 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexGrasp-Diffusion: Diffusion-based Unified Functional Grasp Synthesis Pipeline for Multi-Dexterous Robotic Hands
Jul 13, 2024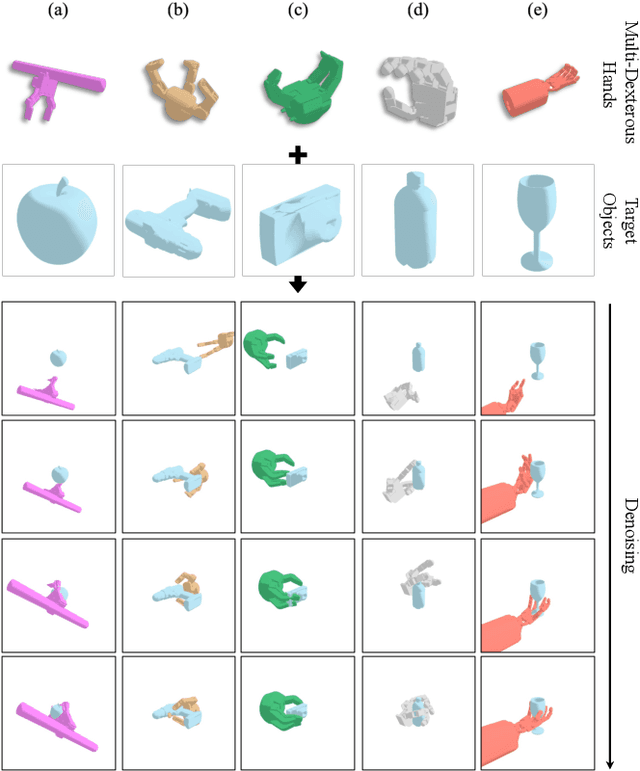
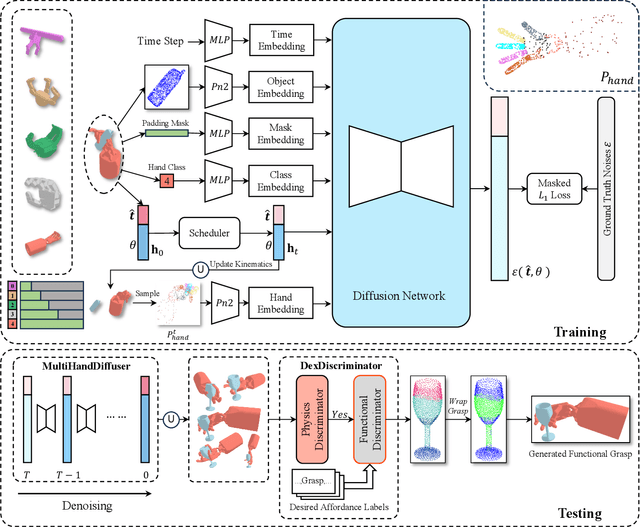

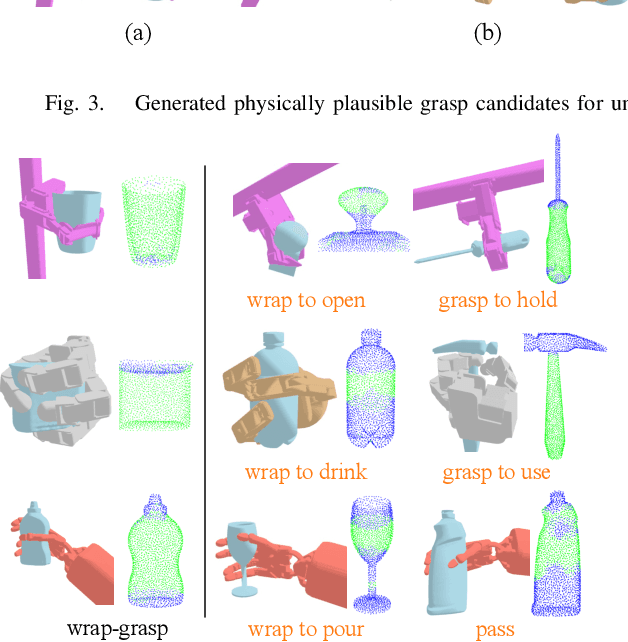
The versatility and adaptability of human grasping catalyze advancing dexterous robotic manipulation. While significant strides have been made in dexterous grasp generation, current research endeavors pivot towards optimizing object manipulation while ensuring functional integrity, emphasizing the synthesis of functional grasps following desired affordance instructions. This paper addresses the challenge of synthesizing functional grasps tailored to diverse dexterous robotic hands by proposing DexGrasp-Diffusion, an end-to-end modularized diffusion-based pipeline. DexGrasp-Diffusion integrates MultiHandDiffuser, a novel unified data-driven diffusion model for multi-dexterous hands grasp estimation, with DexDiscriminator, which employs a Physics Discriminator and a Functional Discriminator with open-vocabulary setting to filter physically plausible functional grasps based on object affordances. The experimental evaluation conducted on the MultiDex dataset provides substantiating evidence supporting the superior performance of MultiHandDiffuser over the baseline model in terms of success rate, grasp diversity, and collision depth. Moreover, we demonstrate the capacity of DexGrasp-Diffusion to reliably generate functional grasps for household objects aligned with specific affordance instructions.
You Only Scan Once: A Dynamic Scene Reconstruction Pipeline for 6-DoF Robotic Grasping of Novel Objects
Apr 04, 2024



