 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spatial Understanding in Image Generation via Reward Modeling
Feb 27, 2026Recent progress in text-to-image generation has greatly advanced visual fidelity and creativity, but it has also imposed higher demands on prompt complexity-particularly in encoding intricate spatial relationships. In such cases, achieving satisfactory results often requires multiple sampling attempts. To address this challenge, we introduce a novel method that strengthens the spatial understanding of current image generation models. We first construct the SpatialReward-Dataset with over 80k preference pairs. Building on this dataset, we build SpatialScore, a reward model designed to evaluate the accuracy of spatial relationships in text-to-image generation, achieving performance that even surpasses leading proprietary models on spatial evaluation. We further demonstrate that this reward model effectively enables online reinforcement learning for the complex spatial generation. Extensive experiments across multiple benchmarks show that our specialized reward model yields significant and consistent gains in spatial understanding for image generation.
CharaConsist: Fine-Grained Consistent Character Generation
Jul 15, 2025

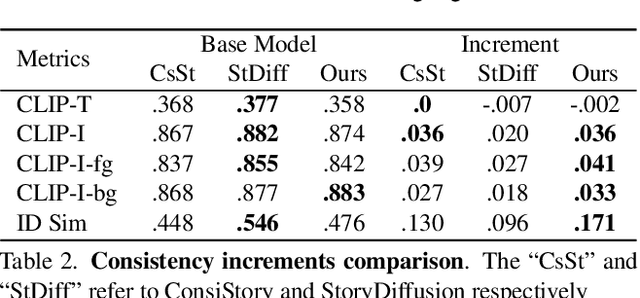

In text-to-image generation, producing a series of consistent contents that preserve the same identity is highly valuable for real-world applications. Although a few works have explored training-free methods to enhance the consistency of generated subjects, we observe that they suffer from the following problems. First, they fail to maintain consistent background details, which limits their applicability. Furthermore, when the foreground character undergoes large motion variations, inconsistencies in identity and clothing details become evident. To address these problems, we propose CharaConsist, which employs point-tracking attention and adaptive token merge along with decoupled control of the foreground and background. CharaConsist enables fine-grained consistency for both foreground and background, supporting the generation of one character in continuous shots within a fixed scene or in discrete shots across different scenes. Moreover, CharaConsist is the first consistent generation method tailored for text-to-image DiT model. Its ability to maintain fine-grained consistency, combined with the larger capacity of latest base model, enables it to produce high-quality visual outputs, broadening its applicability to a wider range of real-world scenarios. The source code has been released at https://github.com/Murray-Wang/CharaConsist
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models
May 29, 2023Public large-scale text-to-image diffusion models, such as Stable Diffusion, have gained significant attention from the community. These models can be easily customized for new concepts using low-rank adaptations (LoRAs). However, the utilization of multiple concept LoRAs to jointly support multiple customized concepts presents a challenge. We refer to this scenario as decentralized multi-concept customization, which involves single-client concept tuning and center-node concept fusion. In this paper, we propose a new framework called Mix-of-Show that addresses the challenges of decentralized multi-concept customization, including concept conflicts resulting from existing single-client LoRA tuning and identity loss during model fusion. Mix-of-Show adopts an embedding-decomposed LoRA (ED-LoRA) for single-client tuning and gradient fusion for the center node to preserve the in-domain essence of single concepts and support theoretically limitless concept fusion. Additionally, we introduce regionally controllable sampling, which extends spatially controllable sampling (e.g., ControlNet and T2I-Adaptor) to address attribute binding and missing object problems in multi-concept sampling. Extensive experiments demonstrate that Mix-of-Show is capable of composing multiple customized concepts with high fidelity, including characters, objects, and scenes.
