 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and a Baseline for Robust Multi-view Depth Estimation
Sep 13, 2022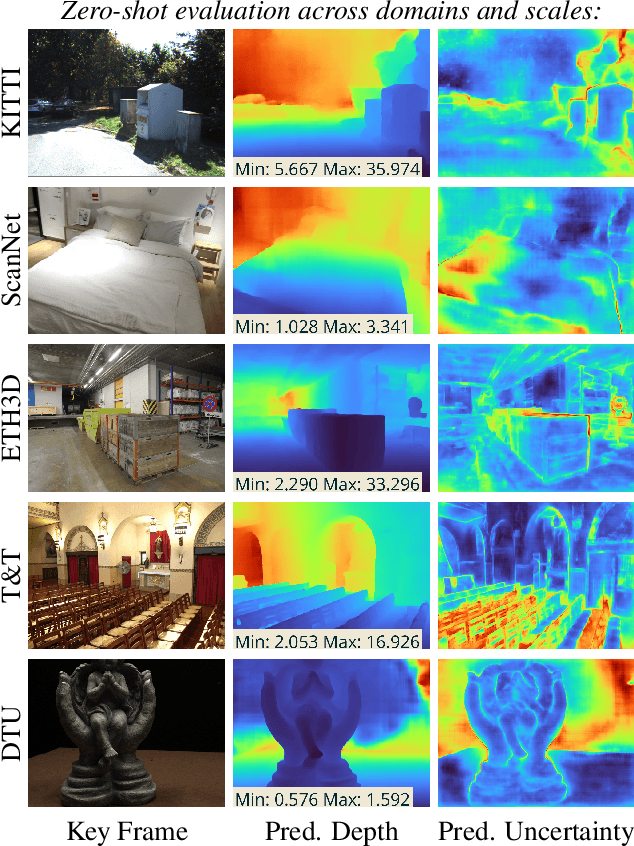
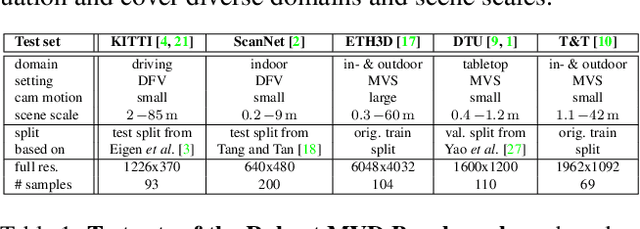

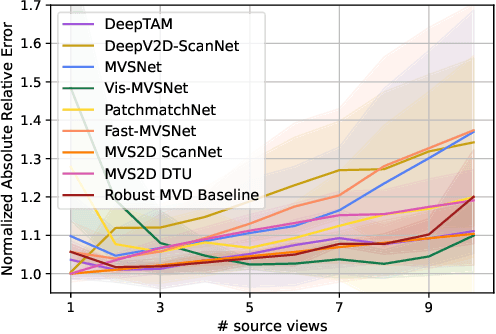
Recent deep learning approaches for multi-view depth estimation are employed either in a depth-from-video or a multi-view stereo setting. Despite different settings, these approaches are technically similar: they correlate multiple source views with a keyview to estimate a depth map for the keyview. In this work, we introduce the Robust Multi-View Depth Benchmark that is built upon a set of public datasets and allows evaluation in both settings on data from different domains. We evaluate recent approaches and find imbalanced performances across domains. Further, we consider a third setting, where camera poses are available and the objective is to estimate the corresponding depth maps with their correct scale. We show that recent approaches do not generalize across datasets in this setting. This is because their cost volume output runs out of distribution. To resolve this, we present the Robust MVD Baseline model for multi-view depth estimation, which is built upon existing components but employs a novel scale augmentation procedure. It can be applied for robust multi-view depth estimation, independent of the target data. We provide code for the proposed benchmark and baseline model at https://github.com/lmb-freiburg/robustmvd.
