 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduled Intrinsic Drive: A Hierarchical Take on Intrinsically Motivated Exploration
Paper and Code
Mar 18, 2019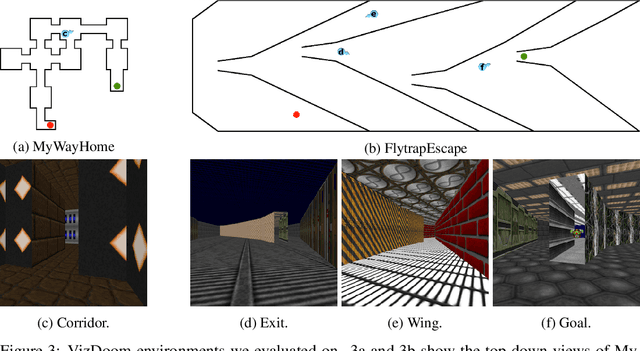
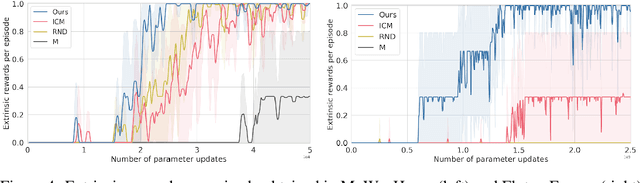


Exploration in sparse reward reinforcement learning remains a difficult open challenge. Many state-of-the-art methods use intrinsic motivation to complement the sparse extrinsic reward signal, giving the agent more opportunities to receive feedback during exploration. Most commonly, these signals are added as bonus rewards, which results in the mixture policy faithfully conducting neither exploration nor task fulfillment for an extended amount of time. In this paper, we instead learn separate intrinsic and extrinsic task policies and schedule between these different drives to accelerate exploration and stabilize learning. Moreover, we introduce a new type of intrinsic reward denoted as successor feature control (SFC), which is general and not task-specific. It takes into account statistics over complete trajectories and thus differs from previous methods that only use local information to evaluate intrinsic motivation. We evaluate our proposed scheduled intrinsic drive (SID) agent using three different environments with pure visual inputs: VizDoom, DeepMind Lab and OpenAI Gym classic control from pixels. The results show a greatly improved exploration efficiency with SFC and the hierarchical usage of the intrinsic drives. A video of our experimental results can be found at https://youtu.be/4ZHcBo7006Y.