 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxylessKD: Direct Knowledge Distillation with Inherited Classifier for Face Recognition
Paper and Code
Oct 31, 2020

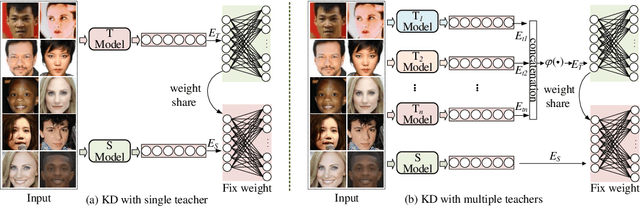
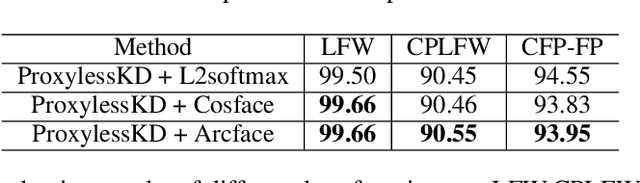
Knowledge Distillation (KD) refers to transferring knowledge from a large model to a smaller one, which is widely used to enhance model performance in machine learning. It tries to align embedding spaces generated from the teacher and the student model (i.e. to make images corresponding to the same semantics share the same embedding across different models). In this work, we focus on its application in face recognition. We observe that existing knowledge distillation models optimize the proxy tasks that force the student to mimic the teacher's behavior, instead of directly optimizing the face recognition accuracy. Consequently, the obtained student models are not guaranteed to be optimal on the target task or able to benefit from advanced constraints, such as large margin constraints (e.g. margin-based softmax). We then propose a novel method named ProxylessKD that directly optimizes face recognition accuracy by inheriting the teacher's classifier as the student's classifier to guide the student to learn discriminative embeddings in the teacher's embedding space. The proposed ProxylessKD is very easy to implement and sufficiently generic to be extended to other tasks beyond face recognition. We conduct extensive experiments on standard face recognition benchmarks, and the results demonstrate that ProxylessKD achieves superior performance over existing knowledge distillation methods.