Pre-training of Deep RL Agents for Improved Learning under Domain Randomization
Apr 29, 2021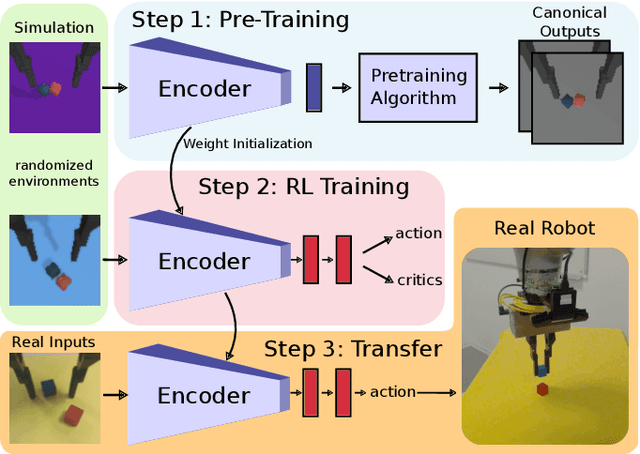

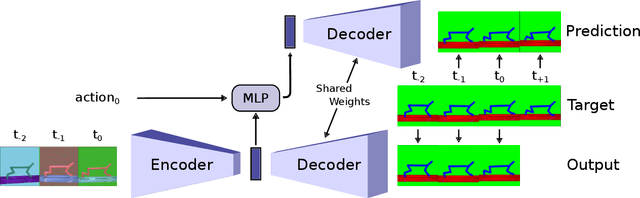
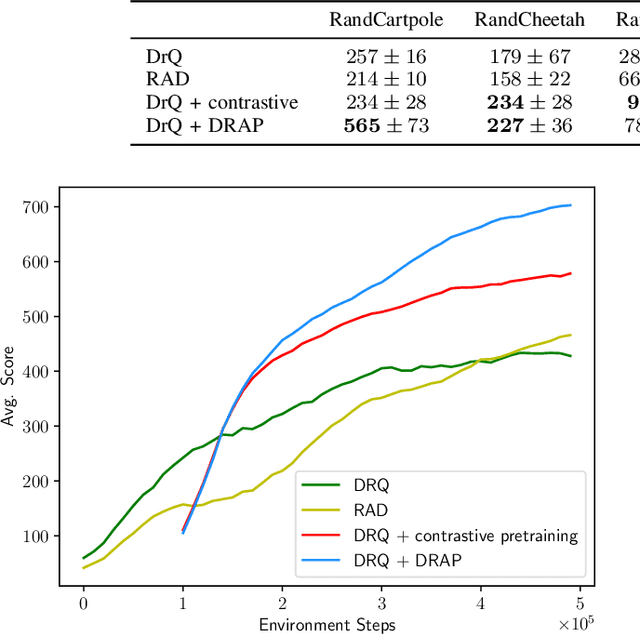
Visual domain randomization in simulated environments is a widely used method to transfer policies trained in simulation to real robots. However, domain randomization and augmentation hamper the training of a policy. As reinforcement learning struggles with a noisy training signal, this additional nuisance can drastically impede training. For difficult tasks it can even result in complete failure to learn. To overcome this problem we propose to pre-train a perception encoder that already provides an embedding invariant to the randomization. We demonstrate that this yields consistently improved results on a randomized version of DeepMind control suite tasks and a stacking environment on arbitrary backgrounds with zero-shot transfer to a physical robot.
Scaling Imitation Learning in Minecraft
Jul 06, 2020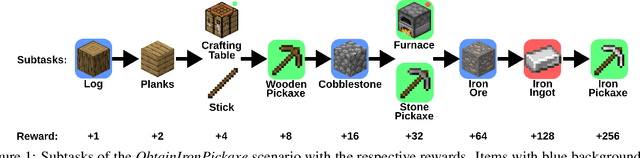

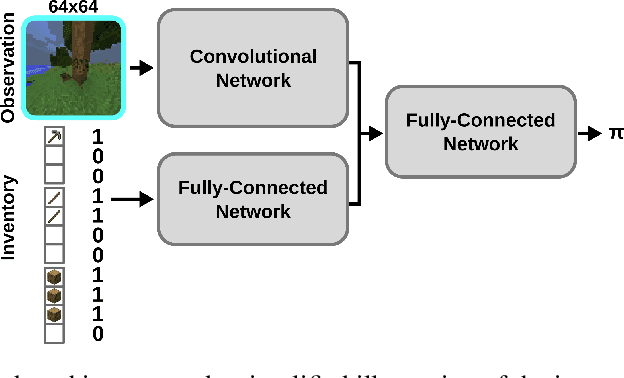
Imitation learning is a powerful family of techniques for learning sensorimotor coordination in immersive environments. We apply imitation learning to attain state-of-the-art performance on hard exploration problems in the Minecraft environment. We report experiments that highlight the influence of network architecture, loss function, and data augmentation. An early version of our approach reached second place in the MineRL competition at NeurIPS 2019. Here we report stronger results that can be used as a starting point for future competition entries and related research. Our code is available at https://github.com/amiranas/minerl_imitation_learning.