Distribution-Aware Single-Stage Models for Multi-Person 3D Pose Estimation
Mar 23, 2022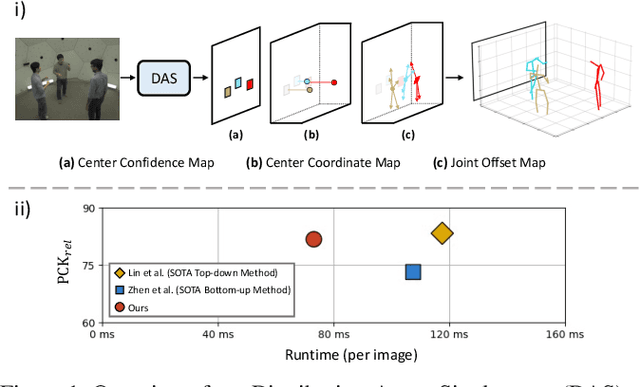

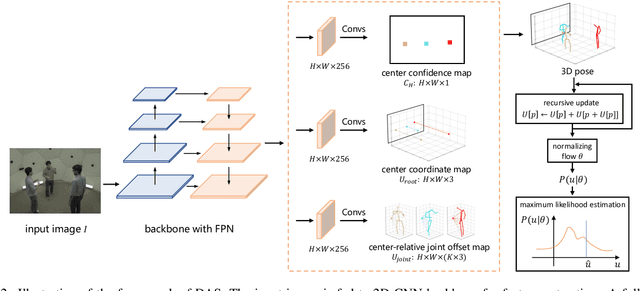
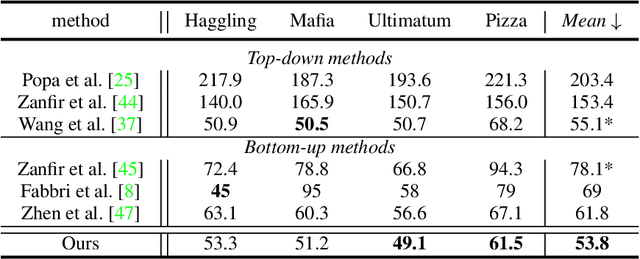
In this paper, we present a novel Distribution-Aware Single-stage (DAS) model for tackling the challenging multi-person 3D pose estimation problem. Different from existing top-down and bottom-up methods, the proposed DAS model simultaneously localizes person positions and their corresponding body joints in the 3D camera space in a one-pass manner. This leads to a simplified pipeline with enhanced efficiency. In addition, DAS learns the true distribution of body joints for the regression of their positions, rather than making a simple Laplacian or Gaussian assumption as previous works. This provides valuable priors for model prediction and thus boosts the regression-based scheme to achieve competitive performance with volumetric-base ones. Moreover, DAS exploits a recursive update strategy for progressively approaching to regression target, alleviating the optimization difficulty and further lifting the regression performance. DAS is implemented with a fully Convolutional Neural Network and end-to-end learnable. Comprehensive experiments on benchmarks CMU Panoptic and MuPoTS-3D demonstrate the superior efficiency of the proposed DAS model, specifically 1.5x speedup over previous best model, and its stat-of-the-art accuracy for multi-person 3D pose estimation.
SODAR: Segmenting Objects by DynamicallyAggregating Neighboring Mask Representations
Feb 15, 2022Recent state-of-the-art one-stage instance segmentation model SOLO divides the input image into a grid and directly predicts per grid cell object masks with fully-convolutional networks, yielding comparably good performance as traditional two-stage Mask R-CNN yet enjoying much simpler architecture and higher efficiency. We observe SOLO generates similar masks for an object at nearby grid cells, and these neighboring predictions can complement each other as some may better segment certain object part, most of which are however directly discarded by non-maximum-suppression. Motivated by the observed gap, we develop a novel learning-based aggregation method that improves upon SOLO by leveraging the rich neighboring information while maintaining the architectural efficiency. The resulting model is named SODAR. Unlike the original per grid cell object masks, SODAR is implicitly supervised to learn mask representations that encode geometric structure of nearby objects and complement adjacent representations with context. The aggregation method further includes two novel designs: 1) a mask interpolation mechanism that enables the model to generate much fewer mask representations by sharing neighboring representations among nearby grid cells, and thus saves computation and memory; 2) a deformable neighbour sampling mechanism that allows the model to adaptively adjust neighbor sampling locations thus gathering mask representations with more relevant context and achieving higher performance. SODAR significantly improves the instance segmentation performance, e.g., it outperforms a SOLO model with ResNet-101 backbone by 2.2 AP on COCO \texttt{test} set, with only about 3\% additional computation. We further show consistent performance gain with the SOLOv2 model.
MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video
Nov 24, 2021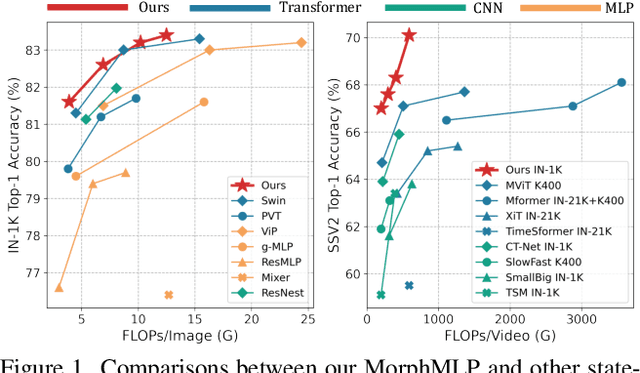
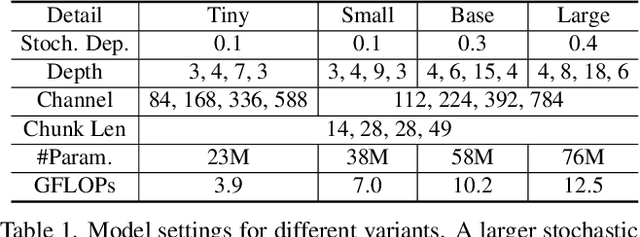
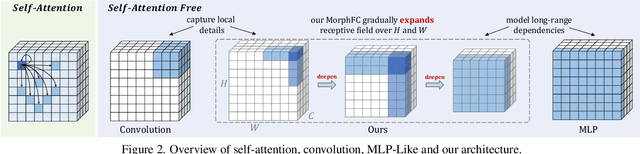
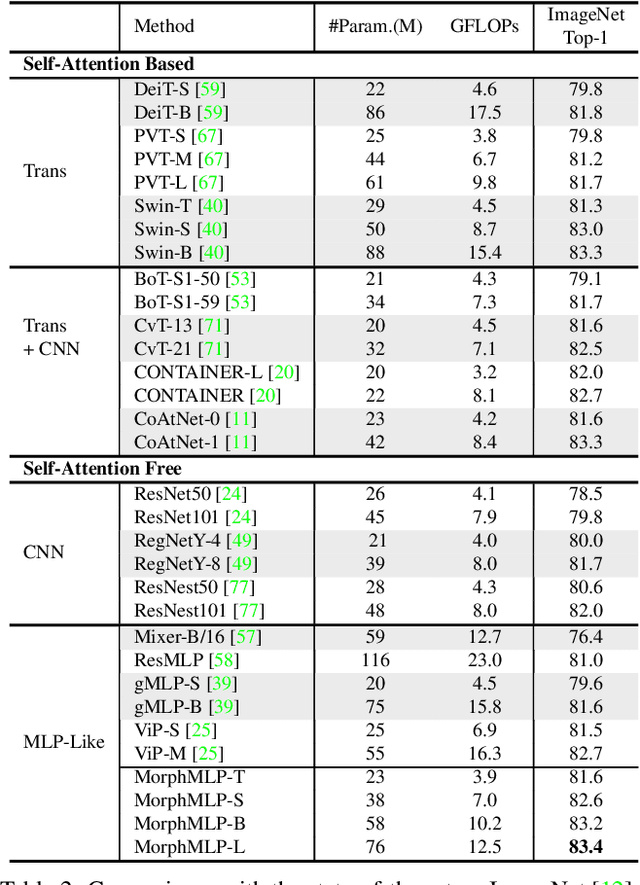
Self-attention has become an integral component of the recent network architectures, e.g., Transformer, that dominate major image and video benchmarks. This is because self-attention can flexibly model long-range information. For the same reason, researchers make attempts recently to revive Multiple Layer Perceptron (MLP) and propose a few MLP-Like architectures, showing great potential. However, the current MLP-Like architectures are not good at capturing local details and lack progressive understanding of core details in the images and/or videos. To overcome this issue, we propose a novel MorphMLP architecture that focuses on capturing local details at the low-level layers, while gradually changing to focus on long-term modeling at the high-level layers. Specifically, we design a Fully-Connected-Like layer, dubbed as MorphFC, of two morphable filters that gradually grow its receptive field along the height and width dimension. More interestingly, we propose to flexibly adapt our MorphFC layer in the video domain. To our best knowledge, we are the first to create a MLP-Like backbone for learning video representation. Finally, we conduct extensive experiments on image classification, semantic segmentation and video classification. Our MorphMLP, such a self-attention free backbone, can be as powerful as and even outperform self-attention based models.
