 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Formal Theory of the Need for Competence via Computational Intrinsic Motivation
Feb 11, 2025
Computational models offer powerful tools for formalising psychological theories, making them both testable and applicable in digital contexts. However, they remain little used in the study of motivation within psychology. We focus on the "need for competence", postulated as a key basic human need within Self-Determination Theory (SDT) -- arguably the most influential psychological framework for studying intrinsic motivation (IM). The need for competence is treated as a single construct across SDT texts. Yet, recent research has identified multiple, ambiguously defined facets of competence in SDT. We propose that these inconsistencies may be alleviated by drawing on computational models from the field of artificial intelligence, specifically from the domain of reinforcement learning (RL). By aligning the aforementioned facets of competence -- effectance, skill use, task performance, and capacity growth -- with existing RL formalisms, we provide a foundation for advancing competence-related theory in SDT and motivational psychology more broadly. The formalisms reveal underlying preconditions that SDT fails to make explicit, demonstrating how computational models can improve our understanding of IM. Additionally, our work can support a cycle of theory development by inspiring new computational models formalising aspects of the theory, which can then be tested empirically to refine the theory. While our research lays a promising foundation, empirical studies of these models in both humans and machines are needed, inviting collaboration across disciplines.
Diversity Progress for Goal Selection in Discriminability-Motivated RL
Nov 03, 2024Non-uniform goal selection has the potential to improve the reinforcement learning (RL) of skills over uniform-random selection. In this paper, we introduce a method for learning a goal-selection policy in intrinsically-motivated goal-conditioned RL: "Diversity Progress" (DP). The learner forms a curriculum based on observed improvement in discriminability over its set of goals. Our proposed method is applicable to the class of discriminability-motivated agents, where the intrinsic reward is computed as a function of the agent's certainty of following the true goal being pursued. This reward can motivate the agent to learn a set of diverse skills without extrinsic rewards. We demonstrate empirically that a DP-motivated agent can learn a set of distinguishable skills faster than previous approaches, and do so without suffering from a collapse of the goal distribution -- a known issue with some prior approaches. We end with plans to take this proof-of-concept forward.
Creativity and Markov Decision Processes
May 23, 2024

Creativity is already regularly attributed to AI systems outside specialised computational creativity (CC) communities. However, the evaluation of creativity in AI at large typically lacks grounding in creativity theory, which can promote inappropriate attributions and limit the analysis of creative behaviour. While CC researchers have translated psychological theory into formal models, the value of these models is limited by a gap to common AI frameworks. To mitigate this limitation, we identify formal mappings between Boden's process theory of creativity and Markov Decision Processes (MDPs), using the Creative Systems Framework as a stepping stone. We study three out of eleven mappings in detail to understand which types of creative processes, opportunities for (aberrations), and threats to creativity (uninspiration) could be observed in an MDP. We conclude by discussing quality criteria for the selection of such mappings for future work and applications.
Interdisciplinary Methods in Computational Creativity: How Human Variables Shape Human-Inspired AI Research
Jun 29, 2023The word creativity originally described a concept from human psychology, but in the realm of computational creativity (CC), it has become much more. The question of what creativity means when it is part of a computational system might be considered core to CC. Pinning down the meaning of creativity, and concepts like it, becomes salient when researchers port concepts from human psychology to computation, a widespread practice extending beyond CC into artificial intelligence (AI). Yet, the human processes shaping human-inspired computational systems have been little investigated. In this paper, we question which human literatures (social sciences, psychology, neuroscience) enter AI scholarship and how they are translated at the port of entry. This study is based on 22 in-depth, semi-structured interviews, primarily with human-inspired AI researchers, half of whom focus on creativity as a major research area. This paper focuses on findings most relevant to CC. We suggest that which human literature enters AI bears greater scrutiny because ideas may become disconnected from context in their home discipline. Accordingly, we recommend that CC researchers document the decisions and context of their practices, particularly those practices formalizing human concepts for machines. Publishing reflexive commentary on human elements in CC and AI would provide a useful record and permit greater dialogue with other disciplines.
Five Properties of Specific Curiosity You Didn't Know Curious Machines Should Have
Dec 01, 2022Curiosity for machine agents has been a focus of lively research activity. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we conduct a comprehensive, multidisciplinary survey of the field of animal and machine curiosity. As a principal contribution of this work, we use this survey as a foundation to introduce and define what we consider to be five of the most important properties of specific curiosity: 1) directedness towards inostensible referents, 2) cessation when satisfied, 3) voluntary exposure, 4) transience, and 5) coherent long-term learning. As a second main contribution of this work, we show how these properties may be implemented together in a proof-of-concept reinforcement learning agent: we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, our example of a computational specific curiosity agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work, therefore, presents a landmark synthesis and translation of specific curiosity to the domain of machine learning and reinforcement learning and provides a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making computational agents in complex environments.
Prototyping three key properties of specific curiosity in computational reinforcement learning
May 20, 2022