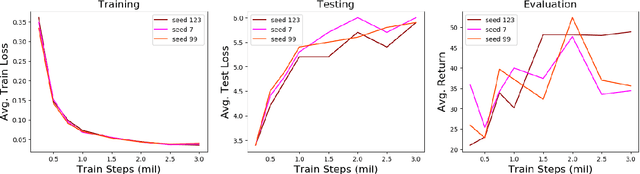
Adaptive Curriculum Generation from Demonstrations for Sim-to-Real Visuomotor Control
Oct 31, 2019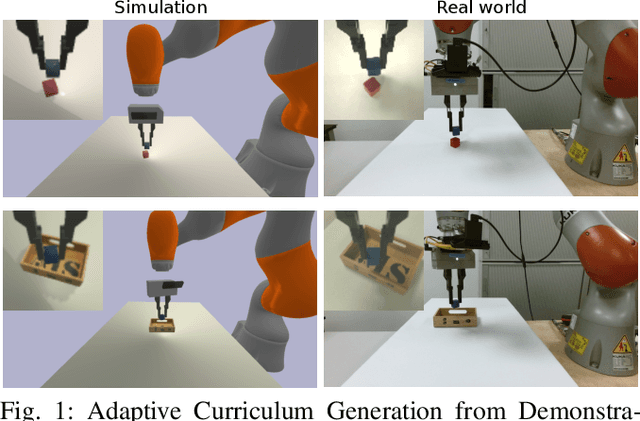
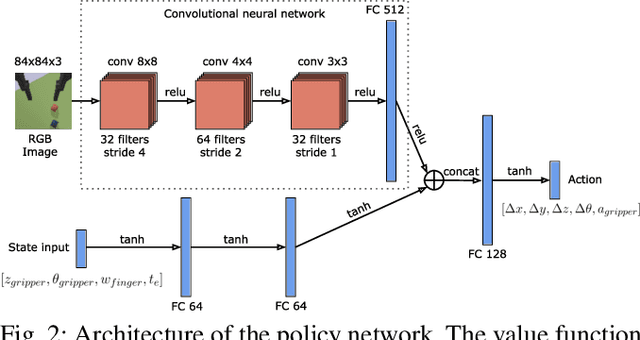
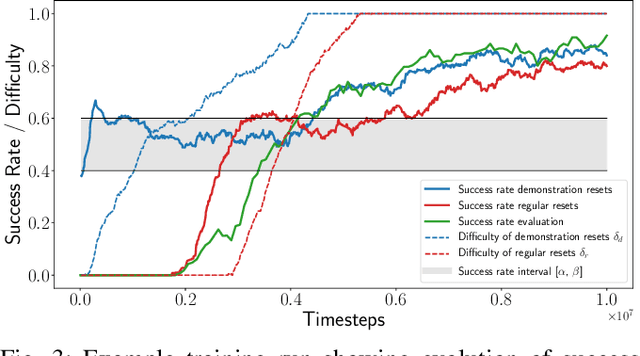
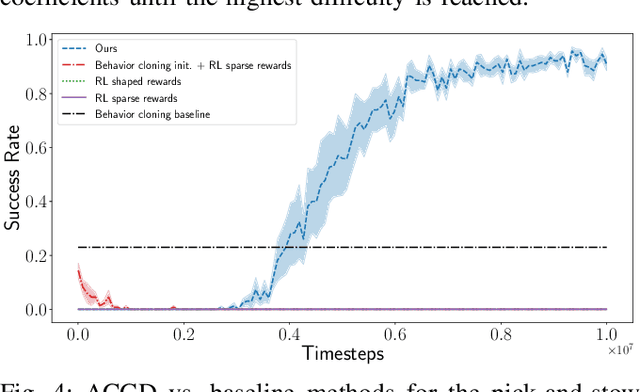
We propose Adaptive Curriculum Generation from Demonstrations (ACGD) for reinforcement learning in the presence of sparse rewards. Rather than designing shaped reward functions, ACGD adaptively sets the appropriate task difficulty for the learner by controlling where to sample from the demonstration trajectories and which set of simulation parameters to use. We show that training vision-based control policies in simulation while gradually increasing the difficulty of the task via ACGD improves the policy transfer to the real world. The degree of domain randomization is also gradually increased through the task difficulty. We demonstrate zero-shot transfer for two real-world manipulation tasks: pick-and-stow and block stacking. A video showing the results can be found at https://lmb.informatik.uni-freiburg.de/projects/curriculum/
