 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuJoCo MPC for Humanoid Control: Evaluation on HumanoidBench
Aug 01, 2024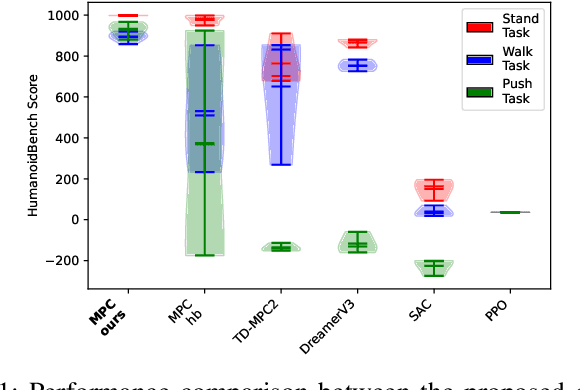
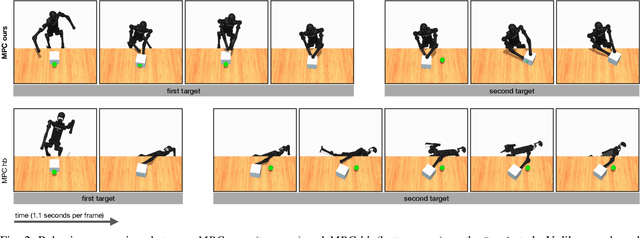
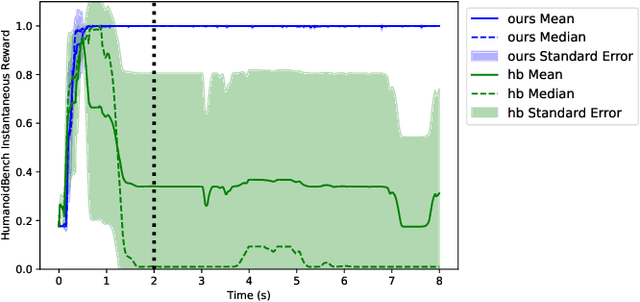
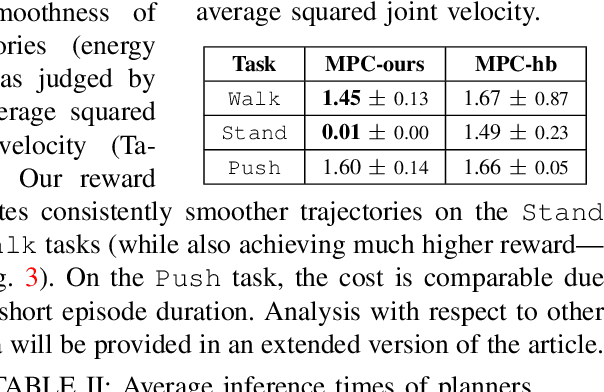
We tackle the recently introduced benchmark for whole-body humanoid control HumanoidBench using MuJoCo MPC. We find that sparse reward functions of HumanoidBench yield undesirable and unrealistic behaviors when optimized; therefore, we propose a set of regularization terms that stabilize the robot behavior across tasks. Current evaluations on a subset of tasks demonstrate that our proposed reward function allows achieving the highest HumanoidBench scores while maintaining realistic posture and smooth control signals. Our code is publicly available and will become a part of MuJoCo MPC, enabling rapid prototyping of robot behaviors.
