 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinually Learned Pavlovian Signalling Without Forgetting for Human-in-the-Loop Robotic Control
May 16, 2023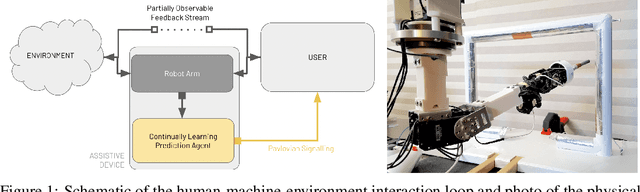
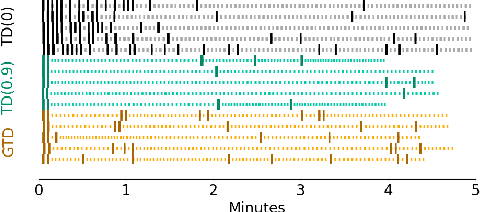
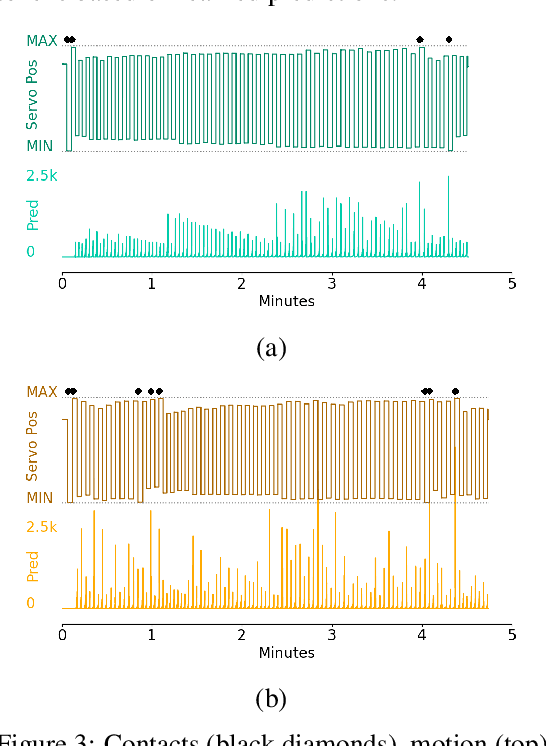
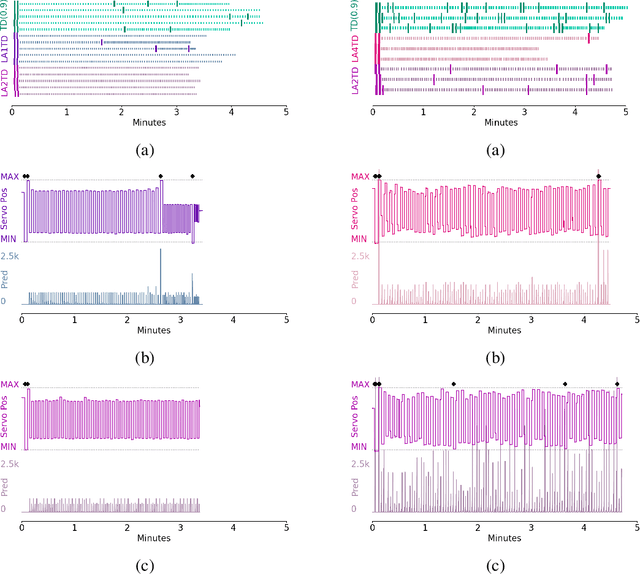
Artificial limbs are sophisticated devices to assist people with tasks of daily living. Despite advanced robotic prostheses demonstrating similar motion capabilities to biological limbs, users report them difficult and non-intuitive to use. Providing more effective feedback from the device to the user has therefore become a topic of increased interest. In particular, prediction learning methods from the field of reinforcement learning -- specifically, an approach termed Pavlovian signalling -- have been proposed as one approach for better modulating feedback in prostheses since they can adapt during continuous use. One challenge identified in these learning methods is that they can forget previously learned predictions when a user begins to successfully act upon delivered feedback. The present work directly addresses this challenge, contributing new evidence on the impact of algorithmic choices, such as on- or off-policy methods and representation choices, on the Pavlovian signalling from a machine to a user during their control of a robotic arm. Two conditions of algorithmic differences were studied using different scenarios of controlling a robotic arm: an automated motion system and human participant piloting. Contrary to expectations, off-policy learning did not provide the expected solution to the forgetting problem. We instead identified beneficial properties of a look-ahead state representation that made existing approaches able to learn (and not forget) predictions in support of Pavlovian signalling. This work therefore contributes new insight into the challenges of providing learned predictive feedback from a prosthetic device, and demonstrates avenues for more dynamic signalling in future human-machine interactions.
