 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Generator for Adaptive Interventions in Global Health
Mar 06, 2023Artificial Intelligence and digital health have the potential to transform global health. However, having access to representative data to test and validate algorithms in realistic production environments is essential. We introduce HealthSyn, an open-source synthetic data generator of user behavior for testing reinforcement learning algorithms in the context of mobile health interventions. The generator utilizes Markov processes to generate diverse user actions, with individual user behavioral patterns that can change in reaction to personalized interventions (i.e., reminders, recommendations, and incentives). These actions are translated into actual logs using an ML-purposed data schema specific to the mobile health application functionality included with HealthKit, and open-source SDK. The logs can be fed to pipelines to obtain user metrics. The generated data, which is based on real-world behaviors and simulation techniques, can be used to develop, test, and evaluate, both ML algorithms in research and end-to-end operational RL-based intervention delivery frameworks.
Actionable Recourse via GANs for Mobile Health
Nov 12, 2022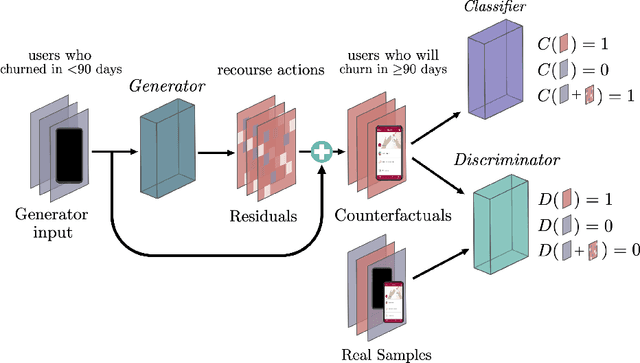

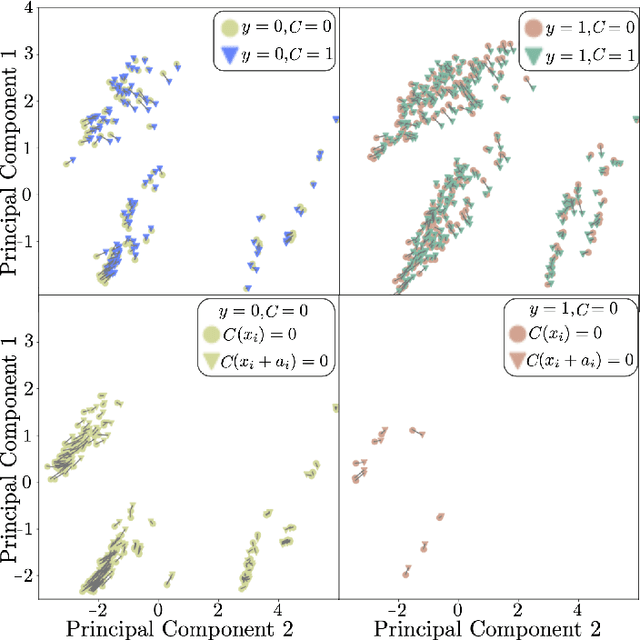
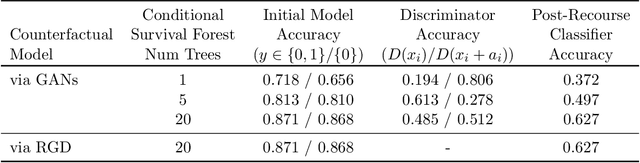
Mobile health apps provide a unique means of collecting data that can be used to deliver adaptive interventions.The predicted outcomes considerably influence the selection of such interventions. Recourse via counterfactuals provides tangible mechanisms to modify user predictions. By identifying plausible actions that increase the likelihood of a desired prediction, stakeholders are afforded agency over their predictions. Furthermore, recourse mechanisms enable counterfactual reasoning that can help provide insights into candidates for causal interventional features. We demonstrate the feasibility of GAN-generated recourse for mobile health applications on ensemble-survival-analysis-based prediction of medium-term engagement in the Safe Delivery App, a digital training tool for skilled birth attendants.
