 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking 3D Shape Generation: Diffusion over Superquadrics
Jun 08, 2026Diffusion models have advanced 3D shape generation, yet most methods still denoise in high-cardinality spaces (e.g., voxel/SDF grids, meshes, or point clouds), which is computationally and memory intensive and makes it difficult to scale in terms of both higher resolution and stronger controllability. We rethink the diffusion representation and propose to move diffusion from dense geometry to compact geometric primitives, representing each shape as a small set of superquadrics. Instead of operating on thousands to millions of geometric representation values, we leverage 7KB superquadric parameters (pose, size, and shape), drastically reducing diffusion-state dimensionality and per-step compute/memory. Our diffusion-over-superquadrics improves scalability by supporting broader capabilities (e.g., resolution-free point-cloud decoding, part-level editing, and constraint-based design) and achieving competitive surface-fidelity and distributional performance on standard benchmarks after point-cloud decoding, while enabling efficient generation within 0.6s per shape for most conditions.
NTR: Neural Token Reconstruction for Scene Token Bottleneck in End-to-End Driving
May 29, 2026Recent perception-free end-to-end (E2E) autonomous driving methods bypass explicit perception outputs by compressing dense image patch tokens into compact scene tokens for downstream trajectory generation and scoring. While these scene tokens form a compact visual bottleneck for the planner, they receive supervision solely from the planning objective, providing limited constraints on the encoded visual information. To address this limitation, we introduce Neural Token Reconstruction (NTR), a representation learning framework to directly constrain the compact scene-token bottleneck in perception-free driving. NTR introduces a self-distillation masked latent reconstruction objective that reconstructs masked patch-level latent features using only compact scene tokens as reconstruction memory. This forces reconstruction gradients to pass exclusively through the scene-token bottleneck, encouraging scene tokens to preserve richer and less redundant visual representations for planning. We further introduce semantic priors derived from foundation-model annotations as a weak semantic interface biasing reconstruction targets toward driving-related structures without introducing explicit perception heads. All auxiliary reconstruction components are removed at inference time, leaving the deployed planner unchanged. NTR achieves state-of-the-art performance on three public autonomous driving benchmarks, including 8.0461 RFS on Waymo E2E and 94.1 PDMS / 90.9 EPDMS on NavSim1&2. The learned scene tokens exhibit lower pairwise redundancy and higher effective rank, indicating that effective bottleneck supervision improves both compact visual representation learning and planning performance.
Precise Aggressive Aerial Maneuvers with Sensorimotor Policies
Apr 07, 2026Precise aggressive maneuvers with lightweight onboard sensors remains a key bottleneck in fully exploiting the maneuverability of drones. Such maneuvers are critical for expanding the systems' accessible area by navigating through narrow openings in the environment. Among the most relevant problems, a representative one is aggressive traversal through narrow gaps with quadrotors under SE(3) constraints, which require the quadrotors to leverage a momentary tilted attitude and the asymmetry of the airframe to navigate through gaps. In this paper, we achieve such maneuvers by developing sensorimotor policies directly mapping onboard vision and proprioception into low-level control commands. The policies are trained using reinforcement learning (RL) with end-to-end policy distillation in simulation. We mitigate the fundamental hardness of model-free RL's exploration on the restricted solution space with an initialization strategy leveraging trajectories generated by a model-based planner. Careful sim-to-real design allows the policy to control a quadrotor through narrow gaps with low clearances and high repeatability. For instance, the proposed method enables a quadrotor to navigate a rectangular gap at a 5 cm clearance, tilted at up to 90-degree orientation, without knowledge of the gap's position or orientation. Without training on dynamic gaps, the policy can reactively servo the quadrotor to traverse through a moving gap. The proposed method is also validated by training and deploying policies on challenging tracks of narrow gaps placed closely. The flexibility of the policy learning method is demonstrated by developing policies for geometrically diverse gaps, without relying on manually defined traversal poses and visual features.
NavDreamer: Video Models as Zero-Shot 3D Navigators
Feb 10, 2026Previous Vision-Language-Action models face critical limitations in navigation: scarce, diverse data from labor-intensive collection and static representations that fail to capture temporal dynamics and physical laws. We propose NavDreamer, a video-based framework for 3D navigation that leverages generative video models as a universal interface between language instructions and navigation trajectories. Our main hypothesis is that video's ability to encode spatiotemporal information and physical dynamics, combined with internet-scale availability, enables strong zero-shot generalization in navigation. To mitigate the stochasticity of generative predictions, we introduce a sampling-based optimization method that utilizes a VLM for trajectory scoring and selection. An inverse dynamics model is employed to decode executable waypoints from generated video plans for navigation. To systematically evaluate this paradigm in several video model backbones, we introduce a comprehensive benchmark covering object navigation, precise navigation, spatial grounding, language control, and scene reasoning. Extensive experiments demonstrate robust generalization across novel objects and unseen environments, with ablation studies revealing that navigation's high-level decision-making nature makes it particularly suited for video-based planning.
