 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Contrastive Visual-Linguistic Pretraining
Paper and Code
Sep 24, 2021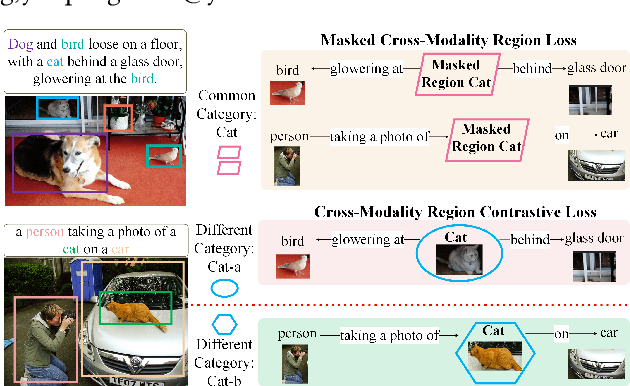

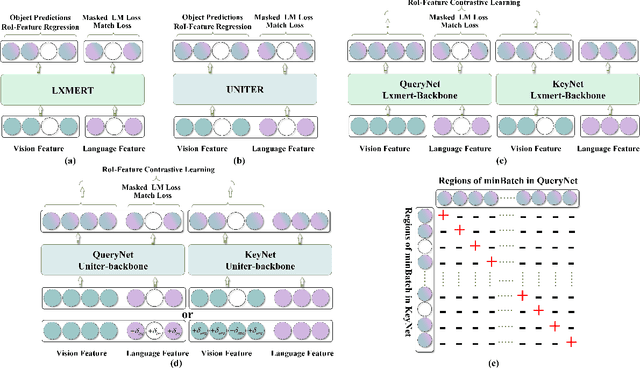
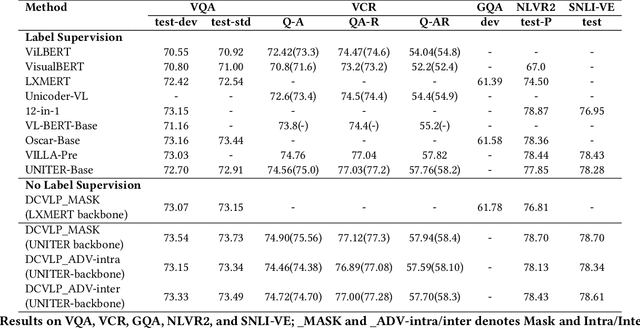
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.