 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwareness of uncertainty in classification using a multivariate model and multi-views
Apr 16, 2024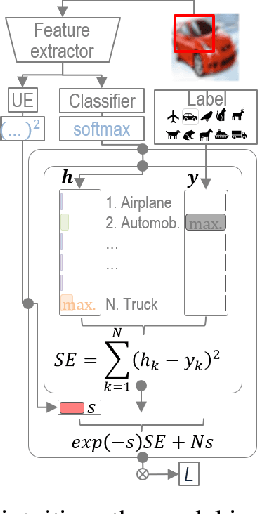
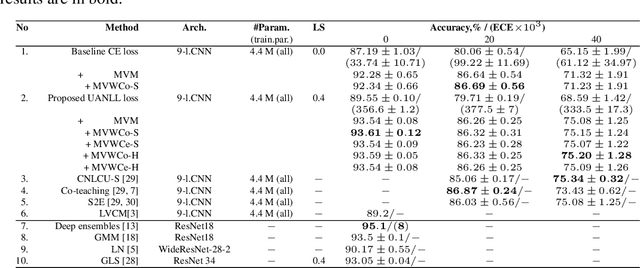
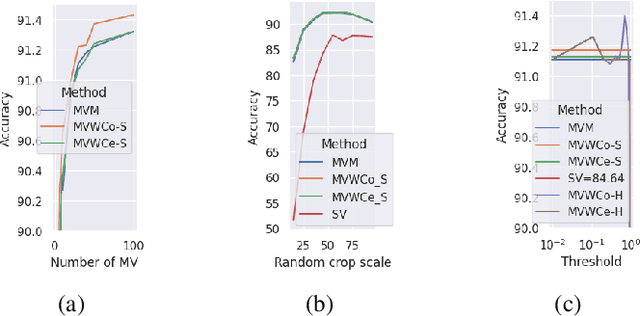
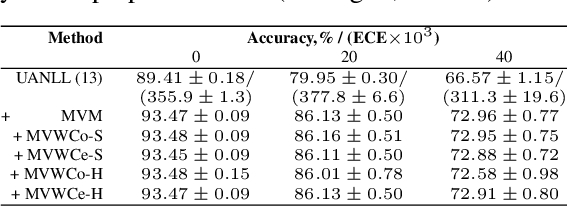
One of the ways to make artificial intelligence more natural is to give it some room for doubt. Two main questions should be resolved in that way. First, how to train a model to estimate uncertainties of its own predictions? And then, what to do with the uncertain predictions if they appear? First, we proposed an uncertainty-aware negative log-likelihood loss for the case of N-dimensional multivariate normal distribution with spherical variance matrix to the solution of N-classes classification tasks. The loss is similar to the heteroscedastic regression loss. The proposed model regularizes uncertain predictions, and trains to calculate both the predictions and their uncertainty estimations. The model fits well with the label smoothing technique. Second, we expanded the limits of data augmentation at the training and test stages, and made the trained model to give multiple predictions for a given number of augmented versions of each test sample. Given the multi-view predictions together with their uncertainties and confidences, we proposed several methods to calculate final predictions, including mode values and bin counts with soft and hard weights. For the latter method, we formalized the model tuning task in the form of multimodal optimization with non-differentiable criteria of maximum accuracy, and applied particle swarm optimization to solve the tuning task. The proposed methodology was tested using CIFAR-10 dataset with clean and noisy labels and demonstrated good results in comparison with other uncertainty estimation methods related to sample selection, co-teaching, and label smoothing.
