 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's a Good Prediction? Issues in Evaluating General Value Functions Through Error
Paper and Code
Jan 23, 2020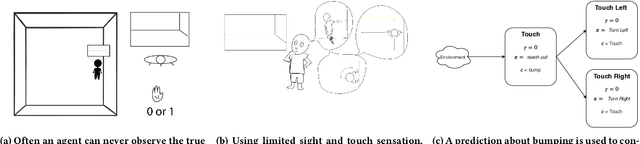
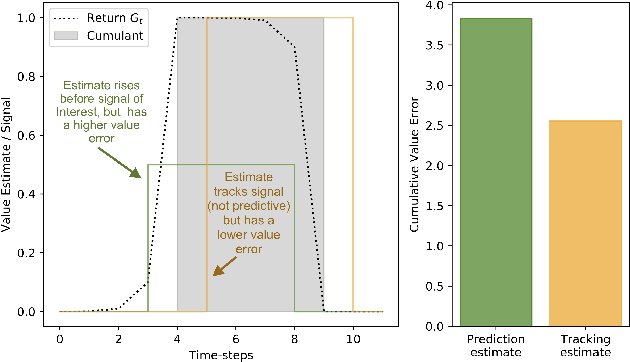
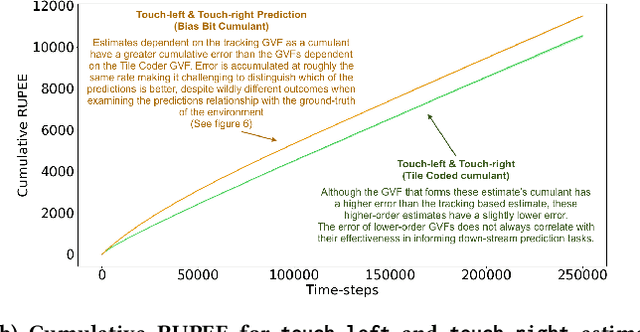

Constructing and maintaining knowledge of the world is a central problem for artificial intelligence research. Approaches to constructing an agent's knowledge using predictions have received increased amounts of interest in recent years. A particularly promising collection of research centres itself around architectures that formulate predictions as General Value Functions (GVFs), an approach commonly referred to as \textit{predictive knowledge}. A pernicious challenge for predictive knowledge architectures is determining what to predict. In this paper, we argue that evaluation methods---i.e., return error and RUPEE---are not well suited for the challenges of determining what to predict. As a primary contribution, we provide extended examples that evaluate predictions in terms of how they are used in further prediction tasks: a key motivation of predictive knowledge systems. We demonstrate that simply because a GVF's error is low, it does not necessarily follow the prediction is useful as a cumulant. We suggest evaluating 1) the relevance of a GVF's features to the prediction task at hand, and 2) evaluation of GVFs by \textit{how} they are used. To determine feature relevance, we generalize AutoStep to GTD, producing a step-size learning method suited to the life-long continual learning settings that predictive knowledge architectures are commonly deployed in. This paper contributes a first look into evaluation of predictions through their use, an integral component of predictive knowledge which is as of yet explored.