 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Flexible $f$-divergence for Challenging Offline RL Datasets with Low Stochasticity and Diverse Behavior Policies
Feb 11, 2026Offline RL algorithms aim to improve upon the behavior policy that produces the collected data while constraining the learned policy to be within the support of the dataset. However, practical offline datasets often contain examples with little diversity or limited exploration of the environment, and from multiple behavior policies with diverse expertise levels. Limited exploration can impair the offline RL algorithm's ability to estimate \textit{Q} or \textit{V} values, while constraining towards diverse behavior policies can be overly conservative. Such datasets call for a balance between the RL objective and behavior policy constraints. We first identify the connection between $f$-divergence and optimization constraint on the Bellman residual through a more general Linear Programming form for RL and the convex conjugate. Following this, we introduce the general flexible function formulation for the $f$-divergence to incorporate an adaptive constraint on algorithms' learning objectives based on the offline training dataset. Results from experiments on the MuJoCo, Fetch, and AdroitHand environments show the correctness of the proposed LP form and the potential of the flexible $f$-divergence in improving performance for learning from a challenging dataset when applied to a compatible constrained optimization algorithm.
Action-Dependent Optimality-Preserving Reward Shaping
May 19, 2025Recent RL research has utilized reward shaping--particularly complex shaping rewards such as intrinsic motivation (IM)--to encourage agent exploration in sparse-reward environments. While often effective, ``reward hacking'' can lead to the shaping reward being optimized at the expense of the extrinsic reward, resulting in a suboptimal policy. Potential-Based Reward Shaping (PBRS) techniques such as Generalized Reward Matching (GRM) and Policy-Invariant Explicit Shaping (PIES) have mitigated this. These methods allow for implementing IM without altering optimal policies. In this work we show that they are effectively unsuitable for complex, exploration-heavy environments with long-duration episodes. To remedy this, we introduce Action-Dependent Optimality Preserving Shaping (ADOPS), a method of converting intrinsic rewards to an optimality-preserving form that allows agents to utilize IM more effectively in the extremely sparse environment of Montezuma's Revenge. We also prove ADOPS accommodates reward shaping functions that cannot be written in a potential-based form: while PBRS-based methods require the cumulative discounted intrinsic return be independent of actions, ADOPS allows for intrinsic cumulative returns to be dependent on agents' actions while still preserving the optimal policy set. We show how action-dependence enables ADOPS's to preserve optimality while learning in complex, sparse-reward environments where other methods struggle.
Autonomous Curriculum Design via Relative Entropy Based Task Modifications
Feb 28, 2025Curriculum learning is a training method in which an agent is first trained on a curriculum of relatively simple tasks related to a target task in an effort to shorten the time required to train on the target task. Autonomous curriculum design involves the design of such curriculum with no reliance on human knowledge and/or expertise. Finding an efficient and effective way of autonomously designing curricula remains an open problem. We propose a novel approach for automatically designing curricula by leveraging the learner's uncertainty to select curricula tasks. Our approach measures the uncertainty in the learner's policy using relative entropy, and guides the agent to states of high uncertainty to facilitate learning. Our algorithm supports the generation of autonomous curricula in a self-assessed manner by leveraging the learner's past and current policies but it also allows the use of teacher guided design in an instructive setting. We provide theoretical guarantees for the convergence of our algorithm using two time-scale optimization processes. Results show that our algorithm outperforms randomly generated curriculum, and learning directly on the target task as well as the curriculum-learning criteria existing in literature. We also present two additional heuristic distance measures that could be combined with our relative-entropy approach for further performance improvements.
Reducing Reward Dependence in RL Through Adaptive Confidence Discounting
Feb 28, 2025In human-in-the-loop reinforcement learning or environments where calculating a reward is expensive, the costly rewards can make learning efficiency challenging to achieve. The cost of obtaining feedback from humans or calculating expensive rewards means algorithms receiving feedback at every step of long training sessions may be infeasible, which may limit agents' abilities to efficiently improve performance. Our aim is to reduce the reliance of learning agents on humans or expensive rewards, improving the efficiency of learning while maintaining the quality of the learned policy. We offer a novel reinforcement learning algorithm that requests a reward only when its knowledge of the value of actions in an environment state is low. Our approach uses a reward function model as a proxy for human-delivered or expensive rewards when confidence is high, and asks for those explicit rewards only when there is low confidence in the model's predicted rewards and/or action selection. By reducing dependence on the expensive-to-obtain rewards, we are able to learn efficiently in settings where the logistics or expense of obtaining rewards may otherwise prohibit it. In our experiments our approach obtains comparable performance to a baseline in terms of return and number of episodes required to learn, but achieves that performance with as few as 20% of the rewards.
Potential-Based Intrinsic Motivation: Preserving Optimality With Complex, Non-Markovian Shaping Rewards
Oct 16, 2024



