 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Regression for Distributional Reward Models in RLHF
Sep 16, 2024Reinforcement learning from human feedback (RLHF) has become a key method for aligning large language models (LLMs) with human preferences through the use of reward models. However, traditional reward models typically generate point estimates, which oversimplify the diversity and complexity of human values and preferences. In this paper, we introduce Quantile Reward Models (QRMs), a novel approach to reward modeling that learns a distribution over rewards instead of a single scalar value. Our method uses quantile regression to estimate a full, potentially multimodal distribution over preferences, providing a more powerful and nuanced representation of preferences. This distributional approach can better capture the diversity of human values, addresses label noise, and accommodates conflicting preferences by modeling them as distinct modes in the distribution. Our experimental results show that QRM outperforms comparable traditional point-estimate models on RewardBench. Furthermore, we demonstrate that the additional information provided by the distributional estimates can be utilized in downstream applications, such as risk-aware reinforcement learning, resulting in LLM policies that generate fewer extremely negative responses. Our code and model are released at https://github.com/Nicolinho/QRM.
Training a Vision Language Model as Smartphone Assistant
Apr 12, 2024


Addressing the challenge of a digital assistant capable of executing a wide array of user tasks, our research focuses on the realm of instruction-based mobile device control. We leverage recent advancements in large language models (LLMs) and present a visual language model (VLM) that can fulfill diverse tasks on mobile devices. Our model functions by interacting solely with the user interface (UI). It uses the visual input from the device screen and mimics human-like interactions, encompassing gestures such as tapping and swiping. This generality in the input and output space allows our agent to interact with any application on the device. Unlike previous methods, our model operates not only on a single screen image but on vision-language sentences created from sequences of past screenshots along with corresponding actions. Evaluating our method on the challenging Android in the Wild benchmark demonstrates its promising efficacy and potential.
Improving Deep Dynamics Models for Autonomous Vehicles with Multimodal Latent Mapping of Surfaces
Mar 21, 2023



The safe deployment of autonomous vehicles relies on their ability to effectively react to environmental changes. This can require maneuvering on varying surfaces which is still a difficult problem, especially for slippery terrains. To address this issue we propose a new approach that learns a surface-aware dynamics model by conditioning it on a latent variable vector storing surface information about the current location. A latent mapper is trained to update these latent variables during inference from multiple modalities on every traversal of the corresponding locations and stores them in a map. By training everything end-to-end with the loss of the dynamics model, we enforce the latent mapper to learn an update rule for the latent map that is useful for the subsequent dynamics model. We implement and evaluate our approach on a real miniature electric car. The results show that the latent map is updated to allow more accurate predictions of the dynamics model compared to a model without this information. We further show that by using this model, the driving performance can be improved on varying and challenging surfaces.
Dynamic Update-to-Data Ratio: Minimizing World Model Overfitting
Mar 17, 2023Early stopping based on the validation set performance is a popular approach to find the right balance between under- and overfitting in the context of supervised learning. However, in reinforcement learning, even for supervised sub-problems such as world model learning, early stopping is not applicable as the dataset is continually evolving. As a solution, we propose a new general method that dynamically adjusts the update to data (UTD) ratio during training based on under- and overfitting detection on a small subset of the continuously collected experience not used for training. We apply our method to DreamerV2, a state-of-the-art model-based reinforcement learning algorithm, and evaluate it on the DeepMind Control Suite and the Atari $100$k benchmark. The results demonstrate that one can better balance under- and overestimation by adjusting the UTD ratio with our approach compared to the default setting in DreamerV2 and that it is competitive with an extensive hyperparameter search which is not feasible for many applications. Our method eliminates the need to set the UTD hyperparameter by hand and even leads to a higher robustness with regard to other learning-related hyperparameters further reducing the amount of necessary tuning.
