum matrix game with private utilities. Two natural assumptions in such settings are that: 1) all agents in the population are individually rational learners, and 2) when any two members of the population are paired together, with high-probability they will achieve at least the same utility as they would under some Pareto efficient equilibrium strategy. Our results first show that these assumptions alone are insufficient to ensure \textit{zero-shot} cooperation with members of the target population. We therefore consider the problem of \textit{learning} a strategy for cooperating with such a population using prior observations its members interacting with one another. We provide upper and lower bounds on the number of samples needed to learn an effective cooperation strategy. Most importantly, we show that these bounds can be much stronger than those arising from a "naive'' reduction of the problem to one of imitation learning.
AI4GCC-Team -- Below Sea Level: Score and Real World Relevance
Aug 04, 2023
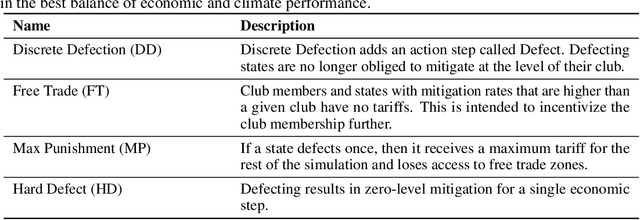

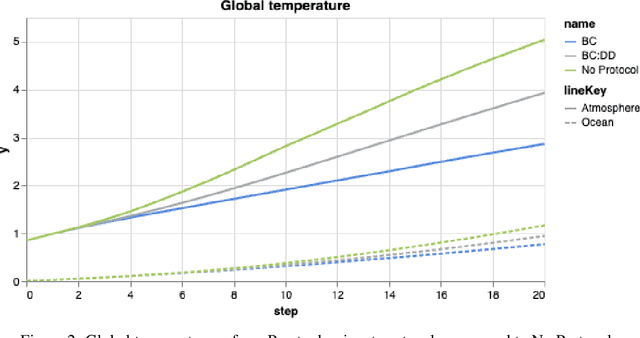
As our submission for track three of the AI for Global Climate Cooperation (AI4GCC) competition, we propose a negotiation protocol for use in the RICE-N climate-economic simulation. Our proposal seeks to address the challenges of carbon leakage through methods inspired by the Carbon Border Adjustment Mechanism (CBAM) and Climate Clubs (CC). We demonstrate the effectiveness of our approach by comparing simulated outcomes to representative concentration pathways (RCP) and shared socioeconomic pathways (SSP). Our protocol results in a temperature rise comparable to RCP 3.4/4.5 and SSP 2. Furthermore, we provide an analysis of our protocol's World Trade Organization compliance, administrative and political feasibility, and ethical concerns. We recognize that our proposal risks hurting the least developing countries, and we suggest specific corrective measures to avoid exacerbating existing inequalities, such as technology sharing and wealth redistribution. Future research should improve the RICE-N tariff mechanism and implement actions allowing for the aforementioned corrective measures.
AI4GCC - Team: Below Sea Level: Critiques and Improvements
Aug 04, 2023

