 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Formal Theory of the Need for Competence via Computational Intrinsic Motivation
Feb 11, 2025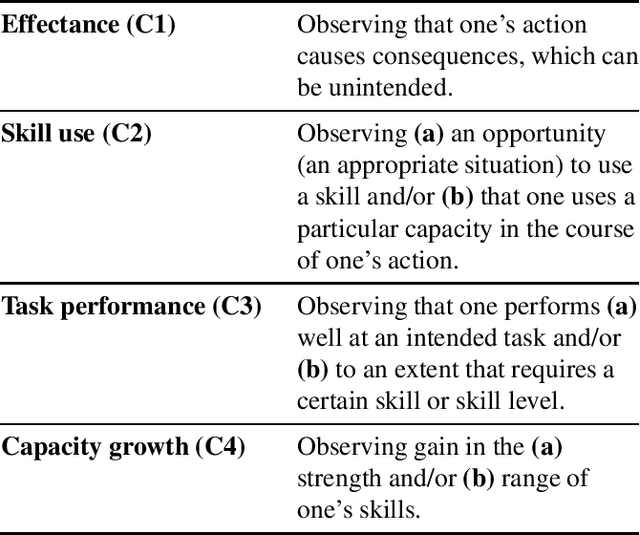
Computational models offer powerful tools for formalising psychological theories, making them both testable and applicable in digital contexts. However, they remain little used in the study of motivation within psychology. We focus on the "need for competence", postulated as a key basic human need within Self-Determination Theory (SDT) -- arguably the most influential psychological framework for studying intrinsic motivation (IM). The need for competence is treated as a single construct across SDT texts. Yet, recent research has identified multiple, ambiguously defined facets of competence in SDT. We propose that these inconsistencies may be alleviated by drawing on computational models from the field of artificial intelligence, specifically from the domain of reinforcement learning (RL). By aligning the aforementioned facets of competence -- effectance, skill use, task performance, and capacity growth -- with existing RL formalisms, we provide a foundation for advancing competence-related theory in SDT and motivational psychology more broadly. The formalisms reveal underlying preconditions that SDT fails to make explicit, demonstrating how computational models can improve our understanding of IM. Additionally, our work can support a cycle of theory development by inspiring new computational models formalising aspects of the theory, which can then be tested empirically to refine the theory. While our research lays a promising foundation, empirical studies of these models in both humans and machines are needed, inviting collaboration across disciplines.
Diversity Progress for Goal Selection in Discriminability-Motivated RL
Nov 03, 2024Non-uniform goal selection has the potential to improve the reinforcement learning (RL) of skills over uniform-random selection. In this paper, we introduce a method for learning a goal-selection policy in intrinsically-motivated goal-conditioned RL: "Diversity Progress" (DP). The learner forms a curriculum based on observed improvement in discriminability over its set of goals. Our proposed method is applicable to the class of discriminability-motivated agents, where the intrinsic reward is computed as a function of the agent's certainty of following the true goal being pursued. This reward can motivate the agent to learn a set of diverse skills without extrinsic rewards. We demonstrate empirically that a DP-motivated agent can learn a set of distinguishable skills faster than previous approaches, and do so without suffering from a collapse of the goal distribution -- a known issue with some prior approaches. We end with plans to take this proof-of-concept forward.