 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptions as responses: Grounding behavioural hierarchies in multi-agent RL
Jun 06, 2019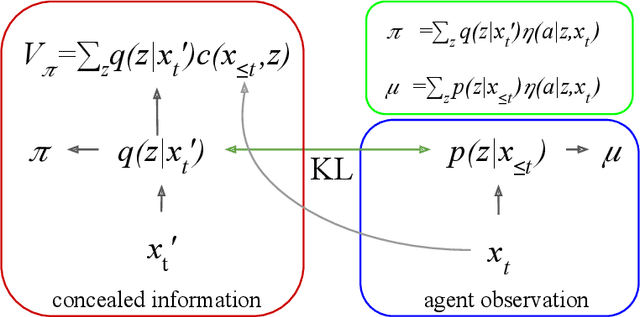
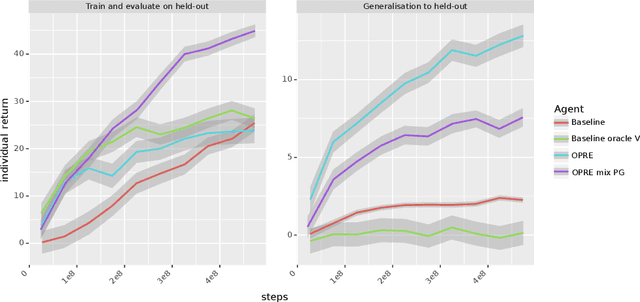
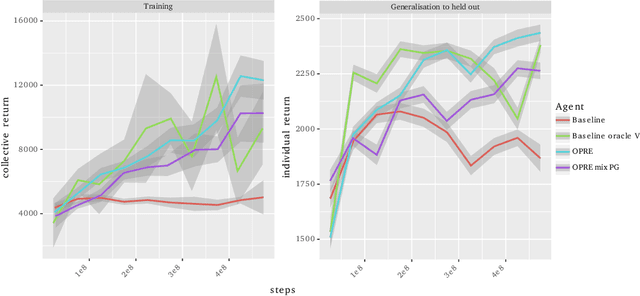
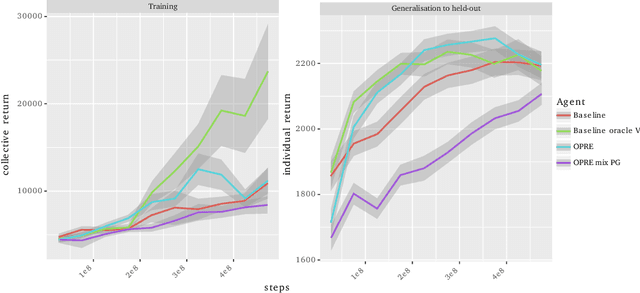
We propose a novel hierarchical agent architecture for multi-agent reinforcement learning with concealed information. The hierarchy is grounded in the concealed information about other players, which resolves "the chicken or the egg" nature of option discovery. We factorise the value function over a latent representation of the concealed information and then re-use this latent space to factorise the policy into options. Low-level policies (options) are trained to respond to particular states of other agents grouped by the latent representation, while the top level (meta-policy) learns to infer the latent representation from its own observation thereby to select the right option. This grounding facilitates credit assignment across the levels of hierarchy. We show that this helps generalisation---performance against a held-out set of pre-trained competitors, while training in self- or population-play---and resolution of social dilemmas in self-play.