A Recommendation System to Enhance Midwives' Capacities in Low-Income Countries
Nov 04, 2021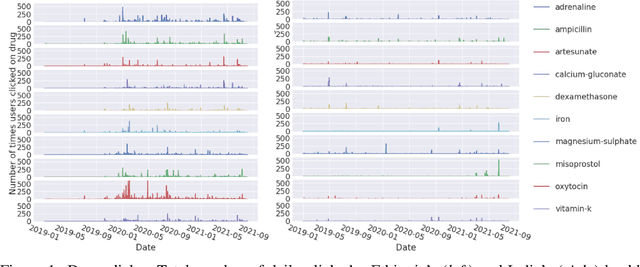
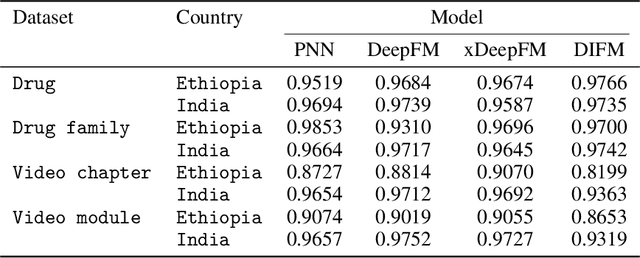
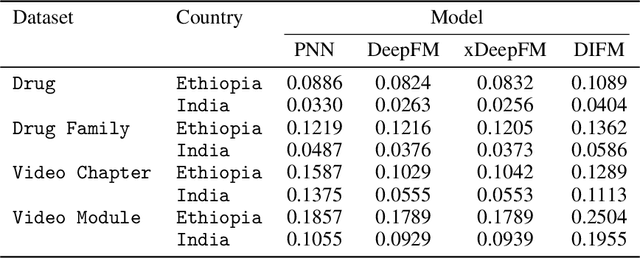
Maternal and child mortality is a public health problem that disproportionately affects low- and middle-income countries. Every day, 800 women and 6,700 newborns die from complications related to pregnancy or childbirth. And for every maternal death, about 20 women suffer serious birth injuries. However, nearly all of these deaths and negative health outcomes are preventable. Midwives are key to revert this situation, and thus it is essential to strengthen their capacities and the quality of their education. This is the aim of the Safe Delivery App, a digital job aid and learning tool to enhance the knowledge, confidence and skills of health practitioners. Here, we use the behavioral logs of the App to implement a recommendation system that presents each midwife with suitable contents to continue gaining expertise. We focus on predicting the click-through rate, the probability that a given user will click on a recommended content. We evaluate four deep learning models and show that all of them produce highly accurate predictions.
Midwifery Learning and Forecasting: Predicting Content Demand with User-Generated Logs
Jul 06, 2021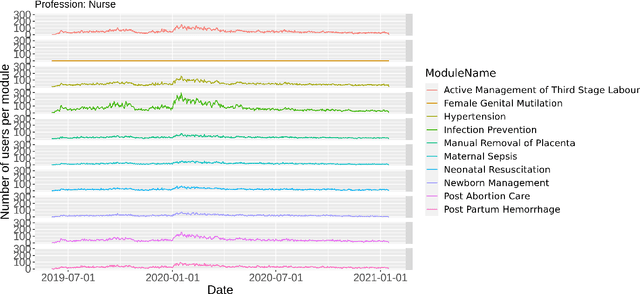
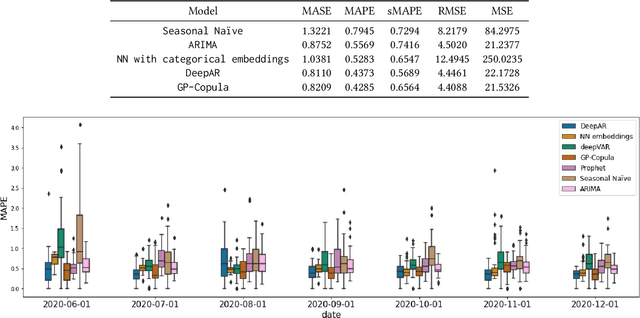
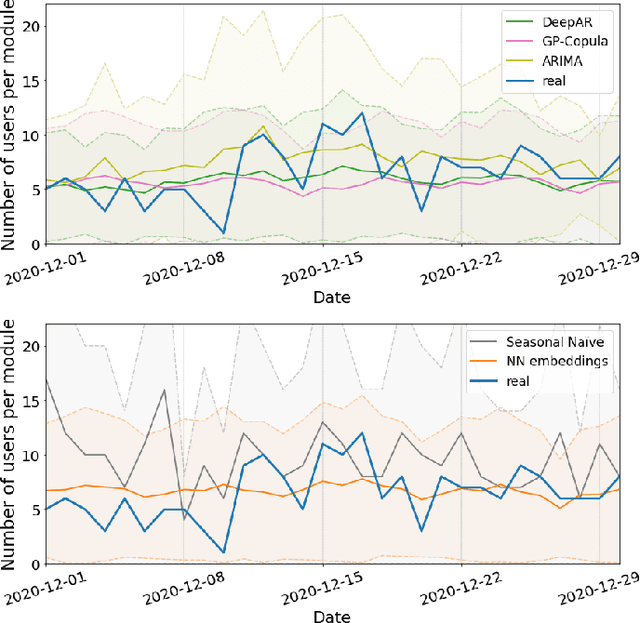
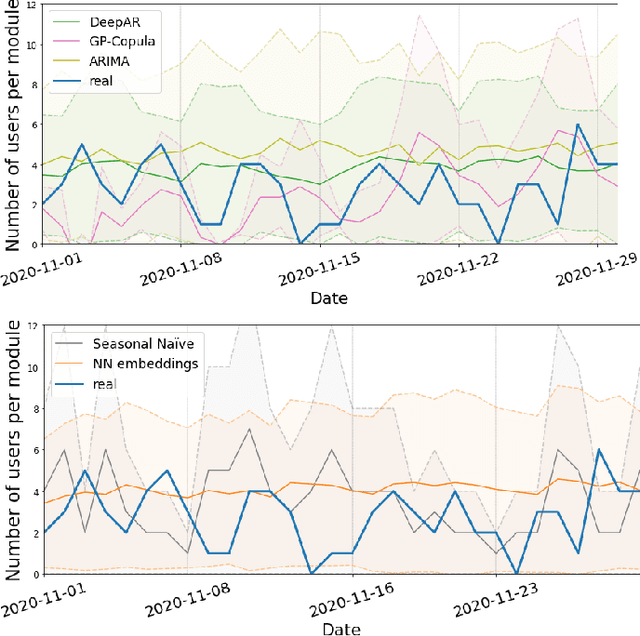
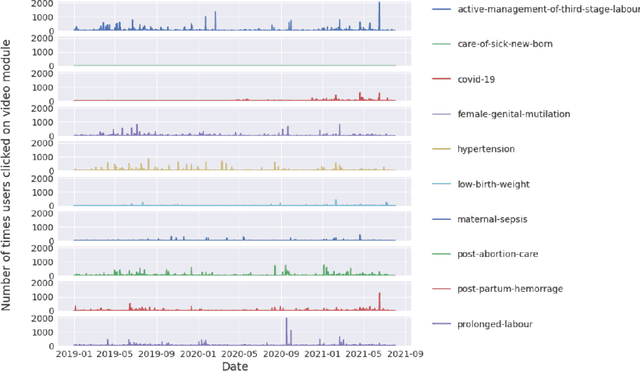