In the realm of robotic grasping, achieving accurate and reliable interactions with the environment is a pivotal challenge. Traditional methods of grasp planning methods utilizing partial point clouds derived from depth image often suffer from reduced scene understanding due to occlusion, ultimately impeding their grasping accuracy. Furthermore, scene reconstruction methods have primarily relied upon static techniques, which are susceptible to environment change during manipulation process limits their efficacy in real-time grasping tasks. To address these limitations, this paper introduces a novel two-stage pipeline for dynamic scene reconstruction. In the first stage, our approach takes scene scanning as input to register each target object with mesh reconstruction and novel object pose tracking. In the second stage, pose tracking is still performed to provide object poses in real-time, enabling our approach to transform the reconstructed object point clouds back into the scene. Unlike conventional methodologies, which rely on static scene snapshots, our method continuously captures the evolving scene geometry, resulting in a comprehensive and up-to-date point cloud representation. By circumventing the constraints posed by occlusion, our method enhances the overall grasp planning process and empowers state-of-the-art 6-DoF robotic grasping algorithms to exhibit markedly improved accuracy.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Jan 28, 2021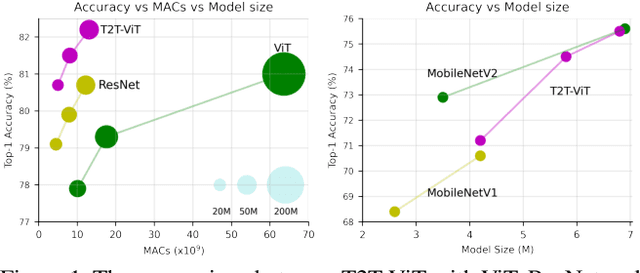
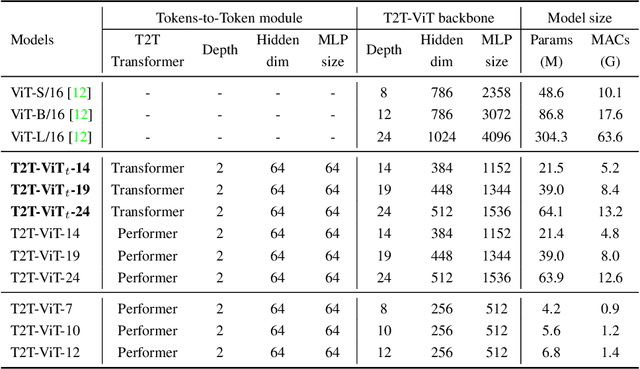

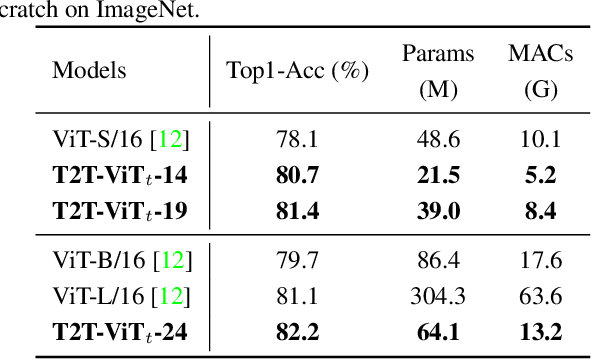
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: https://github.com/yitu-opensource/T2T-ViT)
Central Similarity Hashing via Hadamard matrix
Aug 01, 2019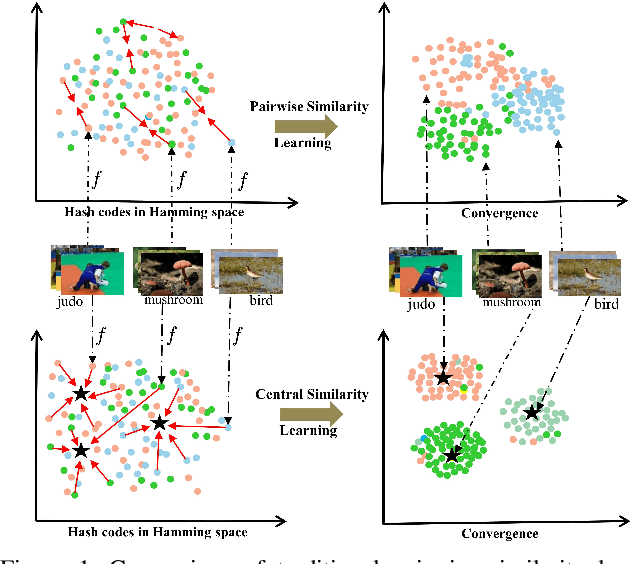
