 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFive Properties of Specific Curiosity You Didn't Know Curious Machines Should Have
Dec 01, 2022Curiosity for machine agents has been a focus of lively research activity. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we conduct a comprehensive, multidisciplinary survey of the field of animal and machine curiosity. As a principal contribution of this work, we use this survey as a foundation to introduce and define what we consider to be five of the most important properties of specific curiosity: 1) directedness towards inostensible referents, 2) cessation when satisfied, 3) voluntary exposure, 4) transience, and 5) coherent long-term learning. As a second main contribution of this work, we show how these properties may be implemented together in a proof-of-concept reinforcement learning agent: we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, our example of a computational specific curiosity agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work, therefore, presents a landmark synthesis and translation of specific curiosity to the domain of machine learning and reinforcement learning and provides a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making computational agents in complex environments.
Prototyping three key properties of specific curiosity in computational reinforcement learning
May 20, 2022

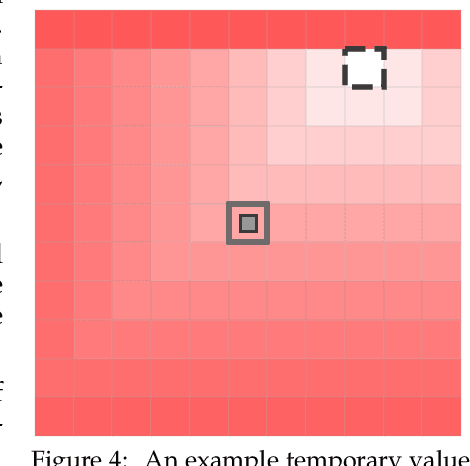
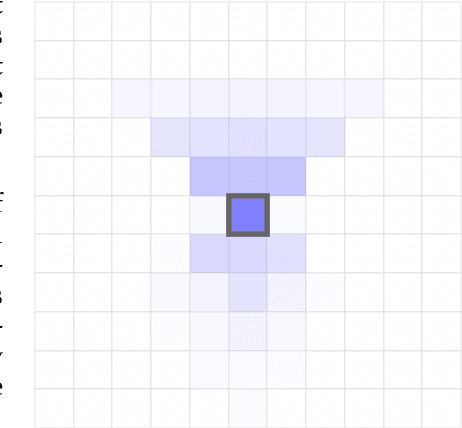
Curiosity for machine agents has been a focus of intense research. The study of human and animal curiosity, particularly specific curiosity, has unearthed several properties that would offer important benefits for machine learners, but that have not yet been well-explored in machine intelligence. In this work, we introduce three of the most immediate of these properties -- directedness, cessation when satisfied, and voluntary exposure -- and show how they may be implemented together in a proof-of-concept reinforcement learning agent; further, we demonstrate how the properties manifest in the behaviour of this agent in a simple non-episodic grid-world environment that includes curiosity-inducing locations and induced targets of curiosity. As we would hope, the agent exhibits short-term directed behaviour while updating long-term preferences to adaptively seek out curiosity-inducing situations. This work therefore presents a novel view into how specific curiosity operates and in the future might be integrated into the behaviour of goal-seeking, decision-making agents in complex environments.
Efficient Planning in Large MDPs with Weak Linear Function Approximation
Jul 13, 2020Large-scale Markov decision processes (MDPs) require planning algorithms with runtime independent of the number of states of the MDP. We consider the planning problem in MDPs using linear value function approximation with only weak requirements: low approximation error for the optimal value function, and a small set of "core" states whose features span those of other states. In particular, we make no assumptions about the representability of policies or value functions of non-optimal policies. Our algorithm produces almost-optimal actions for any state using a generative oracle (simulator) for the MDP, while its computation time scales polynomially with the number of features, core states, and actions and the effective horizon.
Discounted Reinforcement Learning is Not an Optimization Problem
Nov 16, 2019
Discounted reinforcement learning is fundamentally incompatible with function approximation for control in continuing tasks. It is not an optimization problem in its usual formulation, so when using function approximation there is no optimal policy. We substantiate these claims, then go on to address some misconceptions about discounting and its connection to the average reward formulation. We encourage researchers to adopt rigorous optimization approaches, such as maximizing average reward, for reinforcement learning in continuing tasks.