Every day, 800 women and 6,700 newborns die from complications related to pregnancy or childbirth. A well-trained midwife can prevent most of these maternal and newborn deaths. Data science models together with logs generated by users of online learning applications for midwives can help to improve their learning competencies. The goal is to use these rich behavioral data to push digital learning towards personalized content and to provide an adaptive learning journey. In this work, we evaluate various forecasting methods to determine the interest of future users on the different kind of contents available in the app, broken down by profession and region.
A Time Series Approach To Player Churn and Conversion in Videogames
Mar 13, 2020
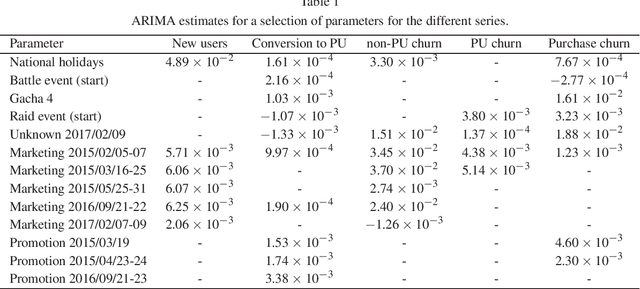


Players of a free-to-play game are divided into three main groups: non-paying active users, paying active users and inactive users. A State Space time series approach is then used to model the daily conversion rates between the different groups, i.e., the probability of transitioning from one group to another. This allows, not only for predictions on how these rates are to evolve, but also for a deeper understanding of the impact that in-game planning and calendar effects have. It is also used in this work for the detection of marketing and promotion campaigns about which no information is available. In particular, two different State Space formulations are considered and compared: an Autoregressive Integrated Moving Average process and an Unobserved Components approach, in both cases with a linear regression to explanatory variables. Both yield very close estimations for covariate parameters, producing forecasts with similar performances for most transition rates. While the Unobserved Components approach is more robust and needs less human intervention in regards to model definition, it produces significantly worse forecasts for non-paying user abandonment probability. More critically, it also fails to detect a plausible marketing and promotion campaign scenario.