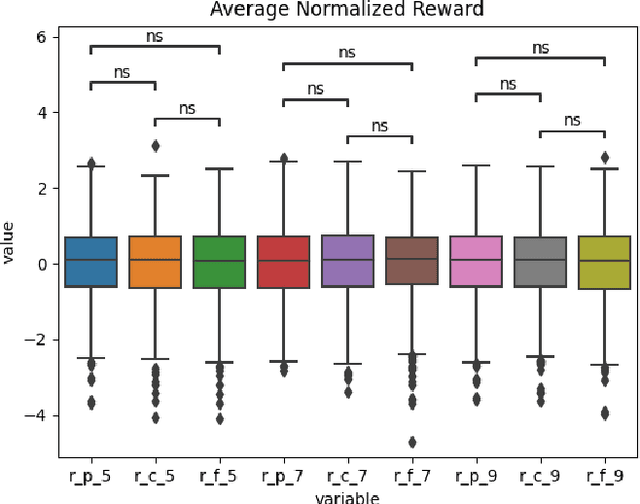
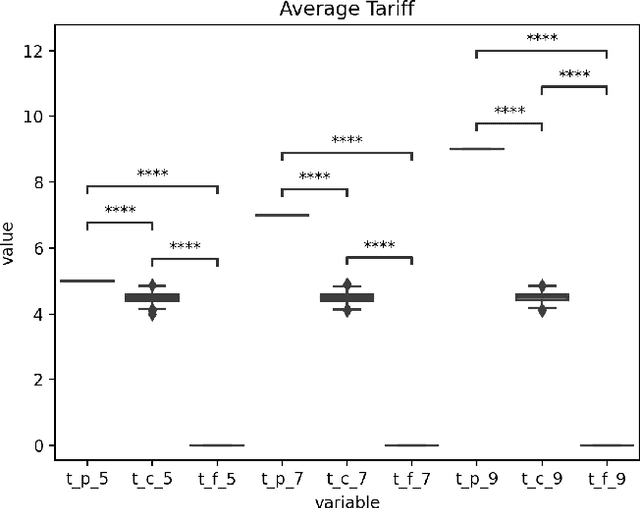
We present a critical analysis of the simulation framework RICE-N, an integrated assessment model (IAM) for evaluating the impacts of climate change on the economy. We identify key issues with RICE-N, including action masking and irrelevant actions, and suggest improvements such as utilizing tariff revenue and penalizing overproduction. We also critically engage with features of IAMs in general, namely overly optimistic damage functions and unrealistic abatement cost functions. Our findings contribute to the ongoing efforts to further develop the RICE-N framework in an effort to improve the simulation, making it more useful as an inspiration for policymakers.
Towards a Unifying Model of Rationality in Multiagent Systems
May 29, 2023Multiagent systems deployed in the real world need to cooperate with other agents (including humans) nearly as effectively as these agents cooperate with one another. To design such AI, and provide guarantees of its effectiveness, we need to clearly specify what types of agents our AI must be able to cooperate with. In this work we propose a generic model of socially intelligent agents, which are individually rational learners that are also able to cooperate with one another (in the sense that their joint behavior is Pareto efficient). We define rationality in terms of the regret incurred by each agent over its lifetime, and show how we can construct socially intelligent agents for different forms of regret. We then discuss the implications of this model for the development of "robust" MAS that can cooperate with a wide variety of socially intelligent agents.
Uncoupled Learning of Differential Stackelberg Equilibria with Commitments
Feb 07, 2023A natural solution concept for many multiagent settings is the Stackelberg equilibrium, under which a ``leader'' agent selects a strategy that maximizes its own payoff assuming the ``follower'' chooses their best response to this strategy. Recent work has presented asymmetric learning updates that can be shown to converge to the \textit{differential} Stackelberg equilibria of two-player differentiable games. These updates are ``coupled'' in the sense that the leader requires some information about the follower's payoff function. Such coupled learning rules cannot be applied to \textit{ad hoc} interactive learning settings, and can be computationally impractical even in centralized training settings where the follower's payoffs are known. In this work, we present an ``uncoupled'' learning process under which each player's learning update only depends on their observations of the other's behavior. We prove that this process converges to a local Stackelberg equilibrium under similar conditions as previous coupled methods. We conclude with a discussion of the potential applications of our approach to human--AI cooperation and multi-agent reinforcement learning.
On the Impossibility of Learning to Cooperate with Adaptive Partner Strategies in Repeated Games
Jun 20, 2022Learning to cooperate with other agents is challenging when those agents also possess the ability to adapt to our own behavior. Practical and theoretical approaches to learning in cooperative settings typically assume that other agents' behaviors are stationary, or else make very specific assumptions about other agents' learning processes. The goal of this work is to understand whether we can reliably learn to cooperate with other agents without such restrictive assumptions, which are unlikely to hold in real-world applications. Our main contribution is a set of impossibility results, which show that no learning algorithm can reliably learn to cooperate with all possible adaptive partners in a repeated matrix game, even if that partner is guaranteed to cooperate with some stationary strategy. Motivated by these results, we then discuss potential alternative assumptions which capture the idea that an adaptive partner will only adapt rationally to our behavior.
Strategically Efficient Exploration in Competitive Multi-agent Reinforcement Learning
Jul 30, 2021


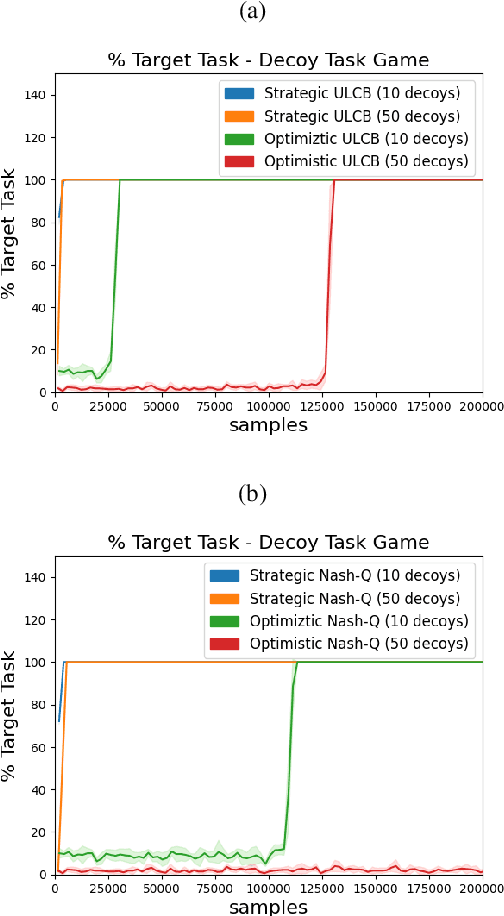
High sample complexity remains a barrier to the application of reinforcement learning (RL), particularly in multi-agent systems. A large body of work has demonstrated that exploration mechanisms based on the principle of optimism under uncertainty can significantly improve the sample efficiency of RL in single agent tasks. This work seeks to understand the role of optimistic exploration in non-cooperative multi-agent settings. We will show that, in zero-sum games, optimistic exploration can cause the learner to waste time sampling parts of the state space that are irrelevant to strategic play, as they can only be reached through cooperation between both players. To address this issue, we introduce a formal notion of strategically efficient exploration in Markov games, and use this to develop two strategically efficient learning algorithms for finite Markov games. We demonstrate that these methods can be significantly more sample efficient than their optimistic counterparts.