Improved Pillar with Fine-grained Feature for 3D Object Detection
Oct 12, 2021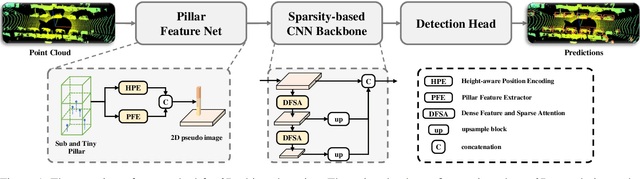
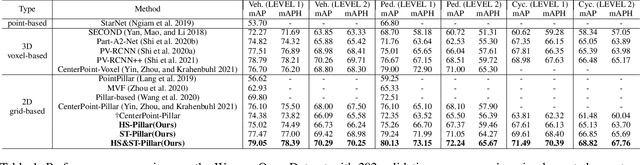
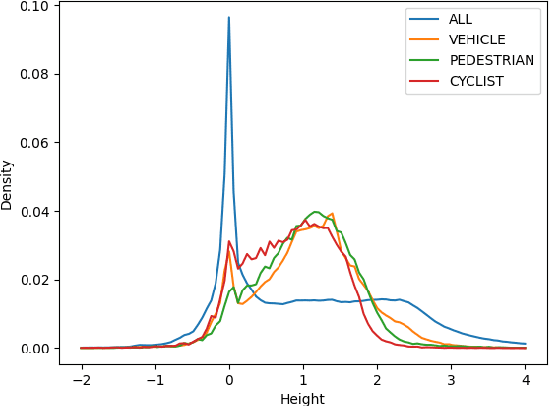
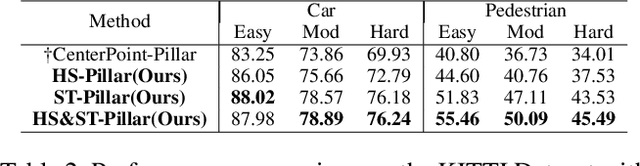
3D object detection with LiDAR point clouds plays an important role in autonomous driving perception module that requires high speed, stability and accuracy. However, the existing point-based methods are challenging to reach the speed requirements because of too many raw points, and the voxel-based methods are unable to ensure stable speed because of the 3D sparse convolution. In contrast, the 2D grid-based methods, such as PointPillar, can easily achieve a stable and efficient speed based on simple 2D convolution, but it is hard to get the competitive accuracy limited by the coarse-grained point clouds representation. So we propose an improved pillar with fine-grained feature based on PointPillar that can significantly improve detection accuracy. It consists of two modules, including height-aware sub-pillar and sparsity-based tiny-pillar, which get fine-grained representation respectively in the vertical and horizontal direction of 3D space. For height-aware sub-pillar, we introduce a height position encoding to keep height information of each sub-pillar during projecting to a 2D pseudo image. For sparsity-based tiny-pillar, we introduce sparsity-based CNN backbone stacked by dense feature and sparse attention module to extract feature with larger receptive field efficiently. Experimental results show that our proposed method significantly outperforms previous state-of-the-art 3D detection methods on the Waymo Open Dataset. The related code will be released to facilitate the academic and industrial study.