Understanding Player Engagement and In-Game Purchasing Behavior with Ensemble Learning
Jul 09, 2019
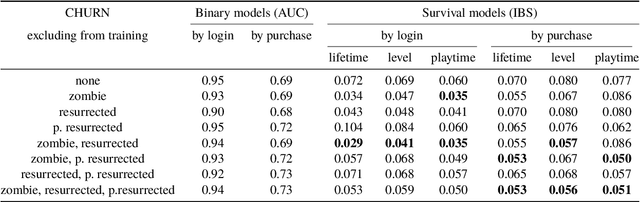
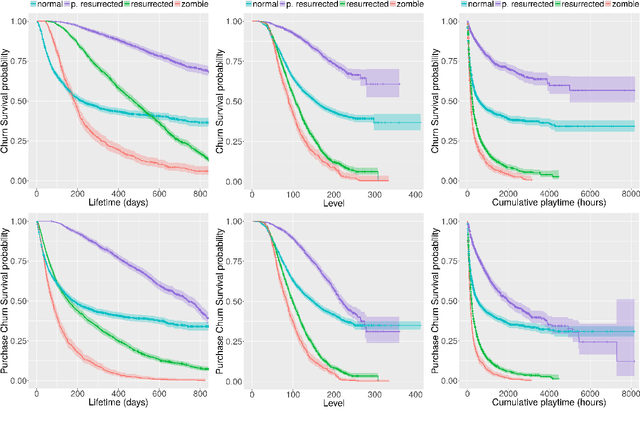
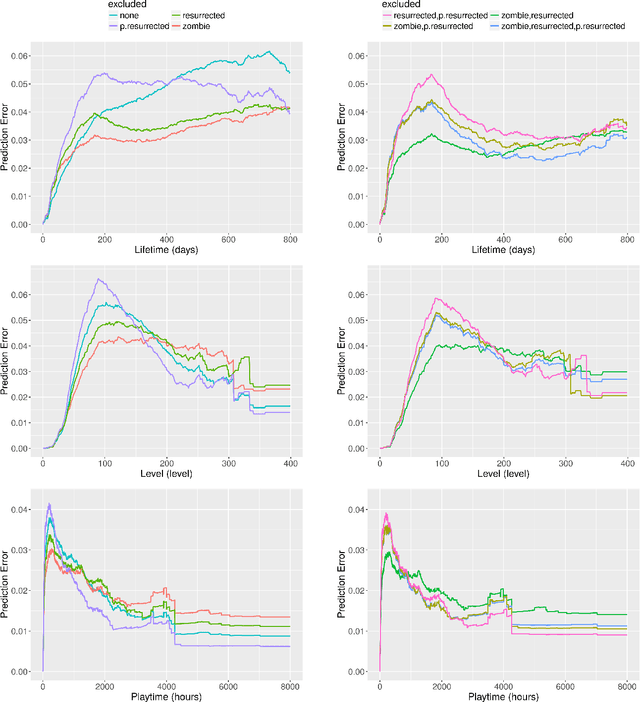
As video games attract more and more players, the major challenge for game studios is to retain them. We present a deep behavioral analysis of churn (game abandonment) and what we called "purchase churn" (the transition from paying to non-paying user). A series of churning behavior profiles are identified, which allows a classification of churners in terms of whether they eventually return to the game (false churners)--or start purchasing again (false purchase churners)--and their subsequent behavior. The impact of excluding some or all of these churners from the training sample is then explored in several churn and purchase churn prediction models. Our results suggest that discarding certain combinations of "zombies" (players whose activity is extremely sporadic) and false churners has a significant positive impact in all models considered.