Adaptively Calibrated Critic Estimates for Deep Reinforcement Learning
Nov 24, 2021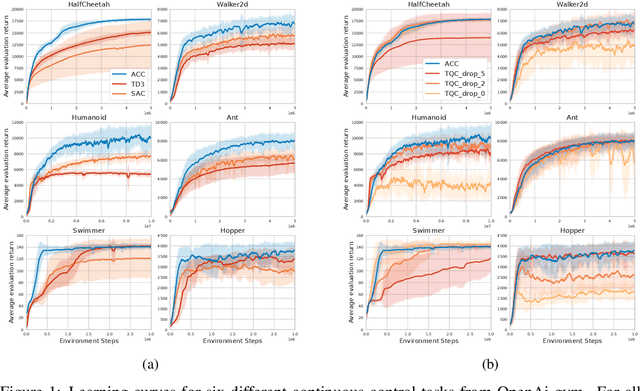
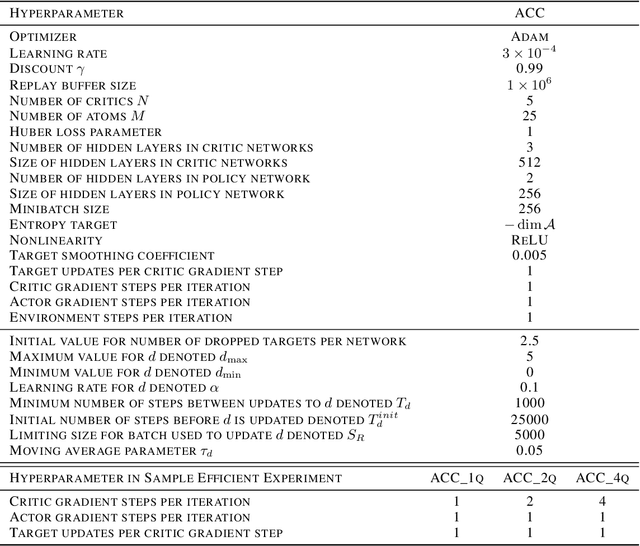
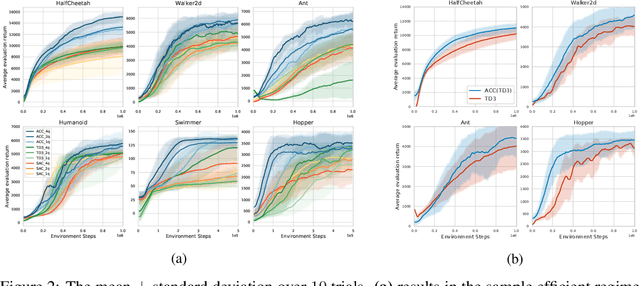
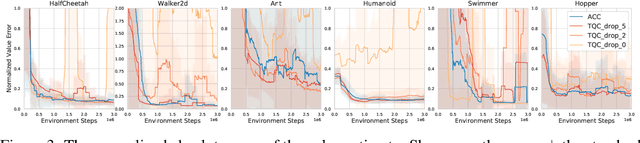
Accurate value estimates are important for off-policy reinforcement learning. Algorithms based on temporal difference learning typically are prone to an over- or underestimation bias building up over time. In this paper, we propose a general method called Adaptively Calibrated Critics (ACC) that uses the most recent high variance but unbiased on-policy rollouts to alleviate the bias of the low variance temporal difference targets. We apply ACC to Truncated Quantile Critics, which is an algorithm for continuous control that allows regulation of the bias with a hyperparameter tuned per environment. The resulting algorithm adaptively adjusts the parameter during training rendering hyperparameter search unnecessary and sets a new state of the art on the OpenAI gym continuous control benchmark among all algorithms that do not tune hyperparameters for each environment. Additionally, we demonstrate that ACC is quite general by further applying it to TD3 and showing an improved performance also in this setting.
