 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDBD: Adapting Temporal-difference Step-sizes Through Stochastic Meta-descent
Apr 10, 2018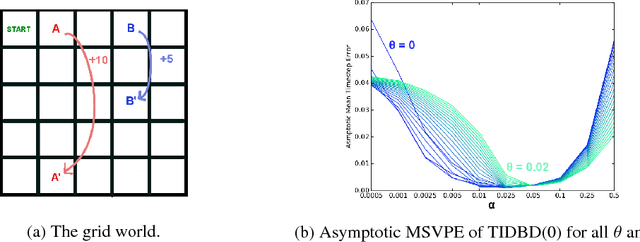
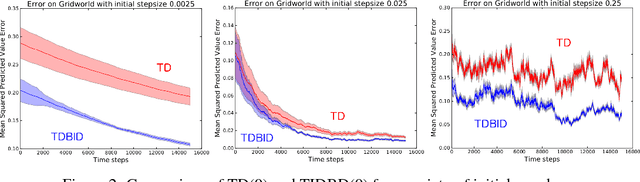
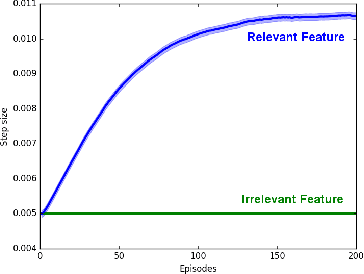
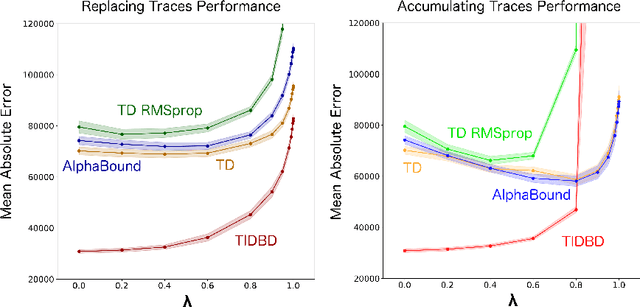
In this paper, we introduce a method for adapting the step-sizes of temporal difference (TD) learning. The performance of TD methods often depends on well chosen step-sizes, yet few algorithms have been developed for setting the step-size automatically for TD learning. An important limitation of current methods is that they adapt a single step-size shared by all the weights of the learning system. A vector step-size enables greater optimization by specifying parameters on a per-feature basis. Furthermore, adapting parameters at different rates has the added benefit of being a simple form of representation learning. We generalize Incremental Delta Bar Delta (IDBD)---a vectorized adaptive step-size method for supervised learning---to TD learning, which we name TIDBD. We demonstrate that TIDBD is able to find appropriate step-sizes in both stationary and non-stationary prediction tasks, outperforming ordinary TD methods and TD methods with scalar step-size adaptation; we demonstrate that it can differentiate between features which are relevant and irrelevant for a given task, performing representation learning; and we show on a real-world robot prediction task that TIDBD is able to outperform ordinary TD methods and TD methods augmented with AlphaBound and RMSprop.
Reactive Reinforcement Learning in Asynchronous Environments
Feb 16, 2018
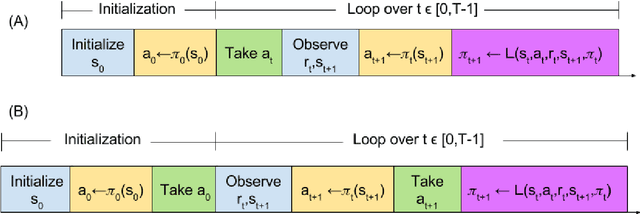

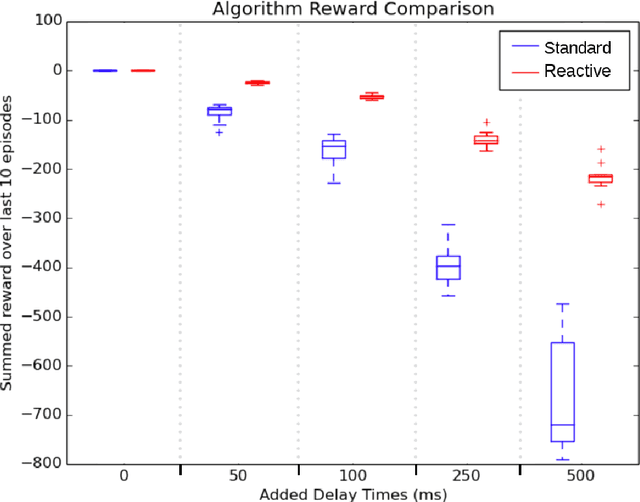
The relationship between a reinforcement learning (RL) agent and an asynchronous environment is often ignored. Frequently used models of the interaction between an agent and its environment, such as Markov Decision Processes (MDP) or Semi-Markov Decision Processes (SMDP), do not capture the fact that, in an asynchronous environment, the state of the environment may change during computation performed by the agent. In an asynchronous environment, minimizing reaction time---the time it takes for an agent to react to an observation---also minimizes the time in which the state of the environment may change following observation. In many environments, the reaction time of an agent directly impacts task performance by permitting the environment to transition into either an undesirable terminal state or a state where performing the chosen action is inappropriate. We propose a class of reactive reinforcement learning algorithms that address this problem of asynchronous environments by immediately acting after observing new state information. We compare a reactive SARSA learning algorithm with the conventional SARSA learning algorithm on two asynchronous robotic tasks (emergency stopping and impact prevention), and show that the reactive RL algorithm reduces the reaction time of the agent by approximately the duration of the algorithm's learning update. This new class of reactive algorithms may facilitate safer control and faster decision making without any change to standard learning guarantees.