Joint Action is a Framework for Understanding Partnerships Between Humans and Upper Limb Prostheses
Dec 28, 2022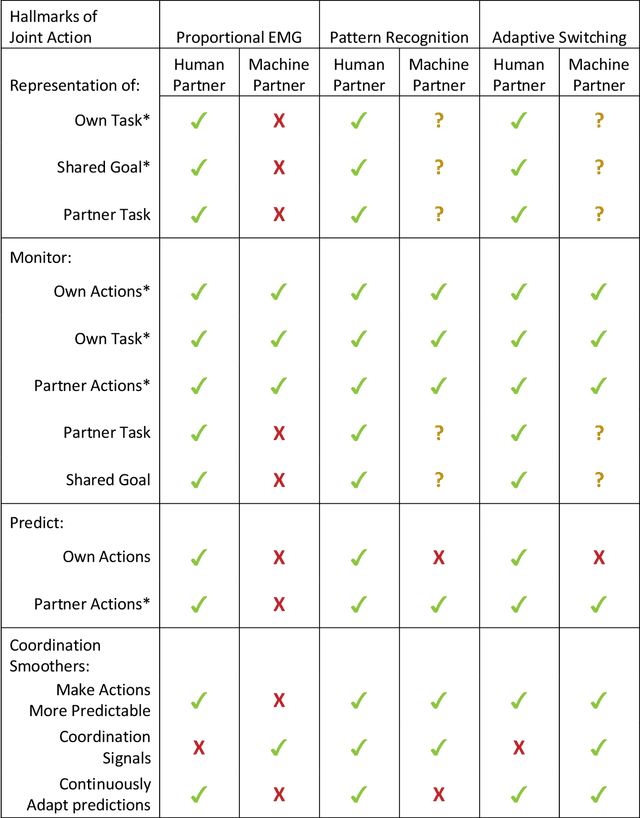
Recent advances in upper limb prostheses have led to significant improvements in the number of movements provided by the robotic limb. However, the method for controlling multiple degrees of freedom via user-generated signals remains challenging. To address this issue, various machine learning controllers have been developed to better predict movement intent. As these controllers become more intelligent and take on more autonomy in the system, the traditional approach of representing the human-machine interface as a human controlling a tool becomes limiting. One possible approach to improve the understanding of these interfaces is to model them as collaborative, multi-agent systems through the lens of joint action. The field of joint action has been commonly applied to two human partners who are trying to work jointly together to achieve a task, such as singing or moving a table together, by effecting coordinated change in their shared environment. In this work, we compare different prosthesis controllers (proportional electromyography with sequential switching, pattern recognition, and adaptive switching) in terms of how they present the hallmarks of joint action. The results of the comparison lead to a new perspective for understanding how existing myoelectric systems relate to each other, along with recommendations for how to improve these systems by increasing the collaborative communication between each partner.
Examining the Use of Temporal-Difference Incremental Delta-Bar-Delta for Real-World Predictive Knowledge Architectures
Aug 15, 2019
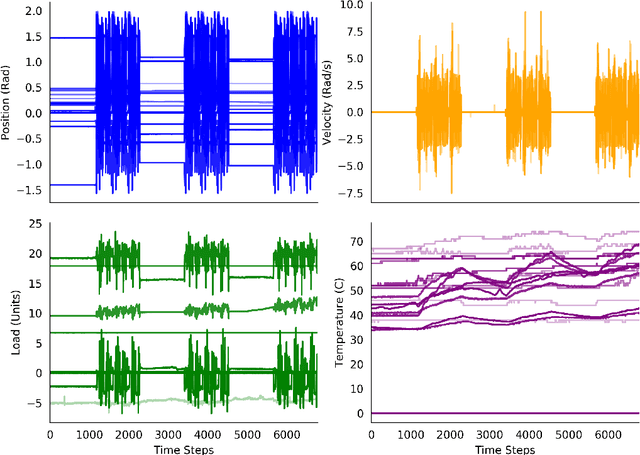


Predictions and predictive knowledge have seen recent success in improving not only robot control but also other applications ranging from industrial process control to rehabilitation. A property that makes these predictive approaches well suited for robotics is that they can be learned online and incrementally through interaction with the environment. However, a remaining challenge for many prediction-learning approaches is an appropriate choice of prediction-learning parameters, especially parameters that control the magnitude of a learning machine's updates to its predictions (the learning rate or step size). To begin to address this challenge, we examine the use of online step-size adaptation using a sensor-rich robotic arm. Our method of choice, Temporal-Difference Incremental Delta-Bar-Delta (TIDBD), learns and adapts step sizes on a feature level; importantly, TIDBD allows step-size tuning and representation learning to occur at the same time. We show that TIDBD is a practical alternative for classic Temporal-Difference (TD) learning via an extensive parameter search. Both approaches perform comparably in terms of predicting future aspects of a robotic data stream. Furthermore, the use of a step-size adaptation method like TIDBD appears to allow a system to automatically detect and characterize common sensor failures in a robotic application. Together, these results promise to improve the ability of robotic devices to learn from interactions with their environments in a robust way, providing key capabilities for autonomous agents and robots.