Surprisingly Robust In-Hand Manipulation: An Empirical Study
Jan 27, 2022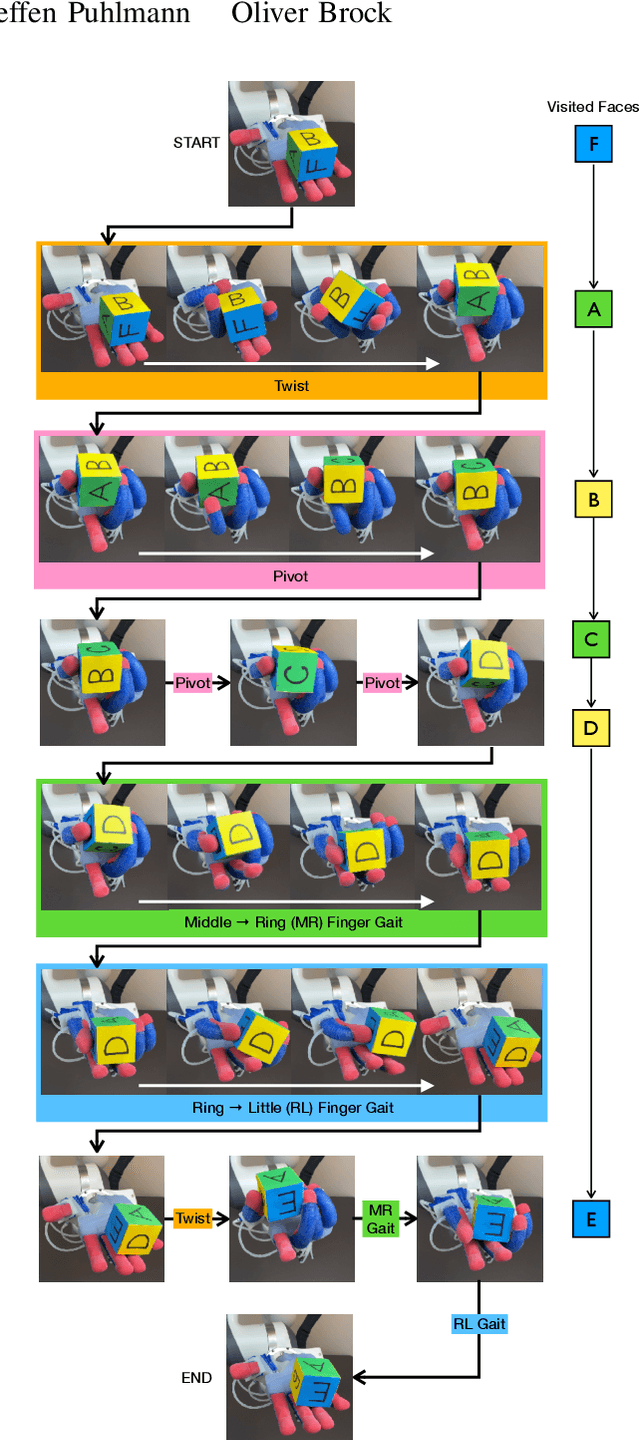
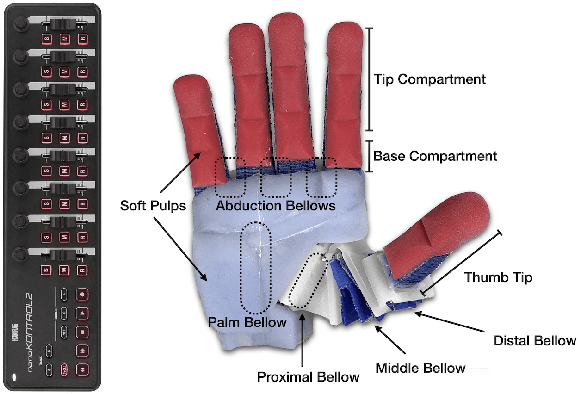
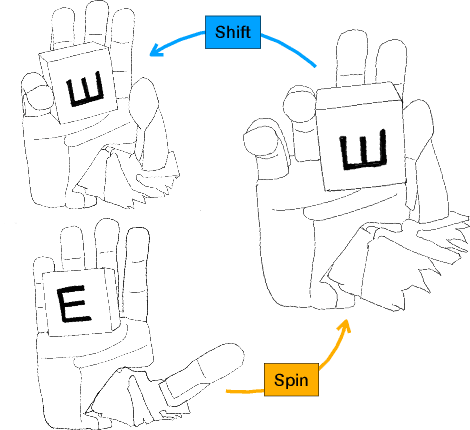

We present in-hand manipulation skills on a dexterous, compliant, anthropomorphic hand. Even though these skills were derived in a simplistic manner, they exhibit surprising robustness to variations in shape, size, weight, and placement of the manipulated object. They are also very insensitive to variation of execution speeds, ranging from highly dynamic to quasi-static. The robustness of the skills leads to compositional properties that enable extended and robust manipulation programs. To explain the surprising robustness of the in-hand manipulation skills, we performed a detailed, empirical analysis of the skills' performance. From this analysis, we identify three principles for skill design: 1) Exploiting the hardware's innate ability to drive hard-to-model contact dynamics. 2) Taking actions to constrain these interactions, funneling the system into a narrow set of possibilities. 3) Composing such action sequences into complex manipulation programs. We believe that these principles constitute an important foundation for robust robotic in-hand manipulation, and possibly for manipulation in general.