Dense Contrastive Visual-Linguistic Pretraining
Sep 24, 2021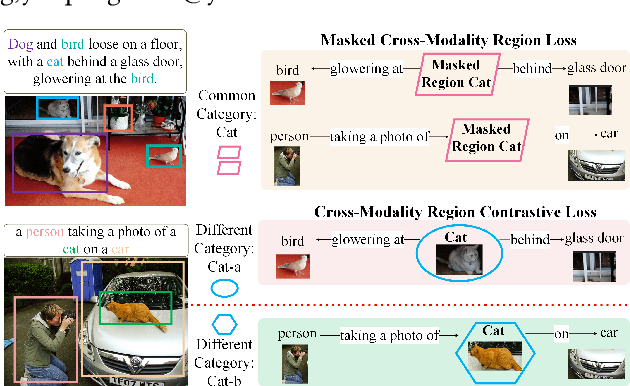

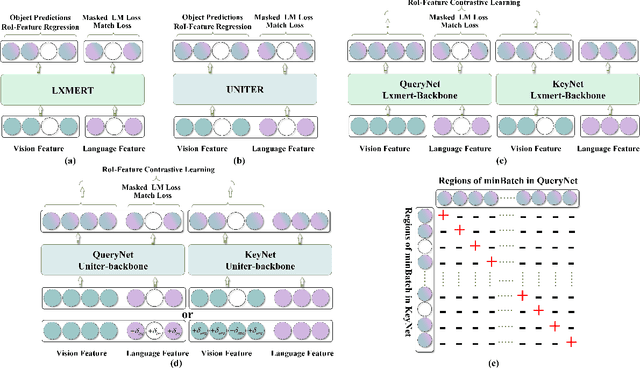
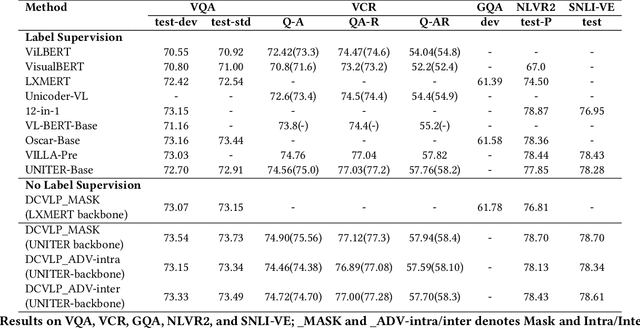
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.
PnP-DETR: Towards Efficient Visual Analysis with Transformers
Sep 16, 2021
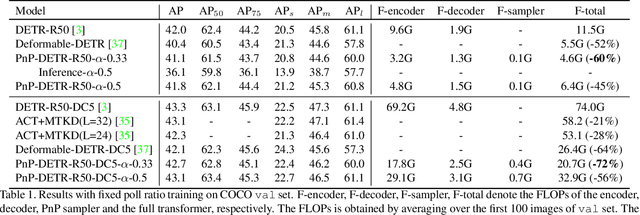
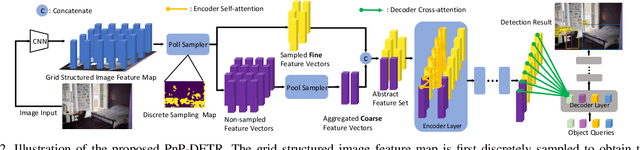

Recently, DETR pioneered the solution of vision tasks with transformers, it directly translates the image feature map into the object detection result. Though effective, translating the full feature map can be costly due to redundant computation on some area like the background. In this work, we encapsulate the idea of reducing spatial redundancy into a novel poll and pool (PnP) sampling module, with which we build an end-to-end PnP-DETR architecture that adaptively allocates its computation spatially to be more efficient. Concretely, the PnP module abstracts the image feature map into fine foreground object feature vectors and a small number of coarse background contextual feature vectors. The transformer models information interaction within the fine-coarse feature space and translates the features into the detection result. Moreover, the PnP-augmented model can instantly achieve various desired trade-offs between performance and computation with a single model by varying the sampled feature length, without requiring to train multiple models as existing methods. Thus it offers greater flexibility for deployment in diverse scenarios with varying computation constraint. We further validate the generalizability of the PnP module on panoptic segmentation and the recent transformer-based image recognition model ViT and show consistent efficiency gain. We believe our method makes a step for efficient visual analysis with transformers, wherein spatial redundancy is commonly observed. Code will be available at \url{https://github.com/twangnh/pnp-detr}.
