 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Granularity: Multi-Perspective Dialogue Collaborative Selection for Dialogue State Tracking
May 20, 2022
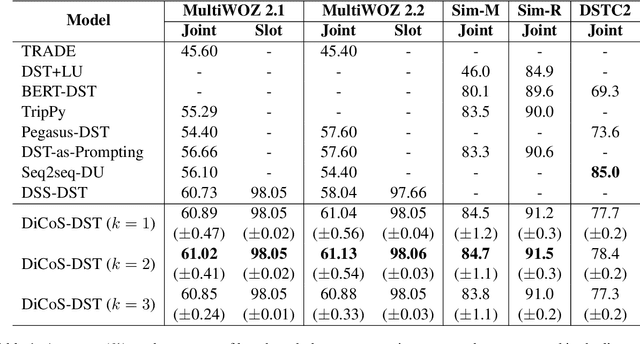
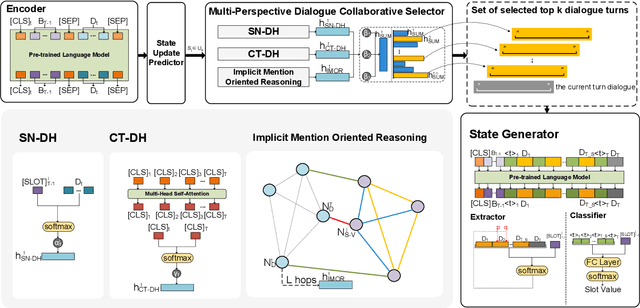
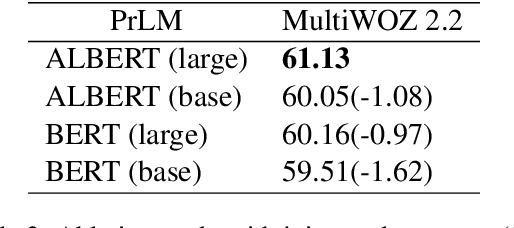
In dialogue state tracking, dialogue history is a crucial material, and its utilization varies between different models. However, no matter how the dialogue history is used, each existing model uses its own consistent dialogue history during the entire state tracking process, regardless of which slot is updated. Apparently, it requires different dialogue history to update different slots in different turns. Therefore, using consistent dialogue contents may lead to insufficient or redundant information for different slots, which affects the overall performance. To address this problem, we devise DiCoS-DST to dynamically select the relevant dialogue contents corresponding to each slot for state updating. Specifically, it first retrieves turn-level utterances of dialogue history and evaluates their relevance to the slot from a combination of three perspectives: (1) its explicit connection to the slot name; (2) its relevance to the current turn dialogue; (3) Implicit Mention Oriented Reasoning. Then these perspectives are combined to yield a decision, and only the selected dialogue contents are fed into State Generator, which explicitly minimizes the distracting information passed to the downstream state prediction. Experimental results show that our approach achieves new state-of-the-art performance on MultiWOZ 2.1 and MultiWOZ 2.2, and achieves superior performance on multiple mainstream benchmark datasets (including Sim-M, Sim-R, and DSTC2).
Dense Contrastive Visual-Linguistic Pretraining
Sep 24, 2021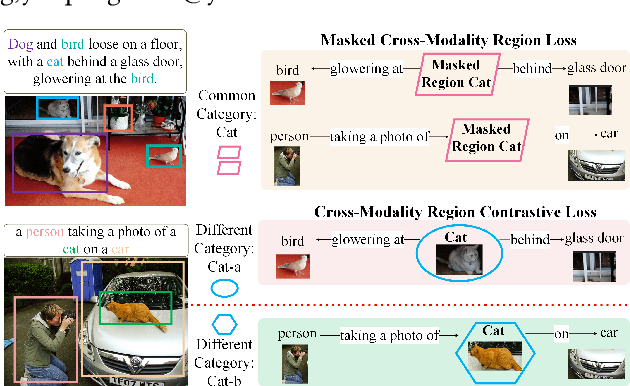

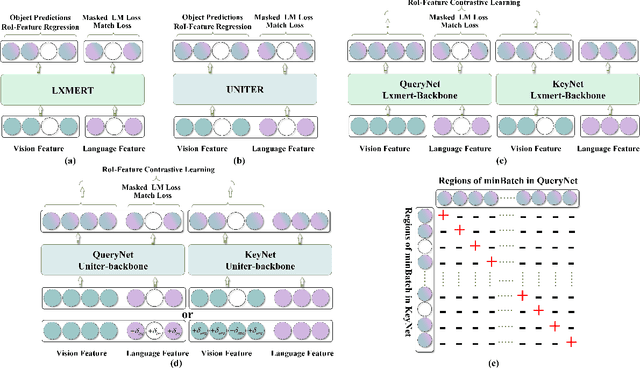
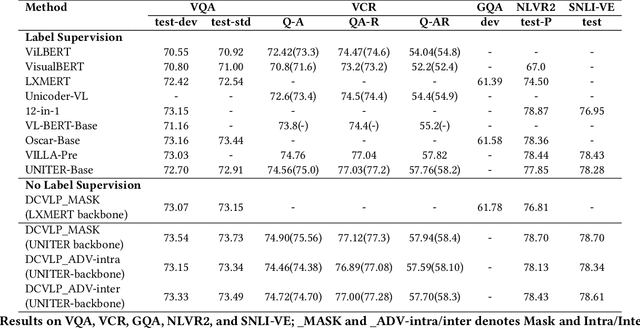
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.