* Published in Robotics: Science and Systems 2021. Proceedings at http://www.roboticsproceedings.org/rss17/p089.html Spotlight talk at https://youtu.be/2vwdP4WjGoQ Complete video playlist at https://www.youtube.com/playlist?list=PLb-CNILz7vmt6Ae_yD9i15TrCw0S8bKCn
CrossNorm: Normalization for Off-Policy TD Reinforcement Learning
Feb 14, 2019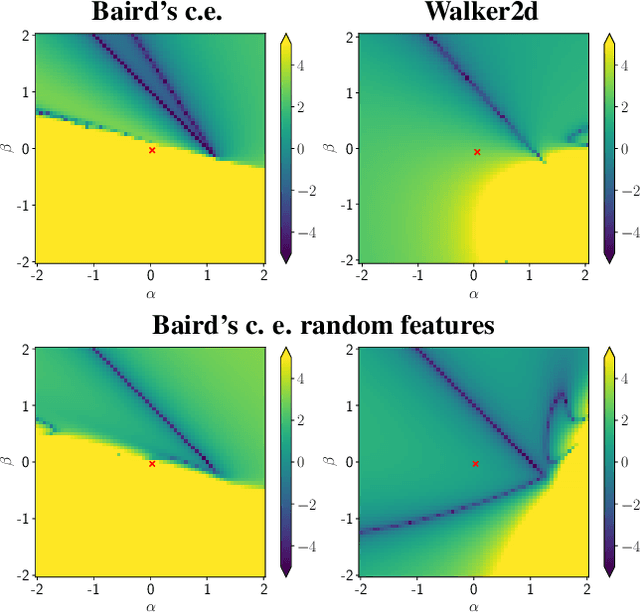
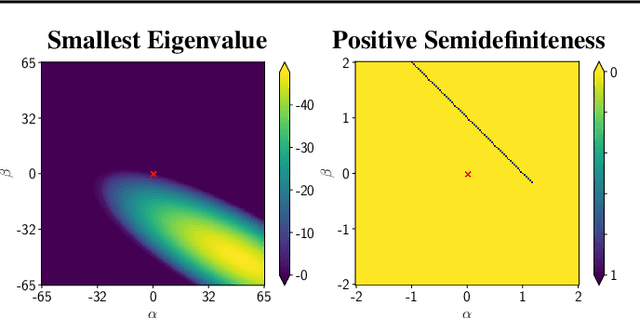
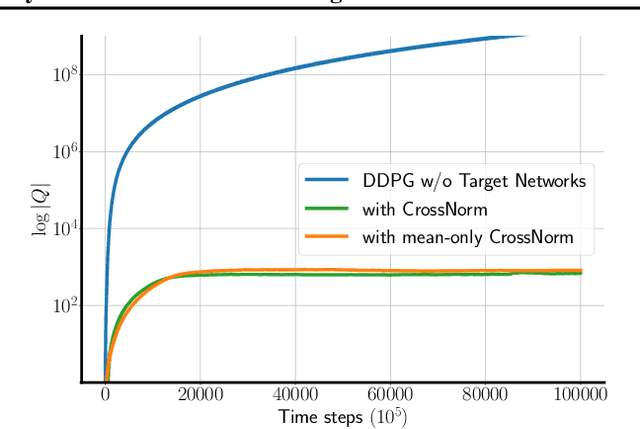
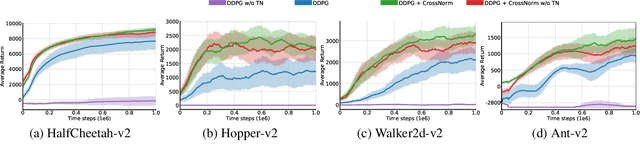
Off-policy Temporal Difference (TD) learning methods, when combined with function approximators, suffer from the risk of divergence, a phenomenon known as the deadly triad. It has long been noted that some feature representations work better than others. In this paper we investigate how feature normalization can prevent divergence and improve training. Our method, which we call CrossNorm, can be regarded as a new variant of batch normalization that re-centers data for multi-modal distributions, which occur in the off-policy TD updates. We show empirically that CrossNorm improves the stability of the learning process. We apply CrossNorm to DDPG and TD3 and achieve stable training and improved performance across a range of MuJoCo benchmark tasks. Moreover, for the first time, we are able to train DDPG stably without the use of target networks.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
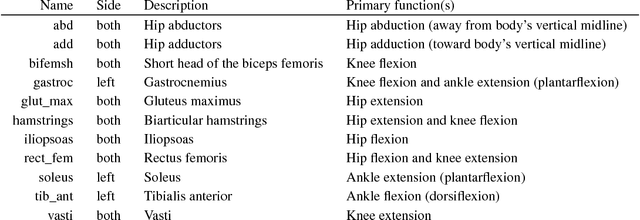
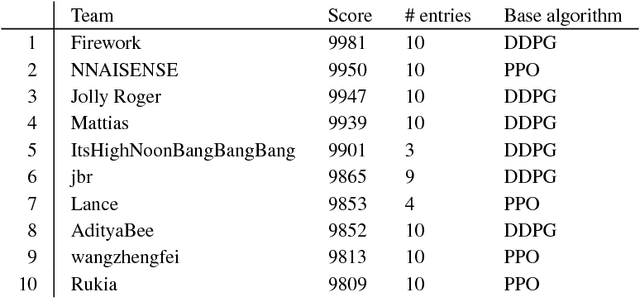

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.