Modality-Buffet for Real-Time Object Detection
Nov 17, 2020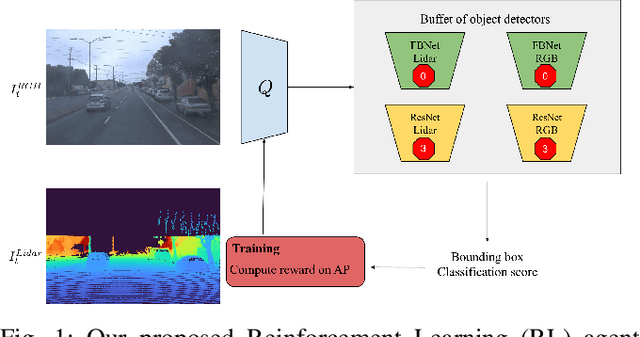
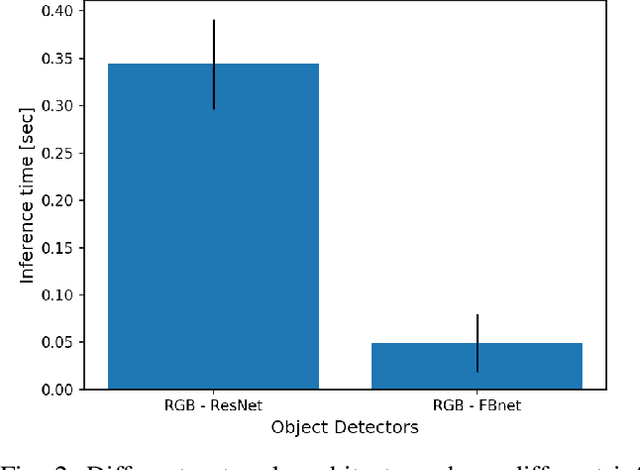
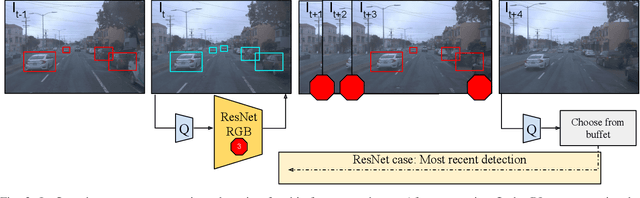
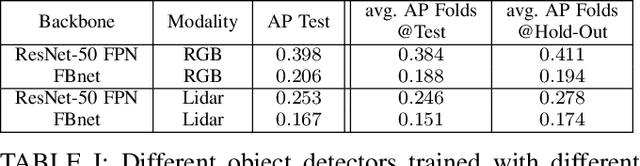
Real-time object detection in videos using lightweight hardware is a crucial component of many robotic tasks. Detectors using different modalities and with varying computational complexities offer different trade-offs. One option is to have a very lightweight model that can predict from all modalities at once for each frame. However, in some situations (e.g., in static scenes) it might be better to have a more complex but more accurate model and to extrapolate from previous predictions for the frames coming in at processing time. We formulate this task as a sequential decision making problem and use reinforcement learning (RL) to generate a policy that decides from the RGB input which detector out of a portfolio of different object detectors to take for the next prediction. The objective of the RL agent is to maximize the accuracy of the predictions per image. We evaluate the approach on the Waymo Open Dataset and show that it exceeds the performance of each single detector.