Dual Slot Selector via Local Reliability Verification for Dialogue State Tracking
Jul 27, 2021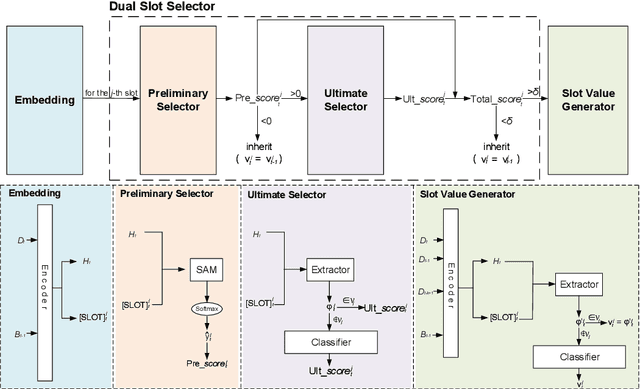


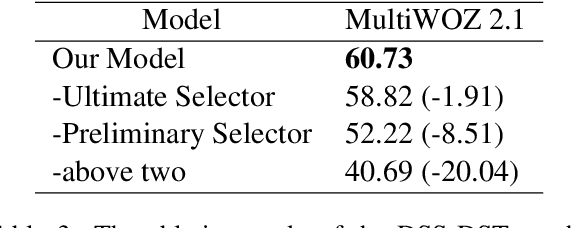
The goal of dialogue state tracking (DST) is to predict the current dialogue state given all previous dialogue contexts. Existing approaches generally predict the dialogue state at every turn from scratch. However, the overwhelming majority of the slots in each turn should simply inherit the slot values from the previous turn. Therefore, the mechanism of treating slots equally in each turn not only is inefficient but also may lead to additional errors because of the redundant slot value generation. To address this problem, we devise the two-stage DSS-DST which consists of the Dual Slot Selector based on the current turn dialogue, and the Slot Value Generator based on the dialogue history. The Dual Slot Selector determines each slot whether to update slot value or to inherit the slot value from the previous turn from two aspects: (1) if there is a strong relationship between it and the current turn dialogue utterances; (2) if a slot value with high reliability can be obtained for it through the current turn dialogue. The slots selected to be updated are permitted to enter the Slot Value Generator to update values by a hybrid method, while the other slots directly inherit the values from the previous turn. Empirical results show that our method achieves 56.93%, 60.73%, and 58.04% joint accuracy on MultiWOZ 2.0, MultiWOZ 2.1, and MultiWOZ 2.2 datasets respectively and achieves a new state-of-the-art performance with significant improvements.
