 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork of Evolvable Neural Units: Evolving to Learn at a Synaptic Level
Dec 16, 2019



Although Deep Neural Networks have seen great success in recent years through various changes in overall architectures and optimization strategies, their fundamental underlying design remains largely unchanged. Computational neuroscience on the other hand provides more biologically realistic models of neural processing mechanisms, but they are still high level abstractions of the actual experimentally observed behaviour. Here a model is proposed that bridges Neuroscience, Machine Learning and Evolutionary Algorithms to evolve individual soma and synaptic compartment models of neurons in a scalable manner. Instead of attempting to manually derive models for all the observed complexity and diversity in neural processing, we propose an Evolvable Neural Unit (ENU) that can approximate the function of each individual neuron and synapse. We demonstrate that this type of unit can be evolved to mimic Integrate-And-Fire neurons and synaptic Spike-Timing-Dependent Plasticity. Additionally, by constructing a new type of neural network where each synapse and neuron is such an evolvable neural unit, we show it is possible to evolve an agent capable of learning to solve a T-maze environment task. This network independently discovers spiking dynamics and reinforcement type learning rules, opening up a new path towards biologically inspired artificial intelligence.
A Machine-Learning Item Recommendation System for Video Games
Aug 14, 2018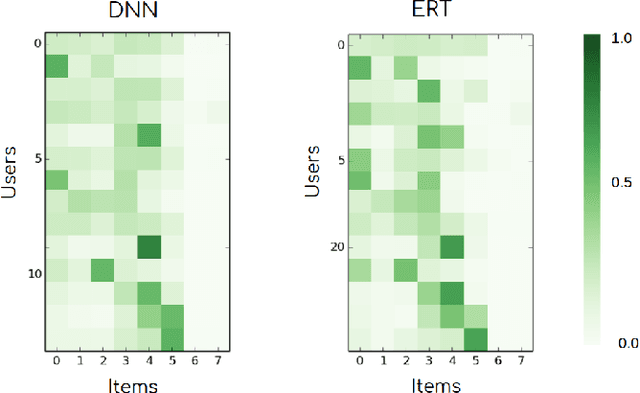
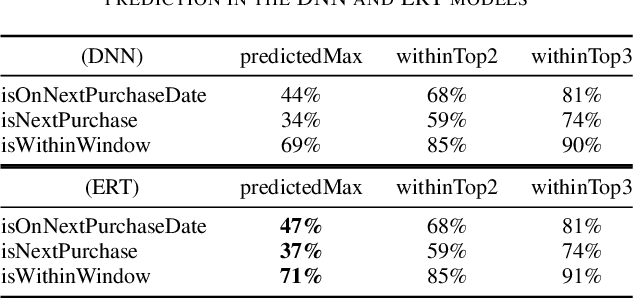
Video-game players generate huge amounts of data, as everything they do within a game is recorded. In particular, among all the stored actions and behaviors, there is information on the in-game purchases of virtual products. Such information is of critical importance in modern free-to-play titles, where gamers can select or buy a profusion of items during the game in order to progress and fully enjoy their experience. To try to maximize these kind of purchases, one can use a recommendation system so as to present players with items that might be interesting for them. Such systems can better achieve their goal by employing machine learning algorithms that are able to predict the rating of an item or product by a particular user. In this paper we evaluate and compare two of these algorithms, an ensemble-based model (extremely randomized trees) and a deep neural network, both of which are promising candidates for operational video-game recommender engines. Item recommenders can help developers improve the game. But, more importantly, it should be possible to integrate them into the game, so that users automatically get personalized recommendations while playing. The presented models are not only able to meet this challenge, providing accurate predictions of the items that a particular player will find attractive, but also sufficiently fast and robust to be used in operational settings.
Games and Big Data: A Scalable Multi-Dimensional Churn Prediction Model
Oct 06, 2017