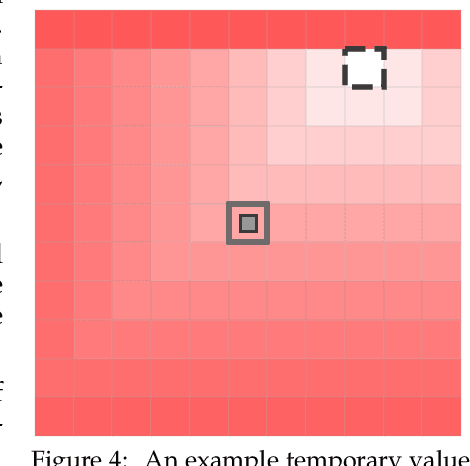
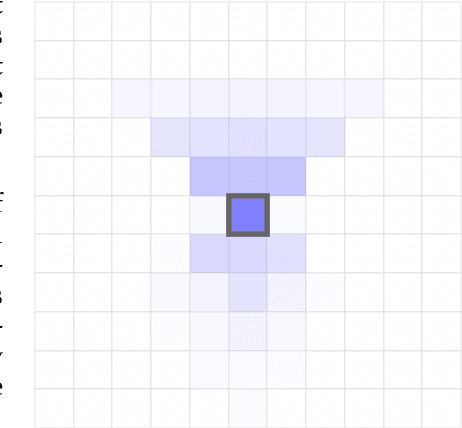
Curiosity for machine agents has been a focus of intense research. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we introduce three of the most immediate of these properties -- directedness, cessation when satisfied, and voluntary exposure -- and show how they may be implemented together in a proof-of-concept reinforcement learning agent; further, we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, the agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work therefore presents a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making agents in complex environments.
Examining the Use of Temporal-Difference Incremental Delta-Bar-Delta for Real-World Predictive Knowledge Architectures
Aug 15, 2019
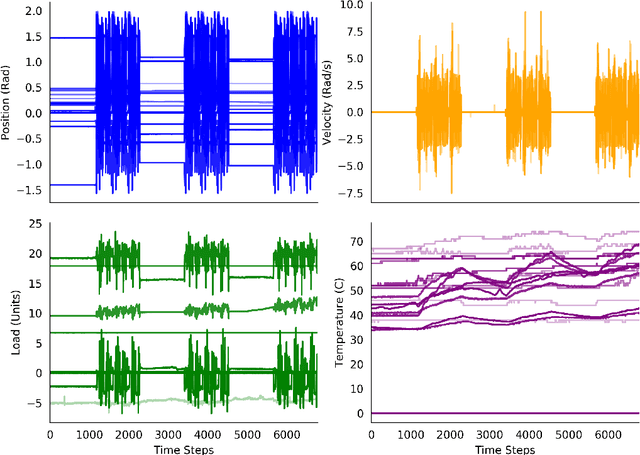


Predictions and predictive knowledge have seen recent success in improving not only robot control but also other applications ranging from industrial process control to rehabilitation. A property that makes these predictive approaches well suited for robotics is that they can be learned online and incrementally through interaction with the environment. However, a remaining challenge for many prediction-learning approaches is an appropriate choice of prediction-learning parameters, especially parameters that control the magnitude of a learning machine's updates to its predictions (the learning rate or step size). To begin to address this challenge, we examine the use of online step-size adaptation using a sensor-rich robotic arm. Our method of choice, Temporal-Difference Incremental Delta-Bar-Delta (TIDBD), learns and adapts step sizes on a feature level; importantly, TIDBD allows step-size tuning and representation learning to occur at the same time. We show that TIDBD is a practical alternative for classic Temporal-Difference (TD) learning via an extensive parameter search. Both approaches perform comparably in terms of predicting future aspects of a robotic data stream. Furthermore, the use of a step-size adaptation method like TIDBD appears to allow a system to automatically detect and characterize common sensor failures in a robotic application. Together, these results promise to improve the ability of robotic devices to learn from interactions with their environments in a robust way, providing key capabilities for autonomous agents and robots.
Adapting Behaviour via Intrinsic Reward: A Survey and Empirical Study
Jun 19, 2019



Learning about many things can provide numerous benefits to a reinforcement learning system. For example, learning many auxiliary value functions, in addition to optimizing the environmental reward, appears to improve both exploration and representation learning. The question we tackle in this paper is how to sculpt the stream of experience---how to adapt the system's behaviour---to optimize the learning of a collection of value functions. A simple answer is to compute an intrinsic reward based on the statistics of each auxiliary learner, and use reinforcement learning to maximize that intrinsic reward. Unfortunately, implementing this simple idea has proven difficult, and thus has been the focus of decades of study. It remains unclear which of the many possible measures of learning would work well in a parallel learning setting where environmental reward is extremely sparse or absent. In this paper, we investigate and compare different intrinsic reward mechanisms in a new bandit-like parallel-learning testbed. We discuss the interaction between reward and prediction learners and highlight the importance of introspective prediction learners: those that increase their rate of learning when progress is possible, and decrease when it is not. We provide a comprehensive empirical comparison of 15 different rewards, including well-known ideas from reinforcement learning and active learning. Our results highlight a simple but seemingly powerful principle: intrinsic rewards based on the amount of learning can generate useful behaviour, if each individual learner is introspective.