A Hierarchical User Intention-Habit Extract Network for Credit Loan Overdue Risk Detection
Aug 18, 2020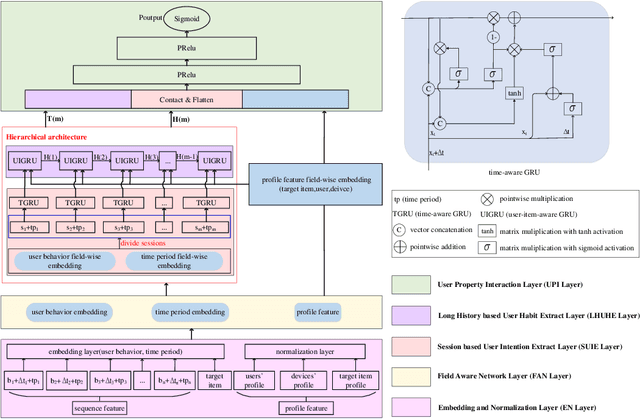
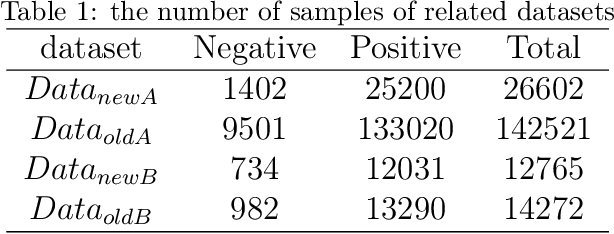
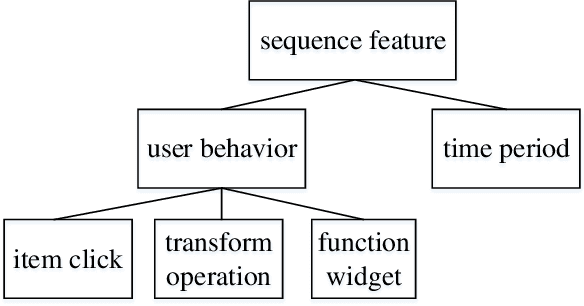
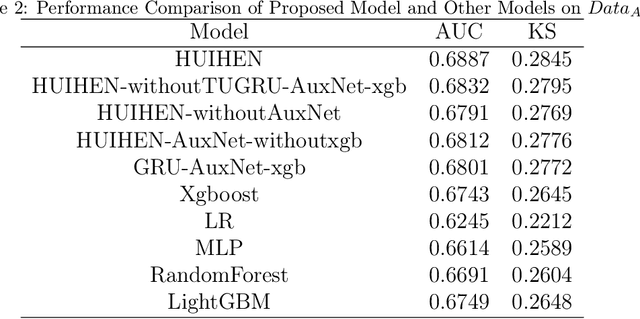
More personal consumer loan products are emerging in mobile banking APP. For ease of use, application process is always simple, which means that few application information is requested for user to fill when applying for a loan, which is not conducive to construct users' credit profile. Thus, the simple application process brings huge challenges to the overdue risk detection, as higher overdue rate will result in greater economic losses to the bank. In this paper, we propose a model named HUIHEN (Hierarchical User Intention-Habit Extract Network) that leverages the users' behavior information in mobile banking APP. Due to the diversity of users' behaviors, we divide behavior sequences into sessions according to the time interval, and use the field-aware method to extract the intra-field information of behaviors. Then, we propose a hierarchical network composed of time-aware GRU and user-item-aware GRU to capture users' short-term intentions and users' long-term habits, which can be regarded as a supplement to user profile. The proposed model can improve the accuracy without increasing the complexity of the original online application process. Experimental results demonstrate the superiority of HUIHEN and show that HUIHEN outperforms other state-of-art models on all datasets.
Contrastive Visual-Linguistic Pretraining
Jul 26, 2020

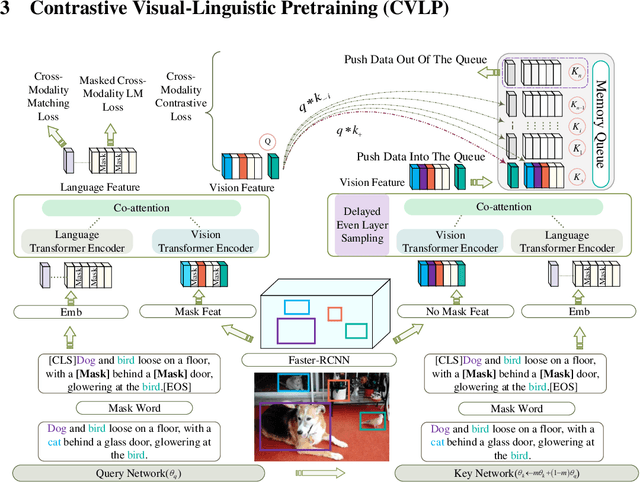

Several multi-modality representation learning approaches such as LXMERT and ViLBERT have been proposed recently. Such approaches can achieve superior performance due to the high-level semantic information captured during large-scale multimodal pretraining. However, as ViLBERT and LXMERT adopt visual region regression and classification loss, they often suffer from domain gap and noisy label problems, based on the visual features having been pretrained on the Visual Genome dataset. To overcome these issues, we propose unbiased Contrastive Visual-Linguistic Pretraining (CVLP), which constructs a visual self-supervised loss built upon contrastive learning. We evaluate CVLP on several down-stream tasks, including VQA, GQA and NLVR2 to validate the superiority of contrastive learning on multi-modality representation learning. Our code is available at: https://github.com/ArcherYunDong/CVLP-.