Scaling Imitation Learning in Minecraft
Jul 06, 2020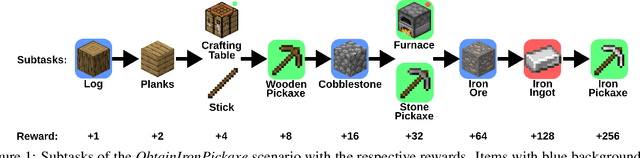

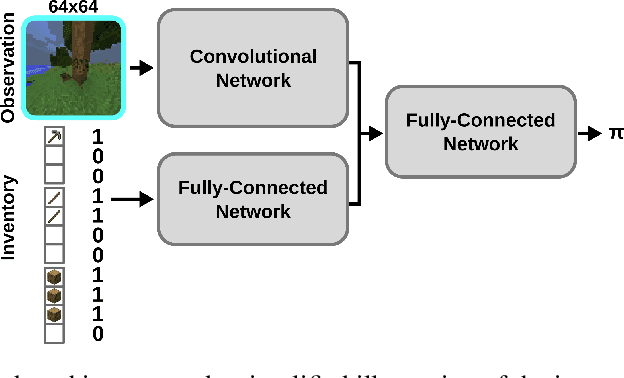
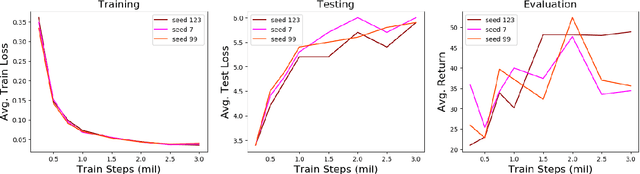
Imitation learning is a powerful family of techniques for learning sensorimotor coordination in immersive environments. We apply imitation learning to attain state-of-the-art performance on hard exploration problems in the Minecraft environment. We report experiments that highlight the influence of network architecture, loss function, and data augmentation. An early version of our approach reached second place in the MineRL competition at NeurIPS 2019. Here we report stronger results that can be used as a starting point for future competition entries and related research. Our code is available at https://github.com/amiranas/minerl_imitation_learning.
Scheduled Intrinsic Drive: A Hierarchical Take on Intrinsically Motivated Exploration
Mar 18, 2019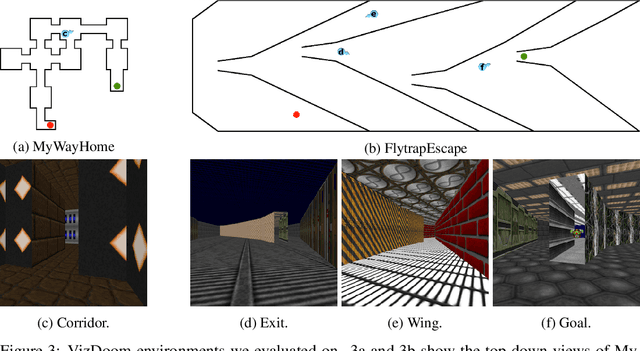
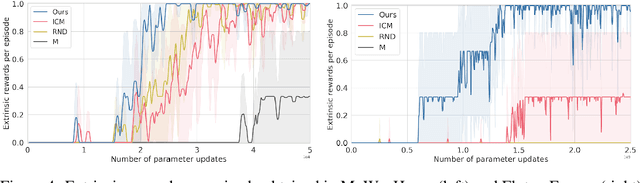


Exploration in sparse reward reinforcement learning remains a difficult open challenge. Many state-of-the-art methods use intrinsic motivation to complement the sparse extrinsic reward signal, giving the agent more opportunities to receive feedback during exploration. Most commonly, these signals are added as bonus rewards, which results in the mixture policy faithfully conducting neither exploration nor task fulfillment for an extended amount of time. In this paper, we instead learn separate intrinsic and extrinsic task policies and schedule between these different drives to accelerate exploration and stabilize learning. Moreover, we introduce a new type of intrinsic reward denoted as successor feature control (SFC), which is general and not task-specific. It takes into account statistics over complete trajectories and thus differs from previous methods that only use local information to evaluate intrinsic motivation. We evaluate our proposed scheduled intrinsic drive (SID) agent using three different environments with pure visual inputs: VizDoom, DeepMind Lab and OpenAI Gym classic control from pixels. The results show a greatly improved exploration efficiency with SFC and the hierarchical usage of the intrinsic drives. A video of our experimental results can be found at https://youtu.be/4ZHcBo7006Y.