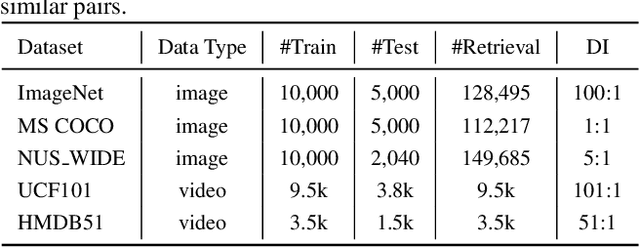
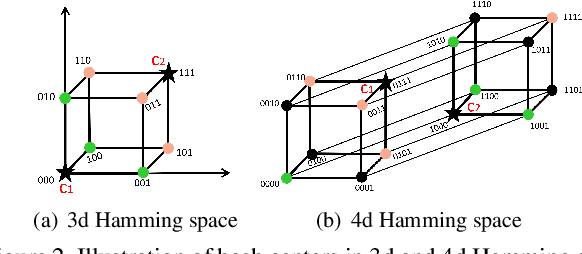
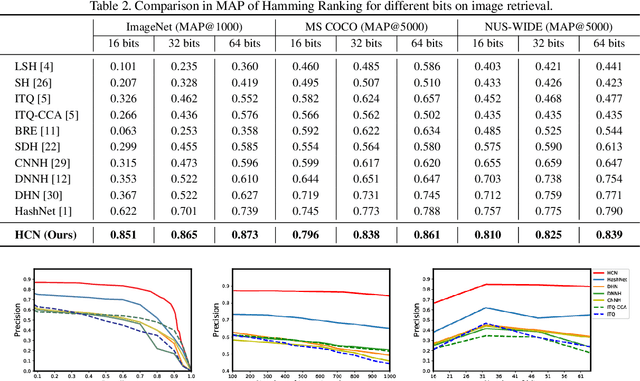
Hashing has been widely used for efficient large-scale multimedia data retrieval. Most existing methods learn hashing functions from data pairwise similarity to generate binary hash codes. However, in practice we find only learning from the local relationships of pairwise similarity cannot capture the global distribution of large-scale data, which would degrade the discriminability of the generated hash codes and harm the retrieval performance. To overcome this limitation, we propose a new global similarity metric, termed as \emph{central similarity}, to learn better hashing functions. The target of central similarity learning is to encourage hash codes for similar data pairs to be close to a common center and those for dissimilar pairs to converge to different centers in the Hamming space, which substantially improves retrieval accuracy. In order to principally formulate the central similarity learning, we define a new concept, \emph{hash center}, to be a set of points scattered in the Hamming space with a sufficient distance between each other, and propose to use Hadamard matrix to construct high-quality hash centers efficiently. Based on these definitions and designs, we devise a new hash center network (HCN) that learns hashing functions by optimizing the central similarity w.r.t.\ these hash centers. The central similarity learning and HCN are generic and can be applied for both image and video hashing. Extensive experiments for both image and video retrieval demonstrate HCN can generate cohesive hash codes for similar data pairs and dispersed hash codes for dissimilar pairs, and achieve noticeable boost in retrieval performance, i.e. 4\%-13\% in MAP over latest state-of-the-arts. The codes are in: \url{https://github.com/yuanli2333/Hadamard-Matrix-for-hashing}
