Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscounted Reinforcement Learning is Not an Optimization Problem
Paper and Code
Nov 16, 2019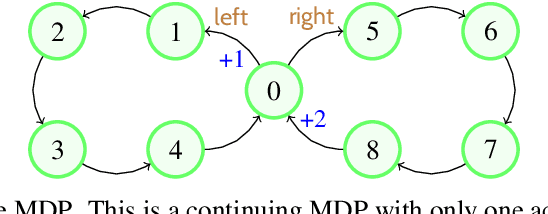
Discounted reinforcement learning is fundamentally incompatible with function approximation for control in continuing tasks. It is not an optimization problem in its usual formulation, so when using function approximation there is no optimal policy. We substantiate these claims, then go on to address some misconceptions about discounting and its connection to the average reward formulation. We encourage researchers to adopt rigorous optimization approaches, such as maximizing average reward, for reinforcement learning in continuing tasks.
* Accepted for presentation at the Optimization Foundations of
Reinforcement Learning Workshop at NeurIPS 2019
View paper on