CrossNorm: Normalization for Off-Policy TD Reinforcement Learning
Feb 14, 2019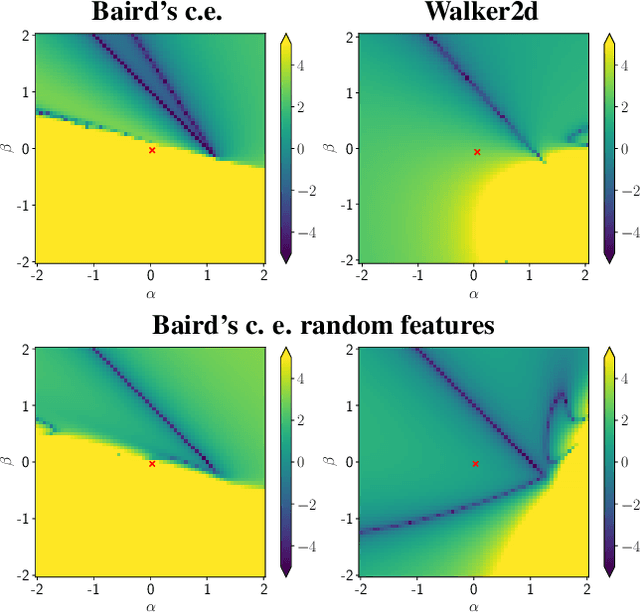
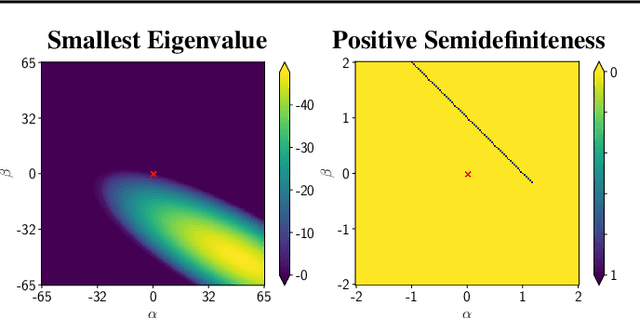
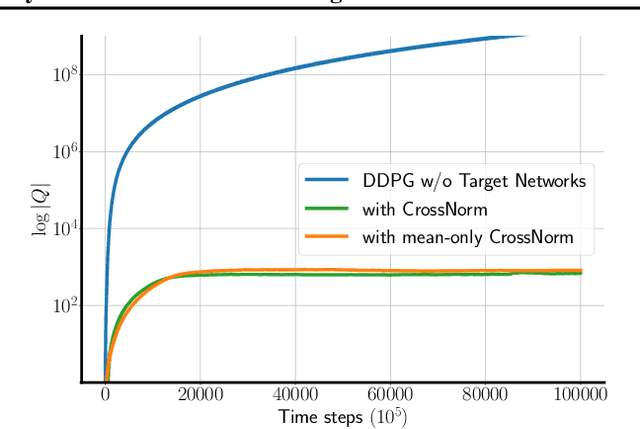
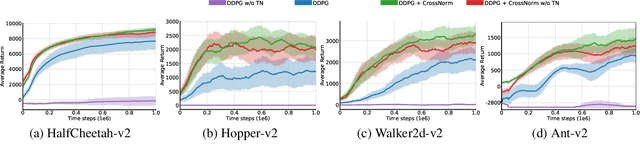
Off-policy Temporal Difference (TD) learning methods, when combined with function approximators, suffer from the risk of divergence, a phenomenon known as the deadly triad. It has long been noted that some feature representations work better than others. In this paper we investigate how feature normalization can prevent divergence and improve training. Our method, which we call CrossNorm, can be regarded as a new variant of batch normalization that re-centers data for multi-modal distributions, which occur in the off-policy TD updates. We show empirically that CrossNorm improves the stability of the learning process. We apply CrossNorm to DDPG and TD3 and achieve stable training and improved performance across a range of MuJoCo benchmark tasks. Moreover, for the first time, we are able to train DDPG stably without the use of target networks.