Cycle-SUM: Cycle-consistent Adversarial LSTM Networks for Unsupervised Video Summarization
Apr 17, 2019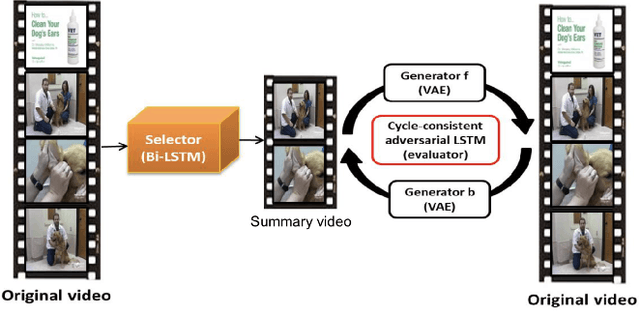

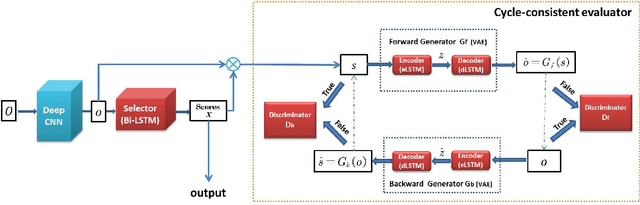
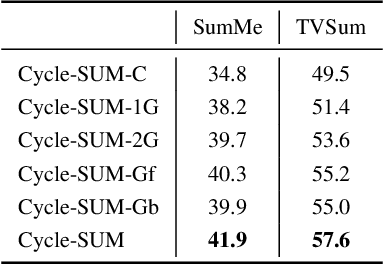
In this paper, we present a novel unsupervised video summarization model that requires no manual annotation. The proposed model termed Cycle-SUM adopts a new cycle-consistent adversarial LSTM architecture that can effectively maximize the information preserving and compactness of the summary video. It consists of a frame selector and a cycle-consistent learning based evaluator. The selector is a bi-direction LSTM network that learns video representations that embed the long-range relationships among video frames. The evaluator defines a learnable information preserving metric between original video and summary video and "supervises" the selector to identify the most informative frames to form the summary video. In particular, the evaluator is composed of two generative adversarial networks (GANs), in which the forward GAN is learned to reconstruct original video from summary video while the backward GAN learns to invert the processing. The consistency between the output of such cycle learning is adopted as the information preserving metric for video summarization. We demonstrate the close relation between mutual information maximization and such cycle learning procedure. Experiments on two video summarization benchmark datasets validate the state-of-the-art performance and superiority of the Cycle-SUM model over previous baselines.