 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video
Paper and Code
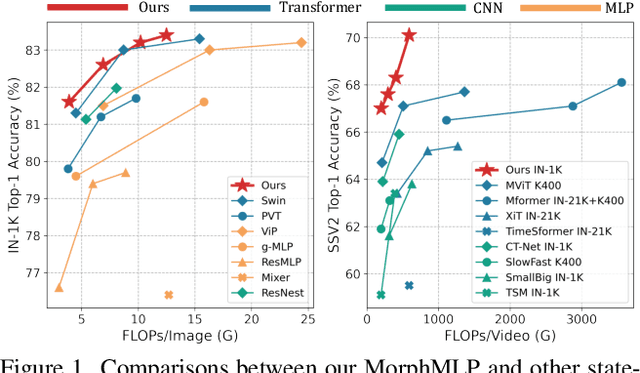
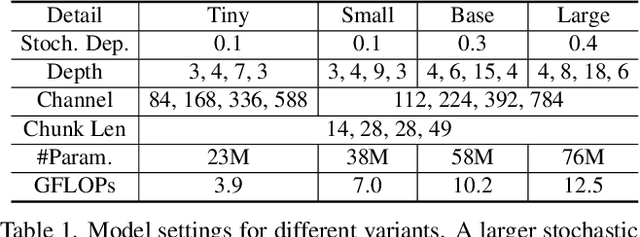
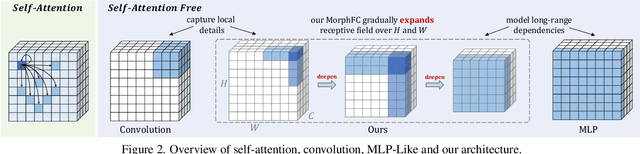
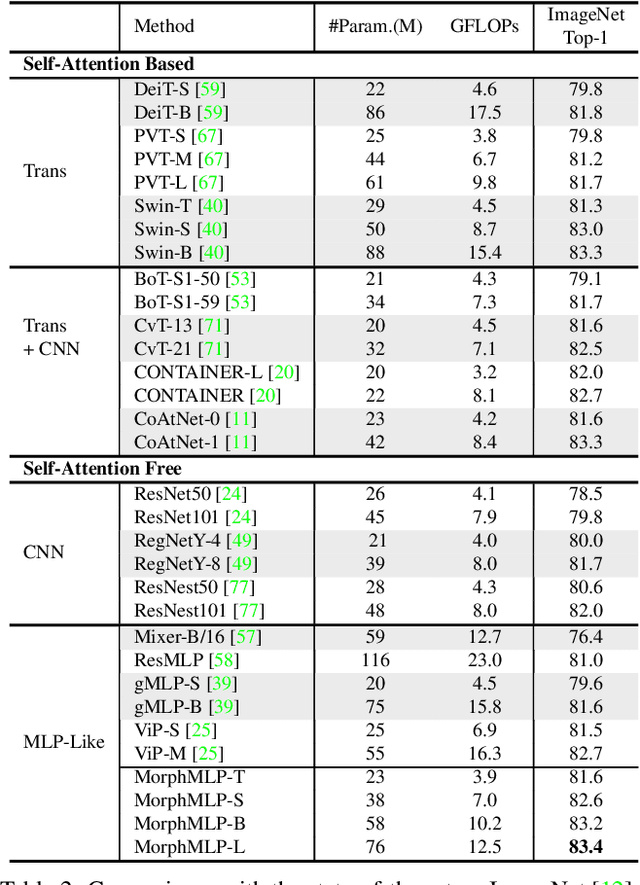
Self-attention has become an integral component of the recent network architectures, e.g., Transformer, that dominate major image and video benchmarks. This is because self-attention can flexibly model long-range information. For the same reason, researchers make attempts recently to revive Multiple Layer Perceptron (MLP) and propose a few MLP-Like architectures, showing great potential. However, the current MLP-Like architectures are not good at capturing local details and lack progressive understanding of core details in the images and/or videos. To overcome this issue, we propose a novel MorphMLP architecture that focuses on capturing local details at the low-level layers, while gradually changing to focus on long-term modeling at the high-level layers. Specifically, we design a Fully-Connected-Like layer, dubbed as MorphFC, of two morphable filters that gradually grow its receptive field along the height and width dimension. More interestingly, we propose to flexibly adapt our MorphFC layer in the video domain. To our best knowledge, we are the first to create a MLP-Like backbone for learning video representation. Finally, we conduct extensive experiments on image classification, semantic segmentation and video classification. Our MorphMLP, such a self-attention free backbone, can be as powerful as and even outperform self-attention based models.