 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecourse for reclamation: Chatting with generative language models
Mar 21, 2024
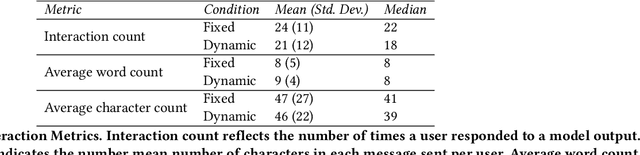


Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
Beyond Behaviorist Representational Harms: A Plan for Measurement and Mitigation
Jan 25, 2024Algorithmic harms are commonly categorized as either allocative or representational. This study specifically addresses the latter, focusing on an examination of current definitions of representational harms to discern what is included and what is not. This analysis motivates our expansion beyond behavioral definitions to encompass harms to cognitive and affective states. The paper outlines high-level requirements for measurement: identifying the necessary expertise to implement this approach and illustrating it through a case study. Our work highlights the unique vulnerabilities of large language models to perpetrating representational harms, particularly when these harms go unmeasured and unmitigated. The work concludes by presenting proposed mitigations and delineating when to employ them. The overarching aim of this research is to establish a framework for broadening the definition of representational harms and to translate insights from fairness research into practical measurement and mitigation praxis.
Fairness Vs. Personalization: Towards Equity in Epistemic Utility
Sep 05, 2023The applications of personalized recommender systems are rapidly expanding: encompassing social media, online shopping, search engine results, and more. These systems offer a more efficient way to navigate the vast array of items available. However, alongside this growth, there has been increased recognition of the potential for algorithmic systems to exhibit and perpetuate biases, risking unfairness in personalized domains. In this work, we explicate the inherent tension between personalization and conventional implementations of fairness. As an alternative, we propose equity to achieve fairness in the context of epistemic utility. We provide a mapping between goals and practical implementations and detail policy recommendations across key stakeholders to forge a path towards achieving fairness in personalized systems.
Algorithmic Censoring in Dynamic Learning Systems
May 15, 2023



Dynamic learning systems subject to selective labeling exhibit censoring, i.e. persistent negative predictions assigned to one or more subgroups of points. In applications like consumer finance, this results in groups of applicants that are persistently denied and thus never enter into the training data. In this work, we formalize censoring, demonstrate how it can arise, and highlight difficulties in detection. We consider safeguards against censoring - recourse and randomized-exploration - both of which ensure we collect labels for points that would otherwise go unobserved. The resulting techniques allow examples from censored groups to enter into the training data and correct the model. Our results highlight the otherwise unmeasured harms of censoring and demonstrate the effectiveness of mitigation strategies across a range of data generating processes.
Actionable Recourse via GANs for Mobile Health
Nov 12, 2022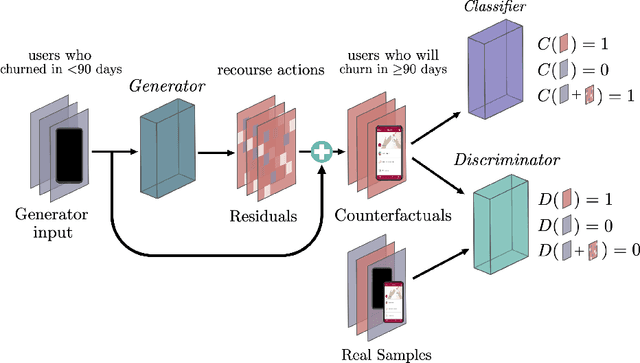

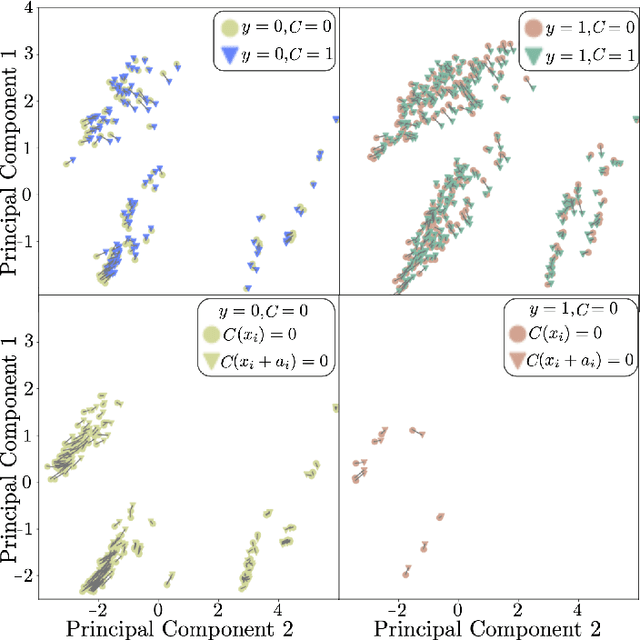
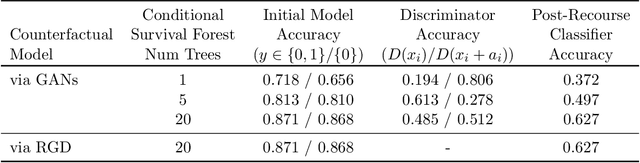
Mobile health apps provide a unique means of collecting data that can be used to deliver adaptive interventions.The predicted outcomes considerably influence the selection of such interventions. Recourse via counterfactuals provides tangible mechanisms to modify user predictions. By identifying plausible actions that increase the likelihood of a desired prediction, stakeholders are afforded agency over their predictions. Furthermore, recourse mechanisms enable counterfactual reasoning that can help provide insights into candidates for causal interventional features. We demonstrate the feasibility of GAN-generated recourse for mobile health applications on ensemble-survival-analysis-based prediction of medium-term engagement in the Safe Delivery App, a digital training tool for skilled birth attendants.