USS-Nav: Unified Spatio-Semantic Scene Graph for Lightweight UAV Zero-Shot Object Navigation
Feb 03, 2026Zero-Shot Object Navigation in unknown environments poses significant challenges for Unmanned Aerial Vehicles (UAVs) due to the conflict between high-level semantic reasoning requirements and limited onboard computational resources. To address this, we present USS-Nav, a lightweight framework that incrementally constructs a Unified Spatio-Semantic scene graph and enables efficient Large Language Model (LLM)-augmented Zero-Shot Object Navigation in unknown environments. Specifically, we introduce an incremental Spatial Connectivity Graph generation method utilizing polyhedral expansion to capture global geometric topology, which is dynamically partitioned into semantic regions via graph clustering. Concurrently, open-vocabulary object semantics are instantiated and anchored to this topology to form a hierarchical environmental representation. Leveraging this hierarchical structure, we present a coarse-to-fine exploration strategy: LLM grounded in the scene graph's semantics to determine global target regions, while a local planner optimizes frontier coverage based on information gain. Experimental results demonstrate that our framework outperforms state-of-the-art methods in terms of computational efficiency and real-time update frequency (15 Hz) on a resource-constrained platform. Furthermore, ablation studies confirm the effectiveness of our framework, showing substantial improvements in Success weighted by Path Length (SPL). The source code will be made publicly available to foster further research.
SeLIP: Similarity Enhanced Contrastive Language Image Pretraining for Multi-modal Head MRI
Mar 25, 2025



Despite that deep learning (DL) methods have presented tremendous potential in many medical image analysis tasks, the practical applications of medical DL models are limited due to the lack of enough data samples with manual annotations. By noting that the clinical radiology examinations are associated with radiology reports that describe the images, we propose to develop a foundation model for multi-model head MRI by using contrastive learning on the images and the corresponding radiology findings. In particular, a contrastive learning framework is proposed, where a mixed syntax and semantic similarity matching metric is integrated to reduce the thirst of extreme large dataset in conventional contrastive learning framework. Our proposed similarity enhanced contrastive language image pretraining (SeLIP) is able to effectively extract more useful features. Experiments revealed that our proposed SeLIP performs well in many downstream tasks including image-text retrieval task, classification task, and image segmentation, which highlights the importance of considering the similarities among texts describing different images in developing medical image foundation models.
DexGrasp-Diffusion: Diffusion-based Unified Functional Grasp Synthesis Pipeline for Multi-Dexterous Robotic Hands