From Non-Paying to Premium: Predicting User Conversion in Video Games with Ensemble Learning
Jul 01, 2019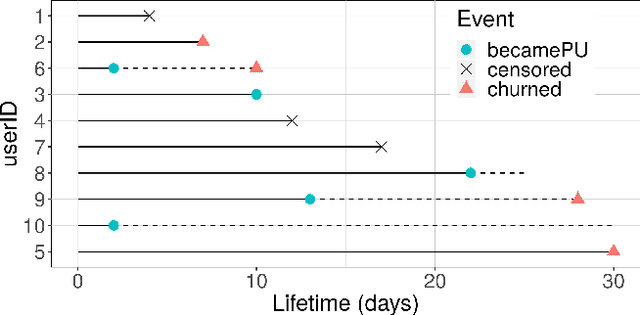
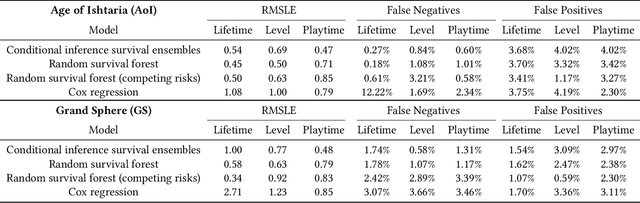
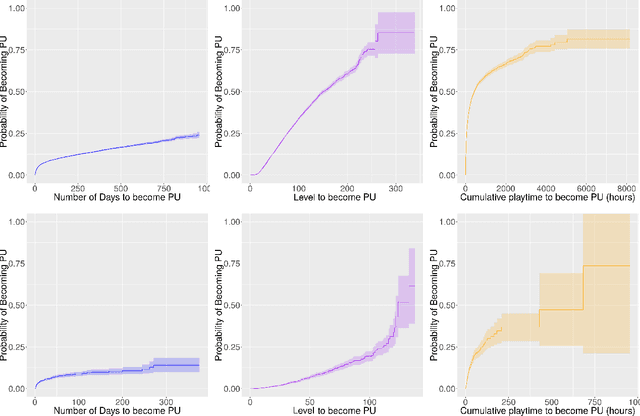
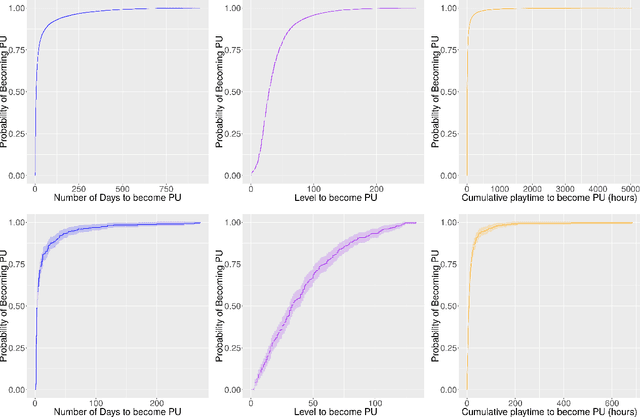
Retaining premium players is key to the success of free-to-play games, but most of them do not start purchasing right after joining the game. By exploiting the exceptionally rich datasets recorded by modern video games--which provide information on the individual behavior of each and every player--survival analysis techniques can be used to predict what players are more likely to become paying (or even premium) users and when, both in terms of time and game level, the conversion will take place. Here we show that a traditional semi-parametric model (Cox regression), a random survival forest (RSF) technique and a method based on conditional inference survival ensembles all yield very promising results. However, the last approach has the advantage of being able to correct the inherent bias in RSF models by dividing the procedure into two steps: first selecting the best predictor to perform the splitting and then the best split point for that covariate. The proposed conditional inference survival ensembles method could be readily used in operational environments for early identification of premium players and the parts of the game that may prompt them to become paying users. Such knowledge would allow developers to induce their conversion and, more generally, to better understand the needs of their players and provide them with a personalized experience, thereby increasing their engagement and paving the way to higher monetization.