Motion Perception in Reinforcement Learning with Dynamic Objects
Jan 10, 2019
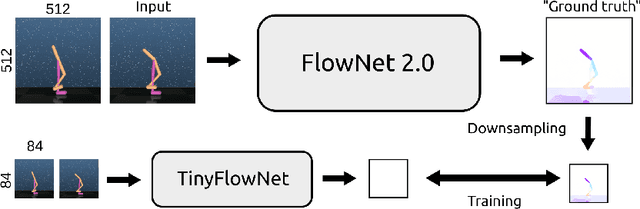
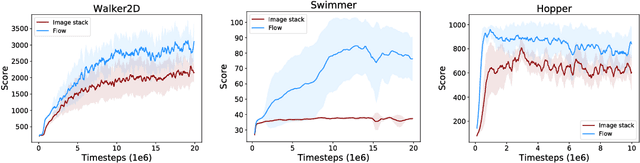

In dynamic environments, learned controllers are supposed to take motion into account when selecting the action to be taken. However, in existing reinforcement learning works motion is rarely treated explicitly; it is rather assumed that the controller learns the necessary motion representation from temporal stacks of frames implicitly. In this paper, we show that for continuous control tasks learning an explicit representation of motion improves the quality of the learned controller in dynamic scenarios. We demonstrate this on common benchmark tasks (Walker, Swimmer, Hopper), on target reaching and ball catching tasks with simulated robotic arms, and on a dynamic single ball juggling task. Moreover, we find that when equipped with an appropriate network architecture, the agent can, on some tasks, learn motion features also with pure reinforcement learning, without additional supervision. Further we find that using an image difference between the current and the previous frame as an additional input leads to better results than a temporal stack of frames.
TD or not TD: Analyzing the Role of Temporal Differencing in Deep Reinforcement Learning
Jun 04, 2018

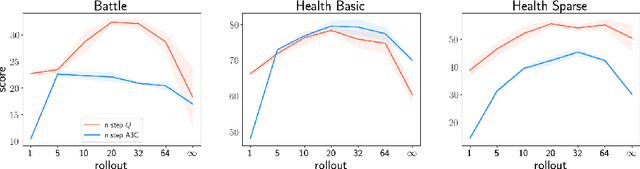
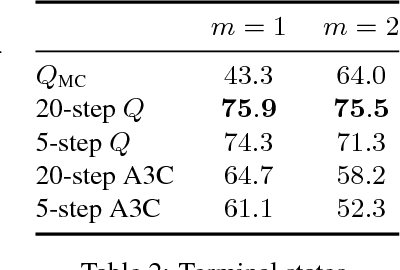
Our understanding of reinforcement learning (RL) has been shaped by theoretical and empirical results that were obtained decades ago using tabular representations and linear function approximators. These results suggest that RL methods that use temporal differencing (TD) are superior to direct Monte Carlo estimation (MC). How do these results hold up in deep RL, which deals with perceptually complex environments and deep nonlinear models? In this paper, we re-examine the role of TD in modern deep RL, using specially designed environments that control for specific factors that affect performance, such as reward sparsity, reward delay, and the perceptual complexity of the task. When comparing TD with infinite-horizon MC, we are able to reproduce classic results in modern settings. Yet we also find that finite-horizon MC is not inferior to TD, even when rewards are sparse or delayed. This makes MC a viable alternative to TD in deep RL.