Jul 13, 2024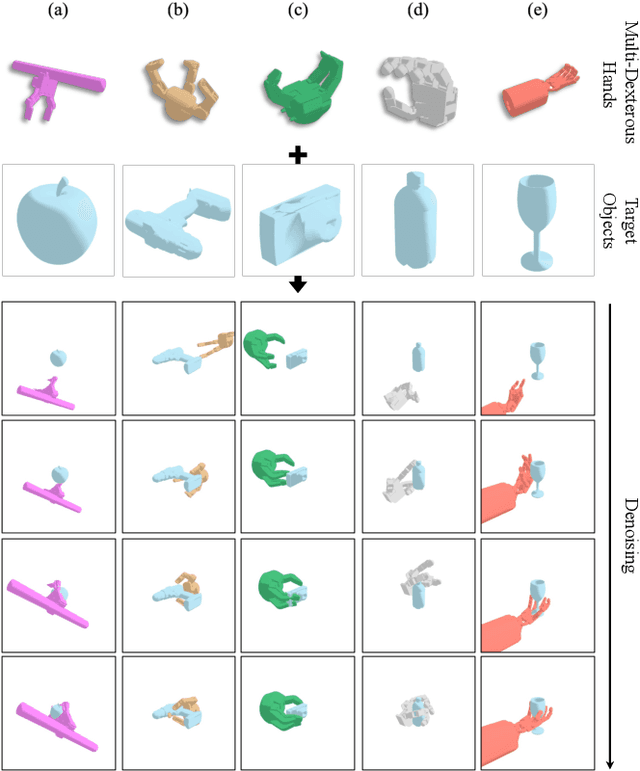
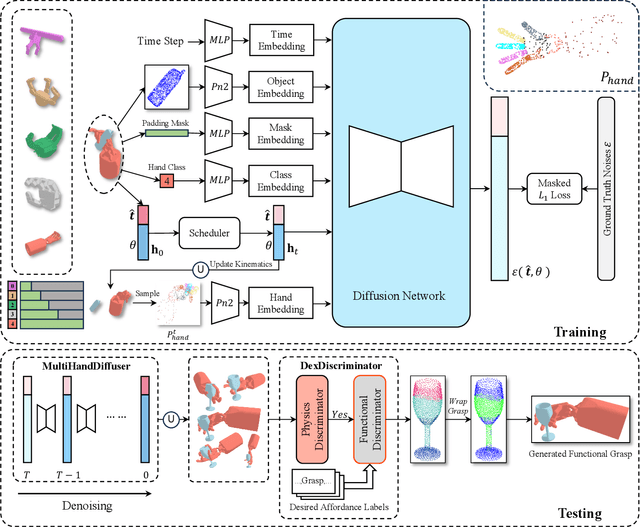

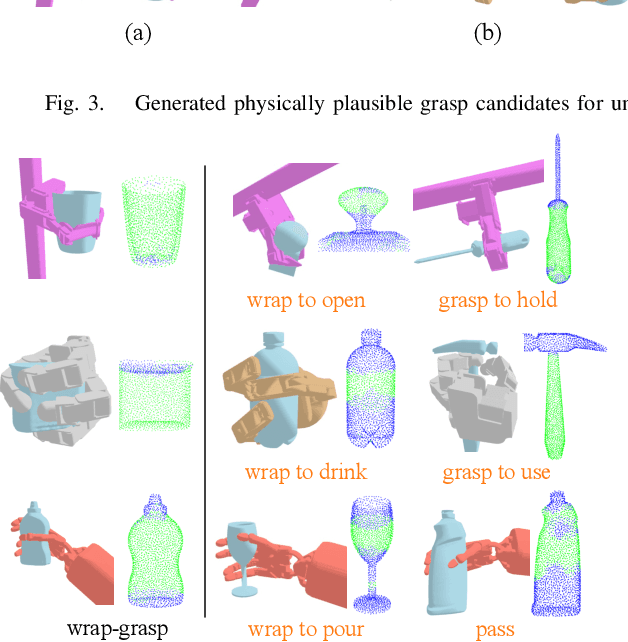
The versatility and adaptability of human grasping catalyze advancing dexterous robotic manipulation. While significant strides have been made in dexterous grasp generation, current research endeavors pivot towards optimizing object manipulation while ensuring functional integrity, emphasizing the synthesis of functional grasps following desired affordance instructions. This paper addresses the challenge of synthesizing functional grasps tailored to diverse dexterous robotic hands by proposing DexGrasp-Diffusion, an end-to-end modularized diffusion-based pipeline. DexGrasp-Diffusion integrates MultiHandDiffuser, a novel unified data-driven diffusion model for multi-dexterous hands grasp estimation, with DexDiscriminator, which employs a Physics Discriminator and a Functional Discriminator with open-vocabulary setting to filter physically plausible functional grasps based on object affordances. The experimental evaluation conducted on the MultiDex dataset provides substantiating evidence supporting the superior performance of MultiHandDiffuser over the baseline model in terms of success rate, grasp diversity, and collision depth. Moreover, we demonstrate the capacity of DexGrasp-Diffusion to reliably generate functional grasps for household objects aligned with specific affordance instructions.
You Only Scan Once: A Dynamic Scene Reconstruction Pipeline for 6-DoF Robotic Grasping of Novel Objects
Apr 04, 2024



In the realm of robotic grasping, achieving accurate and reliable interactions with the environment is a pivotal challenge. Traditional methods of grasp planning methods utilizing partial point clouds derived from depth image often suffer from reduced scene understanding due to occlusion, ultimately impeding their grasping accuracy. Furthermore, scene reconstruction methods have primarily relied upon static techniques, which are susceptible to environment change during manipulation process limits their efficacy in real-time grasping tasks. To address these limitations, this paper introduces a novel two-stage pipeline for dynamic scene reconstruction. In the first stage, our approach takes scene scanning as input to register each target object with mesh reconstruction and novel object pose tracking. In the second stage, pose tracking is still performed to provide object poses in real-time, enabling our approach to transform the reconstructed object point clouds back into the scene. Unlike conventional methodologies, which rely on static scene snapshots, our method continuously captures the evolving scene geometry, resulting in a comprehensive and up-to-date point cloud representation. By circumventing the constraints posed by occlusion, our method enhances the overall grasp planning process and empowers state-of-the-art 6-DoF robotic grasping algorithms to exhibit markedly improved accuracy.
