 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
DexGrasp-Diffusion: Diffusion-based Unified Functional Grasp Synthesis Pipeline for Multi-Dexterous Robotic Hands
Jul 13, 2024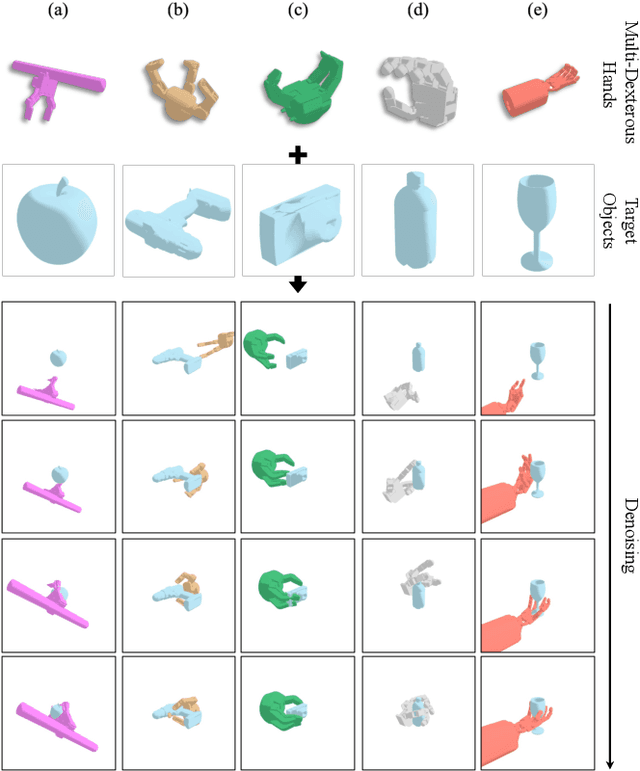
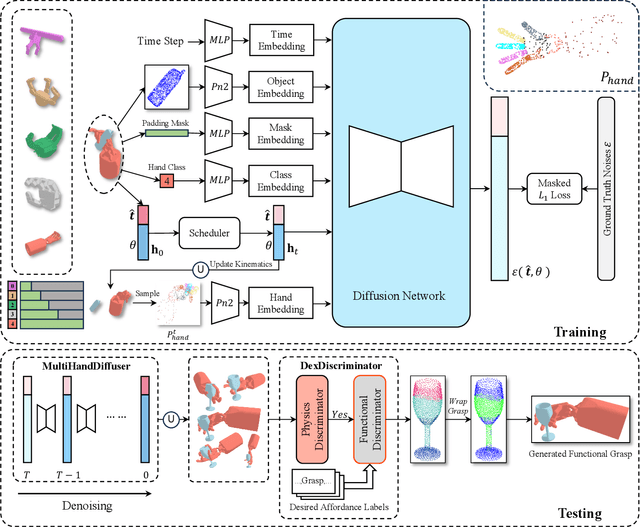

