 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFD-VLA: Force-Distilled Vision-Language-Action Model for Contact-Rich Manipulation
Feb 02, 2026Force sensing is a crucial modality for Vision-Language-Action (VLA) frameworks, as it enables fine-grained perception and dexterous manipulation in contact-rich tasks. We present Force-Distilled VLA (FD-VLA), a novel framework that integrates force awareness into contact-rich manipulation without relying on physical force sensors. The core of our approach is a Force Distillation Module (FDM), which distills force by mapping a learnable query token, conditioned on visual observations and robot states, into a predicted force token aligned with the latent representation of actual force signals. During inference, this distilled force token is injected into the pretrained VLM, enabling force-aware reasoning while preserving the integrity of its vision-language semantics. This design provides two key benefits: first, it allows practical deployment across a wide range of robots that lack expensive or fragile force-torque sensors, thereby reducing hardware cost and complexity; second, the FDM introduces an additional force-vision-state fusion prior to the VLM, which improves cross-modal alignment and enhances perception-action robustness in contact-rich scenarios. Surprisingly, our physical experiments show that the distilled force token outperforms direct sensor force measurements as well as other baselines, which highlights the effectiveness of this force-distilled VLA approach.
DexGrasp-Diffusion: Diffusion-based Unified Functional Grasp Synthesis Pipeline for Multi-Dexterous Robotic Hands
Jul 13, 2024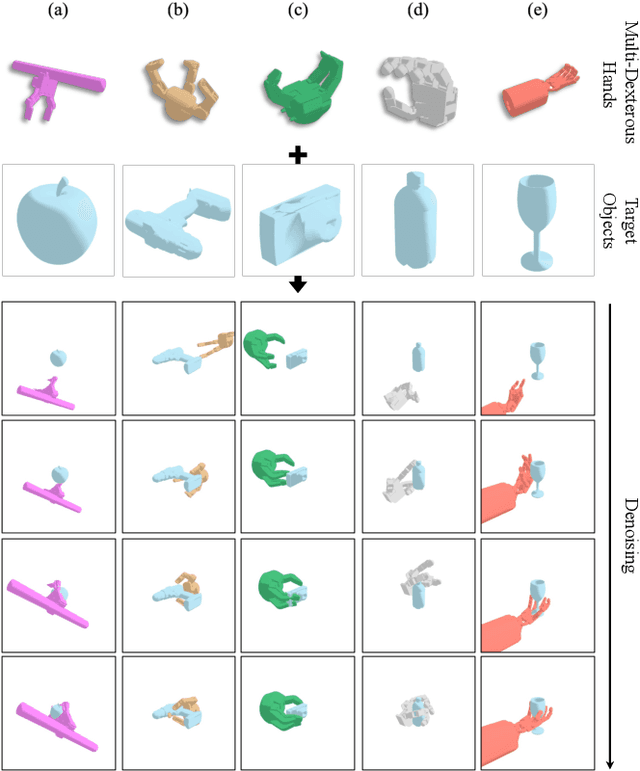
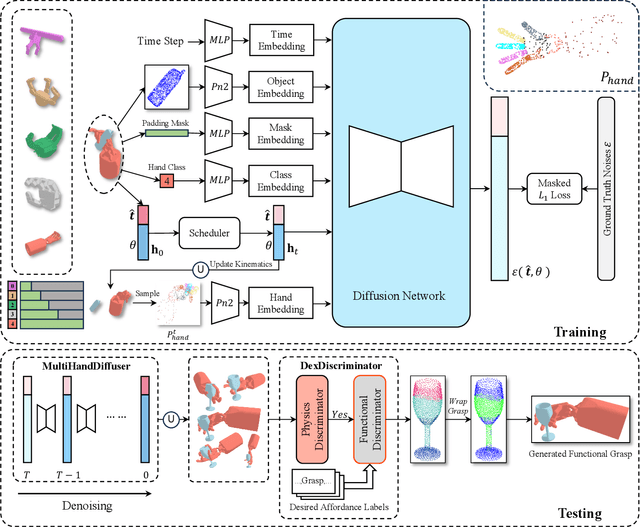

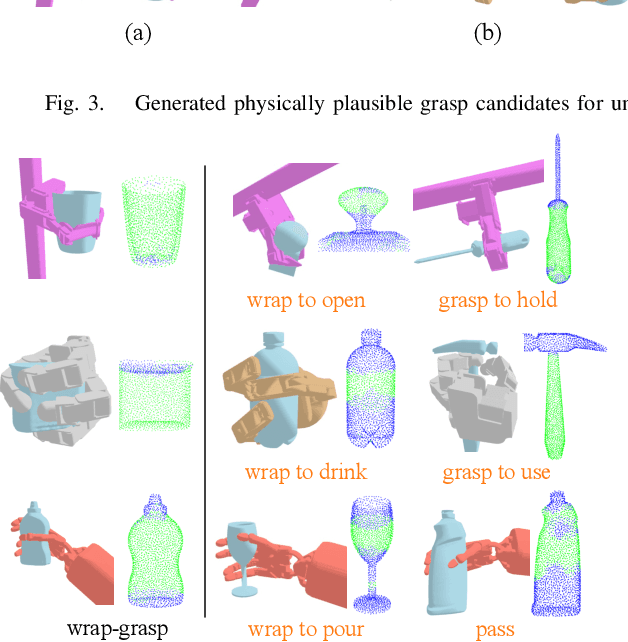
The versatility and adaptability of human grasping catalyze advancing dexterous robotic manipulation. While significant strides have been made in dexterous grasp generation, current research endeavors pivot towards optimizing object manipulation while ensuring functional integrity, emphasizing the synthesis of functional grasps following desired affordance instructions. This paper addresses the challenge of synthesizing functional grasps tailored to diverse dexterous robotic hands by proposing DexGrasp-Diffusion, an end-to-end modularized diffusion-based pipeline. DexGrasp-Diffusion integrates MultiHandDiffuser, a novel unified data-driven diffusion model for multi-dexterous hands grasp estimation, with DexDiscriminator, which employs a Physics Discriminator and a Functional Discriminator with open-vocabulary setting to filter physically plausible functional grasps based on object affordances. The experimental evaluation conducted on the MultiDex dataset provides substantiating evidence supporting the superior performance of MultiHandDiffuser over the baseline model in terms of success rate, grasp diversity, and collision depth. Moreover, we demonstrate the capacity of DexGrasp-Diffusion to reliably generate functional grasps for household objects aligned with specific affordance instructions.