DR-Pose: A Two-stage Deformation-and-Registration Pipeline for Category-level 6D Object Pose Estimation
Sep 05, 2023Category-level object pose estimation involves estimating the 6D pose and the 3D metric size of objects from predetermined categories. While recent approaches take categorical shape prior information as reference to improve pose estimation accuracy, the single-stage network design and training manner lead to sub-optimal performance since there are two distinct tasks in the pipeline. In this paper, the advantage of two-stage pipeline over single-stage design is discussed. To this end, we propose a two-stage deformation-and registration pipeline called DR-Pose, which consists of completion-aided deformation stage and scaled registration stage. The first stage uses a point cloud completion method to generate unseen parts of target object, guiding subsequent deformation on the shape prior. In the second stage, a novel registration network is designed to extract pose-sensitive features and predict the representation of object partial point cloud in canonical space based on the deformation results from the first stage. DR-Pose produces superior results to the state-of-the-art shape prior-based methods on both CAMERA25 and REAL275 benchmarks. Codes are available at https://github.com/Zray26/DR-Pose.git.
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023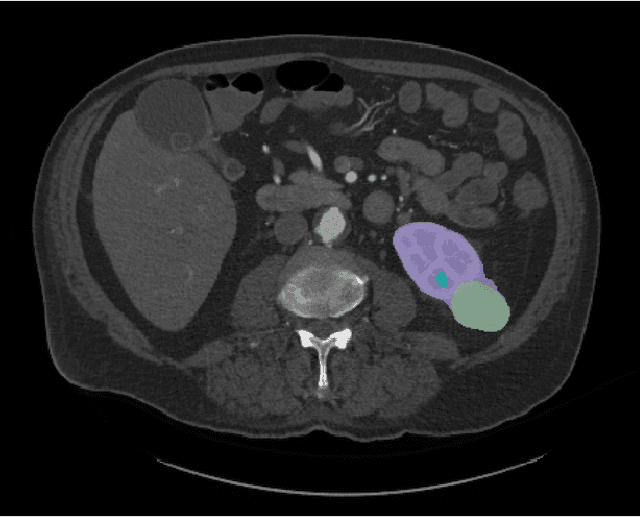
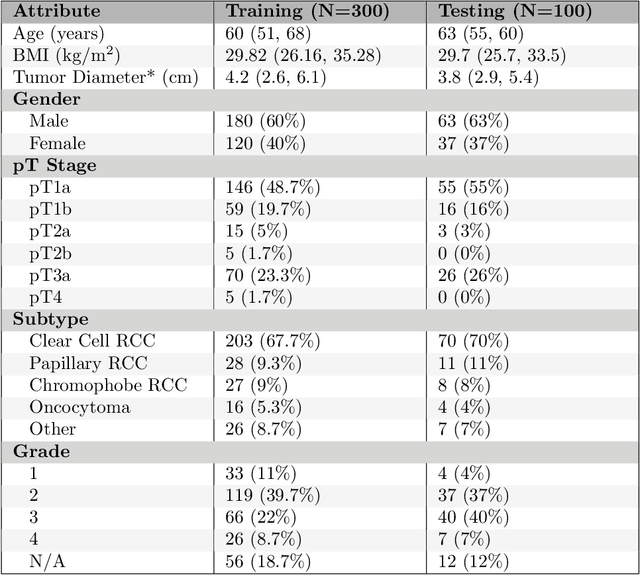
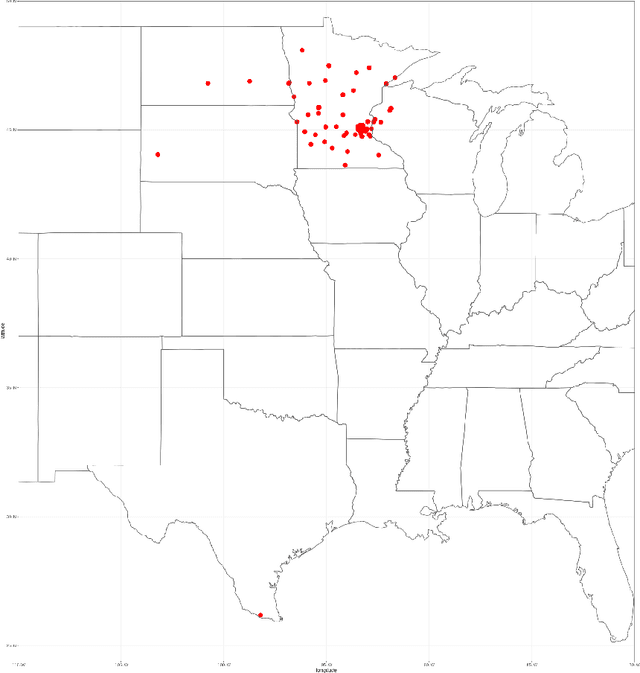
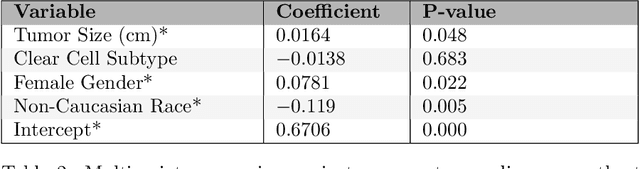
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.