Differentially Private Contextual Linear Bandits
Sep 28, 2018
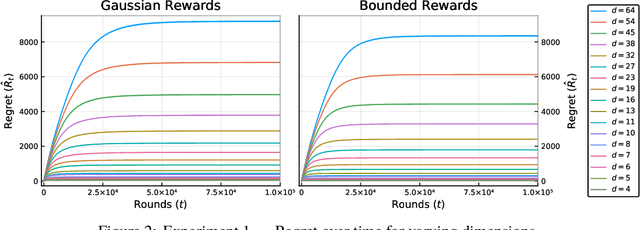
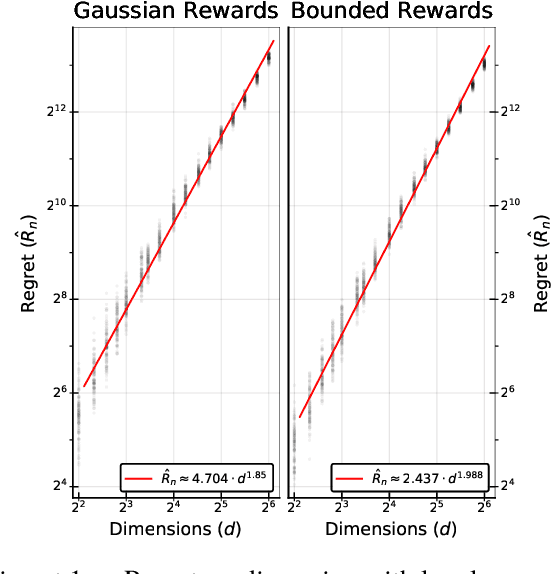
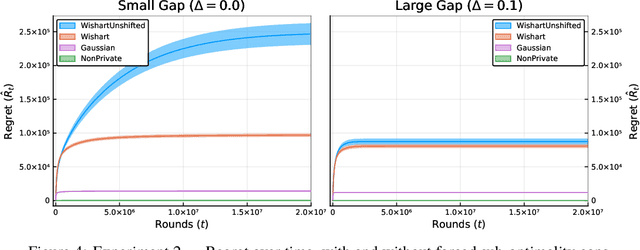
We study the contextual linear bandit problem, a version of the standard stochastic multi-armed bandit (MAB) problem where a learner sequentially selects actions to maximize a reward which depends also on a user provided per-round context. Though the context is chosen arbitrarily or adversarially, the reward is assumed to be a stochastic function of a feature vector that encodes the context and selected action. Our goal is to devise private learners for the contextual linear bandit problem. We first show that using the standard definition of differential privacy results in linear regret. So instead, we adopt the notion of joint differential privacy, where we assume that the action chosen on day $t$ is only revealed to user $t$ and thus needn't be kept private that day, only on following days. We give a general scheme converting the classic linear-UCB algorithm into a joint differentially private algorithm using the tree-based algorithm. We then apply either Gaussian noise or Wishart noise to achieve joint-differentially private algorithms and bound the resulting algorithms' regrets. In addition, we give the first lower bound on the additional regret any private algorithms for the MAB problem must incur.
Conservative Bandits
Feb 13, 2016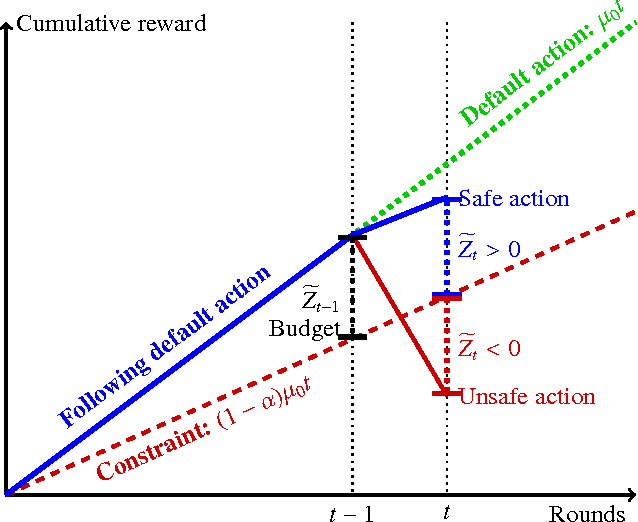


We study a novel multi-armed bandit problem that models the challenge faced by a company wishing to explore new strategies to maximize revenue whilst simultaneously maintaining their revenue above a fixed baseline, uniformly over time. While previous work addressed the problem under the weaker requirement of maintaining the revenue constraint only at a given fixed time in the future, the algorithms previously proposed are unsuitable due to their design under the more stringent constraints. We consider both the stochastic and the adversarial settings, where we propose, natural, yet novel strategies and analyze the price for maintaining the constraints. Amongst other things, we prove both high probability and expectation bounds on the regret, while we also consider both the problem of maintaining the constraints with high probability or expectation. For the adversarial setting the price of maintaining the constraint appears to be higher, at least for the algorithm considered. A lower bound is given showing that the algorithm for the stochastic setting is almost optimal. Empirical results obtained in synthetic environments complement our theoretical findings.