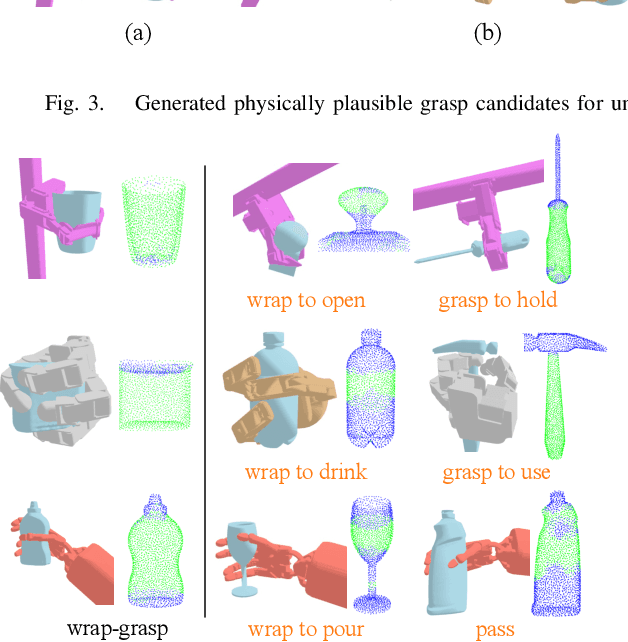
The versatility and adaptability of human grasping catalyze advancing dexterous robotic manipulation. While significant strides have been made in dexterous grasp generation, current research endeavors pivot towards optimizing object manipulation while ensuring functional integrity, emphasizing the synthesis of functional grasps following desired affordance instructions. This paper addresses the challenge of synthesizing functional grasps tailored to diverse dexterous robotic hands by proposing DexGrasp-Diffusion, an end-to-end modularized diffusion-based pipeline. DexGrasp-Diffusion integrates MultiHandDiffuser, a novel unified data-driven diffusion model for multi-dexterous hands grasp estimation, with DexDiscriminator, which employs a Physics Discriminator and a Functional Discriminator with open-vocabulary setting to filter physically plausible functional grasps based on object affordances. The experimental evaluation conducted on the MultiDex dataset provides substantiating evidence supporting the superior performance of MultiHandDiffuser over the baseline model in terms of success rate, grasp diversity, and collision depth. Moreover, we demonstrate the capacity of DexGrasp-Diffusion to reliably generate functional grasps for household objects aligned with specific affordance instructions.
You Only Scan Once: A Dynamic Scene Reconstruction Pipeline for 6-DoF Robotic Grasping of Novel Objects
Apr 04, 2024



In the realm of robotic grasping, achieving accurate and reliable interactions with the environment is a pivotal challenge. Traditional methods of grasp planning methods utilizing partial point clouds derived from depth image often suffer from reduced scene understanding due to occlusion, ultimately impeding their grasping accuracy. Furthermore, scene reconstruction methods have primarily relied upon static techniques, which are susceptible to environment change during manipulation process limits their efficacy in real-time grasping tasks. To address these limitations, this paper introduces a novel two-stage pipeline for dynamic scene reconstruction. In the first stage, our approach takes scene scanning as input to register each target object with mesh reconstruction and novel object pose tracking. In the second stage, pose tracking is still performed to provide object poses in real-time, enabling our approach to transform the reconstructed object point clouds back into the scene. Unlike conventional methodologies, which rely on static scene snapshots, our method continuously captures the evolving scene geometry, resulting in a comprehensive and up-to-date point cloud representation. By circumventing the constraints posed by occlusion, our method enhances the overall grasp planning process and empowers state-of-the-art 6-DoF robotic grasping algorithms to exhibit markedly improved accuracy.
SynTable: A Synthetic Data Generation Pipeline for Unseen Object Amodal Instance Segmentation of Cluttered Tabletop Scenes
Jul 14, 2023



In this work, we present SynTable, a unified and flexible Python-based dataset generator built using NVIDIA's Isaac Sim Replicator Composer for generating high-quality synthetic datasets for unseen object amodal instance segmentation of cluttered tabletop scenes. Our dataset generation tool can render a complex 3D scene containing object meshes, materials, textures, lighting, and backgrounds. Metadata, such as modal and amodal instance segmentation masks, occlusion masks, depth maps, bounding boxes, and material properties, can be generated to automatically annotate the scene according to the users' requirements. Our tool eliminates the need for manual labeling in the dataset generation process while ensuring the quality and accuracy of the dataset. In this work, we discuss our design goals, framework architecture, and the performance of our tool. We demonstrate the use of a sample dataset generated using SynTable by ray tracing for training a state-of-the-art model, UOAIS-Net. The results show significantly improved performance in Sim-to-Real transfer when evaluated on the OSD-Amodal dataset. We offer this tool as an open-source, easy-to-use, photorealistic dataset generator for advancing research in deep learning and synthetic data generation.