 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-SUM: Cycle-consistent Adversarial LSTM Networks for Unsupervised Video Summarization
Paper and Code
Apr 17, 2019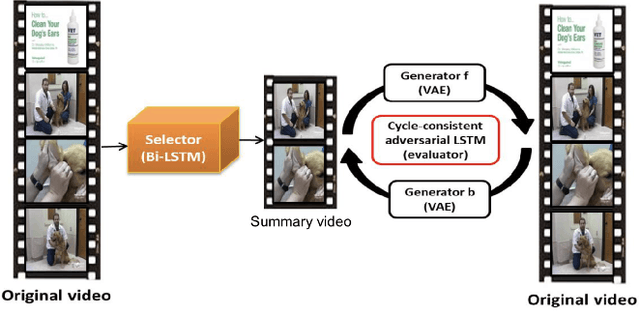

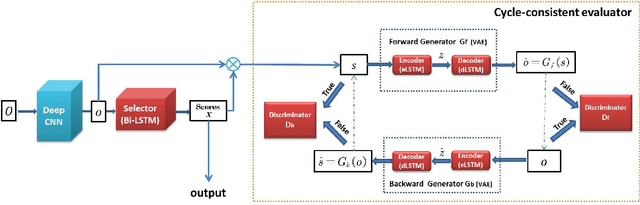
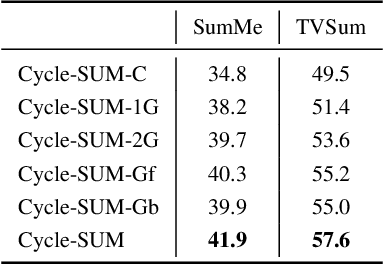
In this paper, we present a novel unsupervised video summarization model that requires no manual annotation. The proposed model termed Cycle-SUM adopts a new cycle-consistent adversarial LSTM architecture that can effectively maximize the information preserving and compactness of the summary video. It consists of a frame selector and a cycle-consistent learning based evaluator. The selector is a bi-direction LSTM network that learns video representations that embed the long-range relationships among video frames. The evaluator defines a learnable information preserving metric between original video and summary video and "supervises" the selector to identify the most informative frames to form the summary video. In particular, the evaluator is composed of two generative adversarial networks (GANs), in which the forward GAN is learned to reconstruct original video from summary video while the backward GAN learns to invert the processing. The consistency between the output of such cycle learning is adopted as the information preserving metric for video summarization. We demonstrate the close relation between mutual information maximization and such cycle learning procedure. Experiments on two video summarization benchmark datasets validate the state-of-the-art performance and superiority of the Cycle-SUM model over previous baselines.