 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reasoning with Multi-scale Context for Salient Object Detection
Paper and Code
Jan 24, 2019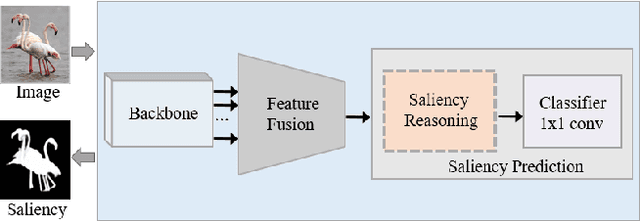

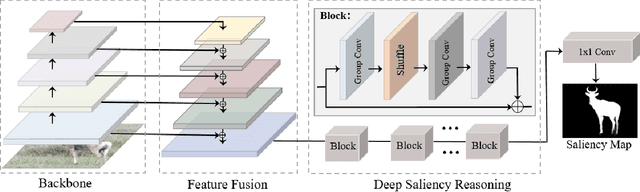

To detect and segment salient objects accurately, existing methods are usually devoted to designing complex network architectures to fuse powerful features from the backbone networks. However, they put much less efforts on the saliency inference module and only use a few fully convolutional layers to perform saliency reasoning from the fused features. However, should feature fusion strategies receive much attention but saliency reasoning be ignored a lot? In this paper, we find that weakness of the saliency reasoning unit limits salient object detection performance, and claim that saliency reasoning after multi-scale convolutional features fusion is critical. To verify our findings, we first extract multi-scale features with a fully convolutional network, and then directly reason from these comprehensive features using a deep yet light-weighted network, modified from ShuffleNet, to fast and precisely predict salient objects. Such simple design is shown to be capable of reasoning from multi-scale saliency features as well as giving superior saliency detection performance with less computation cost. Experimental results show that our simple framework outperforms the best existing method with 2.3\% and 3.6\% promotion for F-measure scores, 2.8\% reduction for MAE score on PASCAL-S, DUT-OMRON and SOD datasets respectively.