The Winning Solution to the IEEE CIG 2017 Game Data Mining Competition
Jan 16, 2019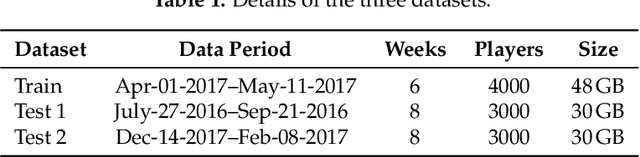
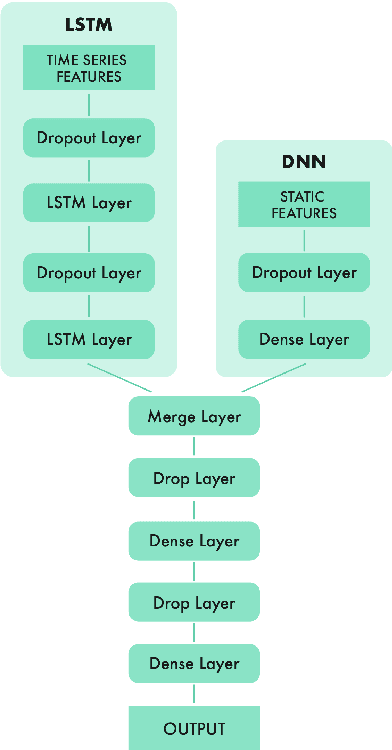

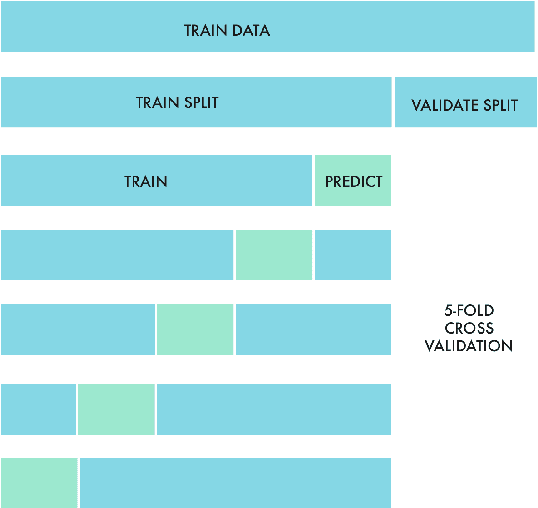
Machine learning competitions such as those organized by Kaggle or KDD represent a useful benchmark for data science research. In this work, we present our winning solution to the Game Data Mining competition hosted at the 2017 IEEE Conference on Computational Intelligence and Games (CIG 2017). The contest consisted of two tracks, and participants (more than 250, belonging to both industry and academia) were to predict which players would stop playing the game, as well as their remaining lifetime. The data were provided by a major worldwide video game company, NCSoft, and came from their successful massively multiplayer online game Blade and Soul. Here, we describe the long short-term memory approach and conditional inference survival ensemble model that made us win both tracks of the contest, as well as the validation procedure that we followed in order to prevent overfitting. In particular, choosing a survival method able to deal with censored data was crucial to accurately predict the moment in which each player would leave the game, as censoring is inherent in churn. The selected models proved to be robust against evolving conditions---since there was a change in the business model of the game (from subscription-based to free-to-play) between the two sample datasets provided---and efficient in terms of time cost. Thanks to these features and also to their a ability to scale to large datasets, our models could be readily implemented in real business settings.