Multi-Layer Content Interaction Through Quaternion Product For Visual Question Answering
Feb 16, 2020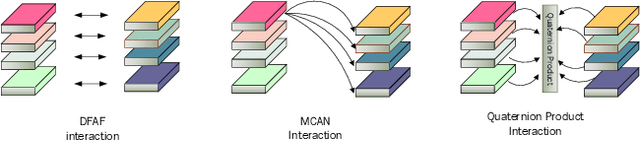
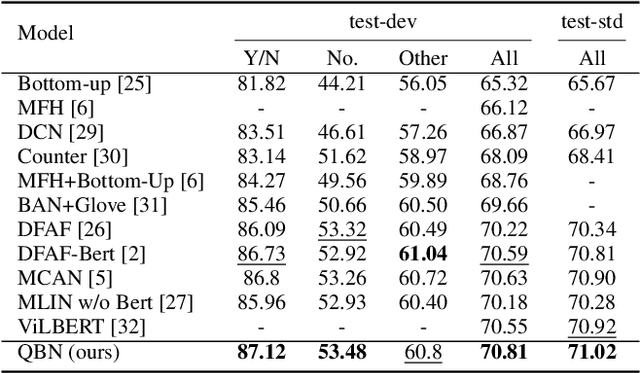


Multi-modality fusion technologies have greatly improved the performance of neural network-based Video Description/Caption, Visual Question Answering (VQA) and Audio Visual Scene-aware Dialog (AVSD) over the recent years. Most previous approaches only explore the last layers of multiple layer feature fusion while omitting the importance of intermediate layers. To solve the issue for the intermediate layers, we propose an efficient Quaternion Block Network (QBN) to learn interaction not only for the last layer but also for all intermediate layers simultaneously. In our proposed QBN, we use the holistic text features to guide the update of visual features. In the meantime, Hamilton quaternion products can efficiently perform information flow from higher layers to lower layers for both visual and text modalities. The evaluation results show our QBN improved the performance on VQA 2.0, even though using surpass large scale BERT or visual BERT pre-trained models. Extensive ablation study has been carried out to testify the influence of each proposed module in this study.
Adaptive Noise Injection: A Structure-Expanding Regularization for RNN
Jul 25, 2019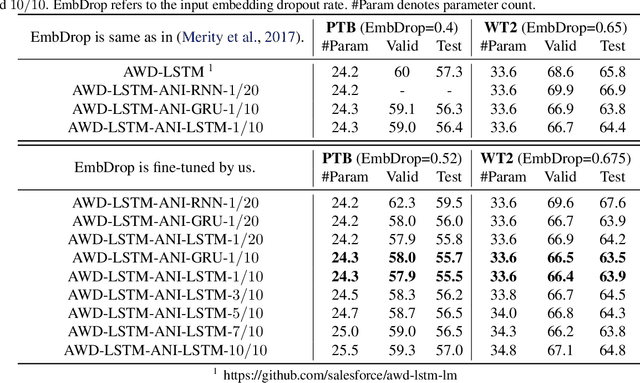



The vanilla LSTM has become one of the most potential architectures in word-level language modeling, like other recurrent neural networks, overfitting is always a key barrier for its effectiveness. The existing noise-injected regularizations introduce the random noises of fixation intensity, which inhibits the learning of the RNN throughout the training process. In this paper, we propose a new structure-expanding regularization method called Adjective Noise Injection (ANI), which considers the output of an extra RNN branch as a kind of adaptive noises and injects it into the main-branch RNN output. Due to the adaptive noises can be improved as the training processes, its negative effects can be weakened and even transformed into a positive effect to further improve the expressiveness of the main-branch RNN. As a result, ANI can regularize the RNN in the early stage of training and further promoting its training performance in the later stage. We conduct experiments on three widely-used corpora: PTB, WT2, and WT103, whose results verify both the regularization and promoting the training performance functions of ANI. Furthermore, we design a series simulation experiments to explore the reasons that may lead to the regularization effect of ANI, and we find that in training process, the robustness against the parameter update errors can be strengthened when the LSTM equipped with ANI.