Continual Learning via Bit-Level Information Preserving
May 10, 2021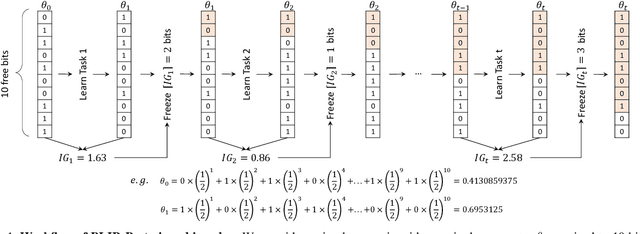
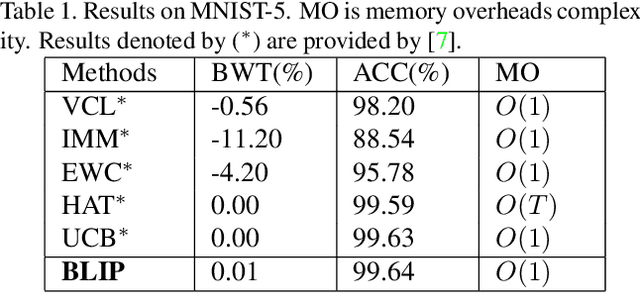
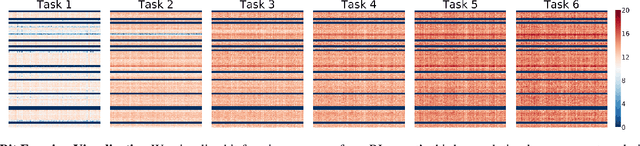
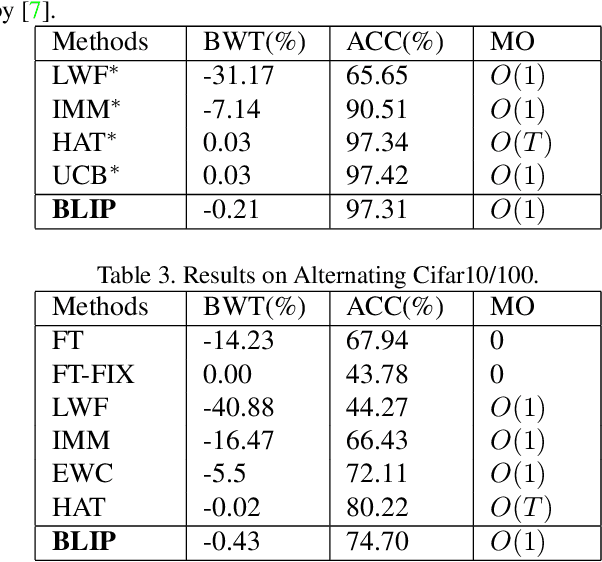
Continual learning tackles the setting of learning different tasks sequentially. Despite the lots of previous solutions, most of them still suffer significant forgetting or expensive memory cost. In this work, targeted at these problems, we first study the continual learning process through the lens of information theory and observe that forgetting of a model stems from the loss of \emph{information gain} on its parameters from the previous tasks when learning a new task. From this viewpoint, we then propose a novel continual learning approach called Bit-Level Information Preserving (BLIP) that preserves the information gain on model parameters through updating the parameters at the bit level, which can be conveniently implemented with parameter quantization. More specifically, BLIP first trains a neural network with weight quantization on the new incoming task and then estimates information gain on each parameter provided by the task data to determine the bits to be frozen to prevent forgetting. We conduct extensive experiments ranging from classification tasks to reinforcement learning tasks, and the results show that our method produces better or on par results comparing to previous state-of-the-arts. Indeed, BLIP achieves close to zero forgetting while only requiring constant memory overheads throughout continual learning.