Customer Lifetime Value in Video Games Using Deep Learning and Parametric Models
Nov 28, 2018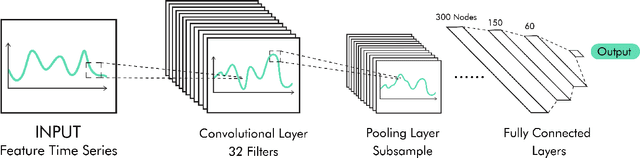


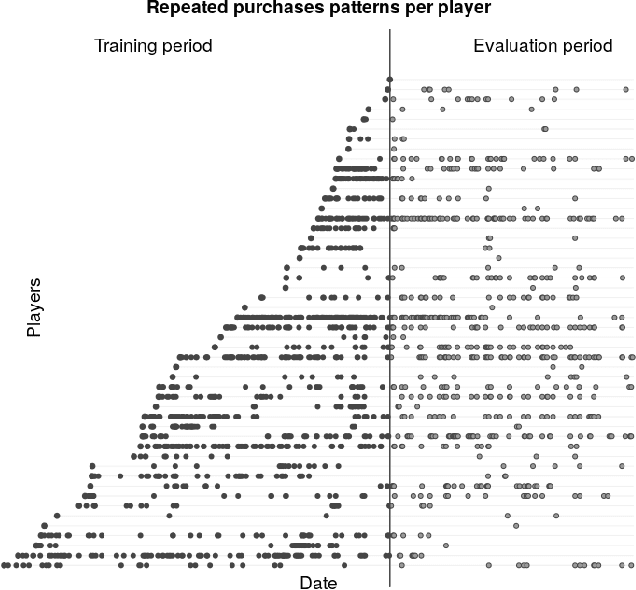
Nowadays, video game developers record every virtual action performed by their players. As each player can remain in the game for years, this results in an exceptionally rich dataset that can be used to understand and predict player behavior. In particular, this information may serve to identify the most valuable players and foresee the amount of money they will spend in in-app purchases during their lifetime. This is crucial in free-to-play games, where up to 50% of the revenue is generated by just around 2% of the players, the so-called whales. To address this challenge, we explore how deep neural networks can be used to predict customer lifetime value in video games, and compare their performance to parametric models such as Pareto/NBD. Our results suggest that convolutional neural network structures are the most efficient in predicting the economic value of individual players. They not only perform better in terms of accuracy, but also scale to big data and significantly reduce computational time, as they can work directly with raw sequential data and thus do not require any feature engineering process. This becomes important when datasets are very large, as is often the case with video game logs. Moreover, convolutional neural networks are particularly well suited to identify potential whales. Such an early identification is of paramount importance for business purposes, as it would allow developers to implement in-game actions aimed at retaining big spenders and maximizing their lifetime, which would ultimately translate into increased revenue.
A Machine-Learning Item Recommendation System for Video Games
Aug 14, 2018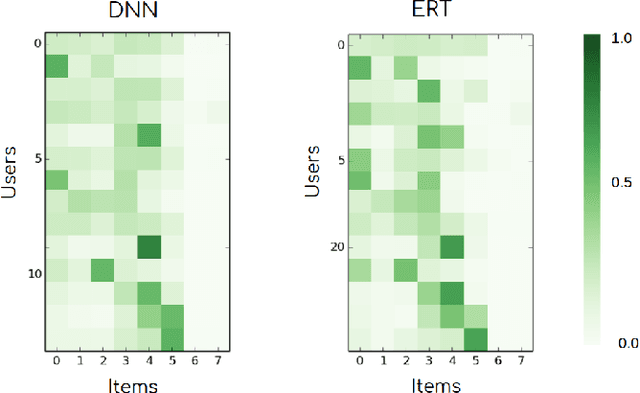
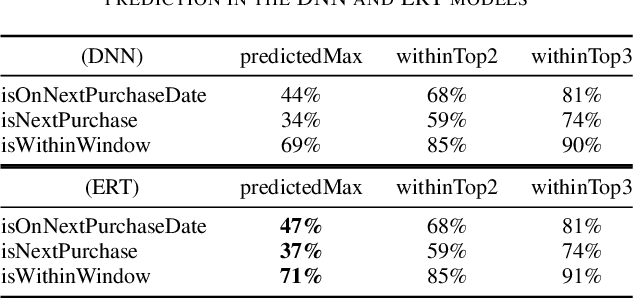
Video-game players generate huge amounts of data, as everything they do within a game is recorded. In particular, among all the stored actions and behaviors, there is information on the in-game purchases of virtual products. Such information is of critical importance in modern free-to-play titles, where gamers can select or buy a profusion of items during the game in order to progress and fully enjoy their experience. To try to maximize these kind of purchases, one can use a recommendation system so as to present players with items that might be interesting for them. Such systems can better achieve their goal by employing machine learning algorithms that are able to predict the rating of an item or product by a particular user. In this paper we evaluate and compare two of these algorithms, an ensemble-based model (extremely randomized trees) and a deep neural network, both of which are promising candidates for operational video-game recommender engines. Item recommenders can help developers improve the game. But, more importantly, it should be possible to integrate them into the game, so that users automatically get personalized recommendations while playing. The presented models are not only able to meet this challenge, providing accurate predictions of the items that a particular player will find attractive, but also sufficiently fast and robust to be used in operational settings.