The emergence of mobile games has caused a paradigm shift in the video-game industry. Game developers now have at their disposal a plethora of information on their players, and thus can take advantage of reliable models that can accurately predict player behavior and scale to huge datasets. Churn prediction, a challenge common to a variety of sectors, is particularly relevant for the mobile game industry, as player retention is crucial for the successful monetization of a game. In this article, we present an approach to predicting game abandon based on survival ensembles. Our method provides accurate predictions on both the level at which each player will leave the game and their accumulated playtime until that moment. Further, it is robust to different data distributions and applicable to a wide range of response variables, while also allowing for efficient parallelization of the algorithm. This makes our model well suited to perform real-time analyses of churners, even for games with millions of daily active users.
Forecasting Player Behavioral Data and Simulating in-Game Events
Oct 05, 2017
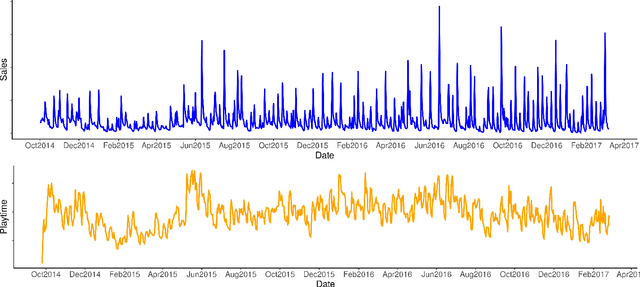
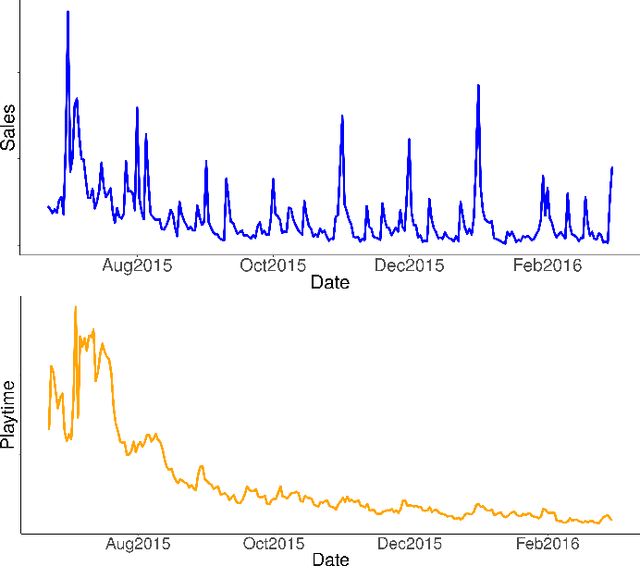
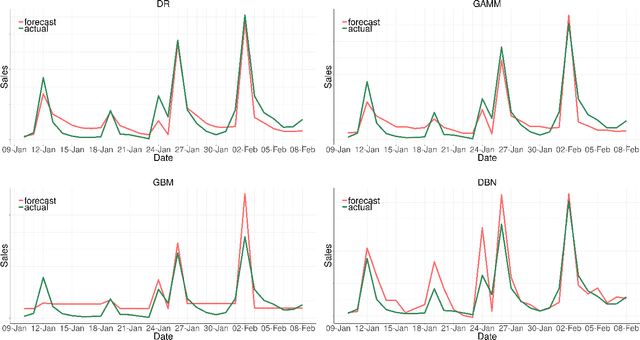
Understanding player behavior is fundamental in game data science. Video games evolve as players interact with the game, so being able to foresee player experience would help to ensure a successful game development. In particular, game developers need to evaluate beforehand the impact of in-game events. Simulation optimization of these events is crucial to increase player engagement and maximize monetization. We present an experimental analysis of several methods to forecast game-related variables, with two main aims: to obtain accurate predictions of in-app purchases and playtime in an operational production environment, and to perform simulations of in-game events in order to maximize sales and playtime. Our ultimate purpose is to take a step towards the data-driven development of games. The results suggest that, even though the performance of traditional approaches such as ARIMA is still better, the outcomes of state-of-the-art techniques like deep learning are promising. Deep learning comes up as a well-suited general model that could be used to forecast a variety of time series with different dynamic behaviors.
Rank Ordered Autoencoders
May 05, 2016



A new method for the unsupervised learning of sparse representations using autoencoders is proposed and implemented by ordering the output of the hidden units by their activation value and progressively reconstructing the input in this order. This can be done efficiently in parallel with the use of cumulative sums and sorting only slightly increasing the computational costs. Minimizing the difference of this progressive reconstruction with respect to the input can be seen as minimizing the number of active output units required for the reconstruction of the input. The model thus learns to reconstruct optimally using the least number of active output units. This leads to high sparsity without the need for extra hyperparameters, the amount of sparsity is instead implicitly learned by minimizing this progressive reconstruction error. Results of the trained model are given for patches of the CIFAR10 dataset, showing rapid convergence of features and extremely sparse output activations while maintaining a minimal reconstruction error and showing extreme robustness to overfitting. Additionally the reconstruction as function of number of active units is presented which shows the autoencoder learns a rank order code over the input where the highest ranked units correspond to the highest decrease in reconstruction error.