 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Buffet for Real-Time Object Detection
Paper and Code
Nov 17, 2020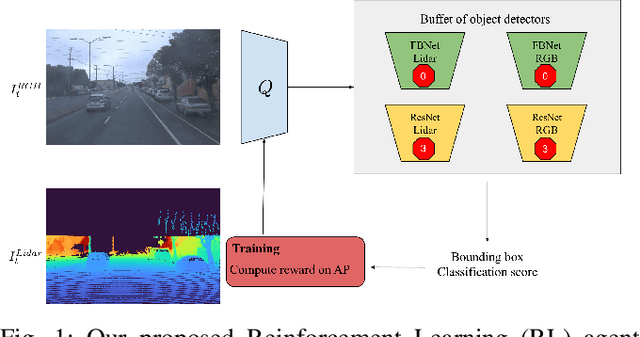
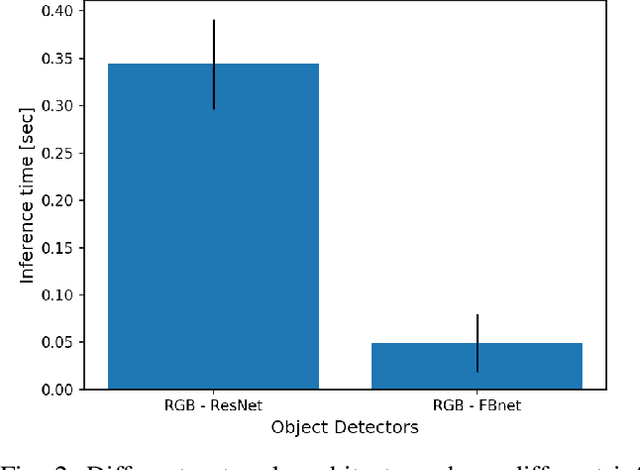
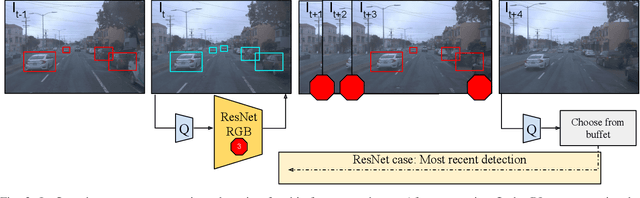
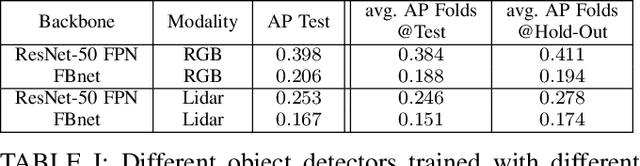
Real-time object detection in videos using lightweight hardware is a crucial component of many robotic tasks. Detectors using different modalities and with varying computational complexities offer different trade-offs. One option is to have a very lightweight model that can predict from all modalities at once for each frame. However, in some situations (e.g., in static scenes) it might be better to have a more complex but more accurate model and to extrapolate from previous predictions for the frames coming in at processing time. We formulate this task as a sequential decision making problem and use reinforcement learning (RL) to generate a policy that decides from the RGB input which detector out of a portfolio of different object detectors to take for the next prediction. The objective of the RL agent is to maximize the accuracy of the predictions per image. We evaluate the approach on the Waymo Open Dataset and show that it exceeds the performance of each single detector.