Recently there has been a proliferation of intrinsic motivation (IM) reward-shaping methods to learn in complex and sparse-reward environments. These methods can often inadvertently change the set of optimal policies in an environment, leading to suboptimal behavior. Previous work on mitigating the risks of reward shaping, particularly through potential-based reward shaping (PBRS), has not been applicable to many IM methods, as they are often complex, trainable functions themselves, and therefore dependent on a wider set of variables than the traditional reward functions that PBRS was developed for. We present an extension to PBRS that we prove preserves the set of optimal policies under a more general set of functions than has been previously proven. We also present {\em Potential-Based Intrinsic Motivation} (PBIM) and {\em Generalized Reward Matching} (GRM), methods for converting IM rewards into a potential-based form that are useable without altering the set of optimal policies. Testing in the MiniGrid DoorKey and Cliff Walking environments, we demonstrate that PBIM and GRM successfully prevent the agent from converging to a suboptimal policy and can speed up training. Additionally, we prove that GRM is sufficiently general as to encompass all potential-based reward shaping functions. This paper expands on previous work introducing the PBIM method, and provides an extension to the more general method of GRM, as well as additional proofs, experimental results, and discussion.
Potential-Based Reward Shaping For Intrinsic Motivation
Feb 12, 2024

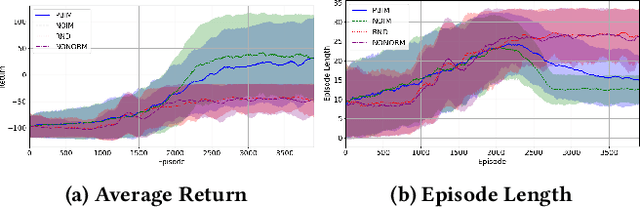

Recently there has been a proliferation of intrinsic motivation (IM) reward-shaping methods to learn in complex and sparse-reward environments. These methods can often inadvertently change the set of optimal policies in an environment, leading to suboptimal behavior. Previous work on mitigating the risks of reward shaping, particularly through potential-based reward shaping (PBRS), has not been applicable to many IM methods, as they are often complex, trainable functions themselves, and therefore dependent on a wider set of variables than the traditional reward functions that PBRS was developed for. We present an extension to PBRS that we prove preserves the set of optimal policies under a more general set of functions than has been previously proven. We also present {\em Potential-Based Intrinsic Motivation} (PBIM), a method for converting IM rewards into a potential-based form that is useable without altering the set of optimal policies. Testing in the MiniGrid DoorKey and Cliff Walking environments, we demonstrate that PBIM successfully prevents the agent from converging to a suboptimal policy and can speed up training.
Interactive Learning of Environment Dynamics for Sequential Tasks
Jul 19, 2019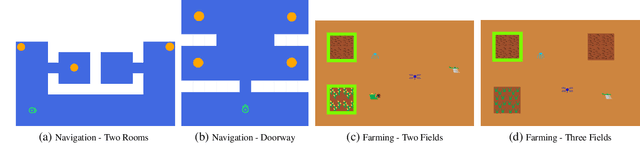
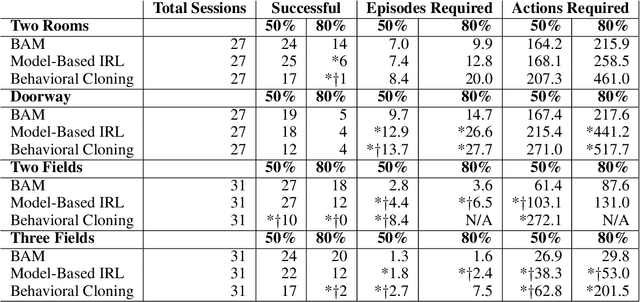
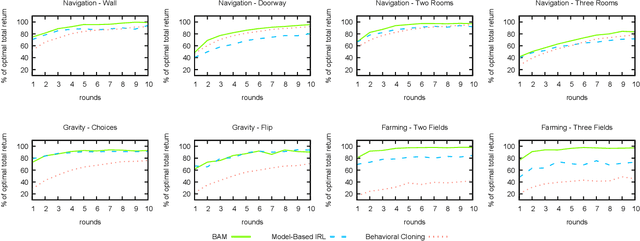
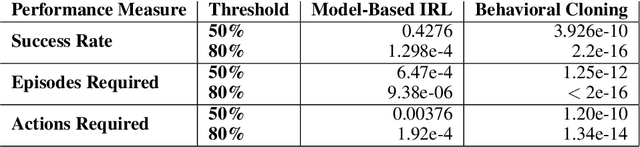
In order for robots and other artificial agents to efficiently learn to perform useful tasks defined by an end user, they must understand not only the goals of those tasks, but also the structure and dynamics of that user's environment. While existing work has looked at how the goals of a task can be inferred from a human teacher, the agent is often left to learn about the environment on its own. To address this limitation, we develop an algorithm, Behavior Aware Modeling (BAM), which incorporates a teacher's knowledge into a model of the transition dynamics of an agent's environment. We evaluate BAM both in simulation and with real human teachers, learning from a combination of task demonstrations and evaluative feedback, and show that it can outperform approaches which do not explicitly consider this source of dynamics knowledge.