FFC-SE: Fast Fourier Convolution for Speech Enhancement
Apr 06, 2022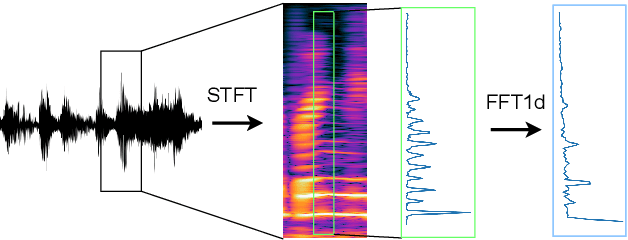
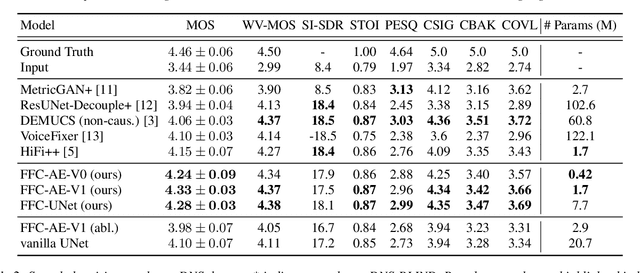
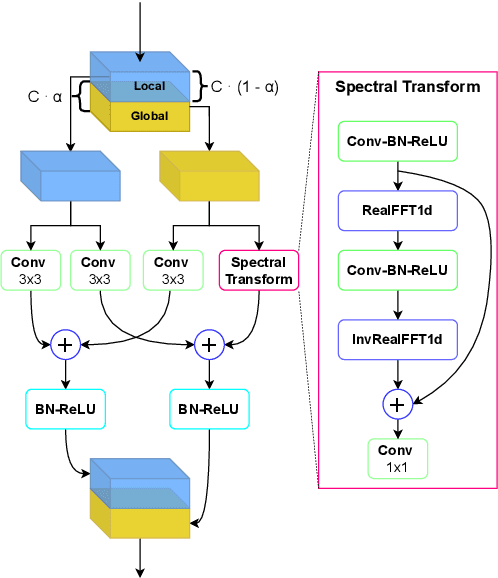
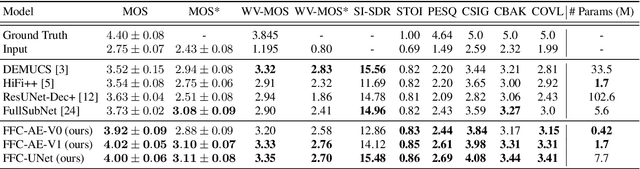
Fast Fourier convolution (FFC) is the recently proposed neural operator showing promising performance in several computer vision problems. The FFC operator allows employing large receptive field operations within early layers of the neural network. It was shown to be especially helpful for inpainting of periodic structures which are common in audio processing. In this work, we design neural network architectures which adapt FFC for speech enhancement. We hypothesize that a large receptive field allows these networks to produce more coherent phases than vanilla convolutional models, and validate this hypothesis experimentally. We found that neural networks based on Fast Fourier convolution outperform analogous convolutional models and show better or comparable results with other speech enhancement baselines.
HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement
Mar 24, 2022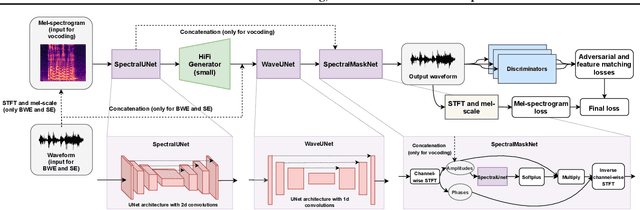
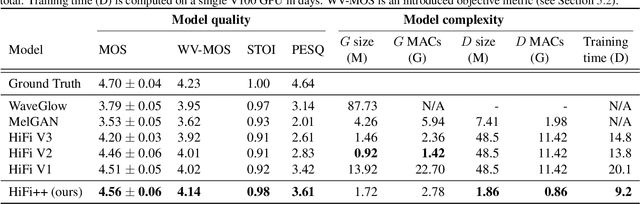

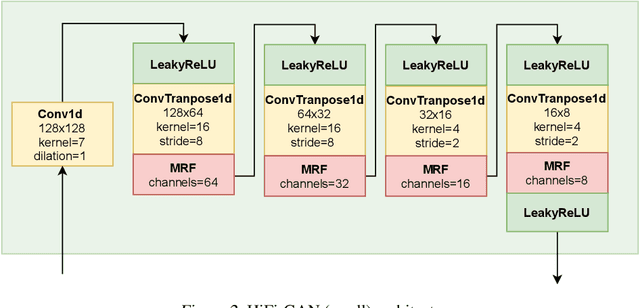
Generative adversarial networks have recently demonstrated outstanding performance in neural vocoding outperforming best autoregressive and flow-based models. In this paper, we show that this success can be extended to other tasks of conditional audio generation. In particular, building upon HiFi vocoders, we propose a novel HiFi++ general framework for neural vocoding, bandwidth extension, and speech enhancement. We show that with the improved generator architecture and simplified multi-discriminator training, HiFi++ performs on par with the state-of-the-art in these tasks while spending significantly less memory and computational resources. The effectiveness of our approach is validated through a series of extensive experiments.
Universal Conditional Machine
Jun 06, 2018
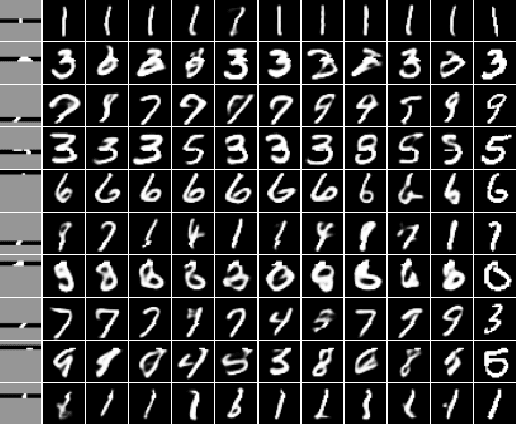

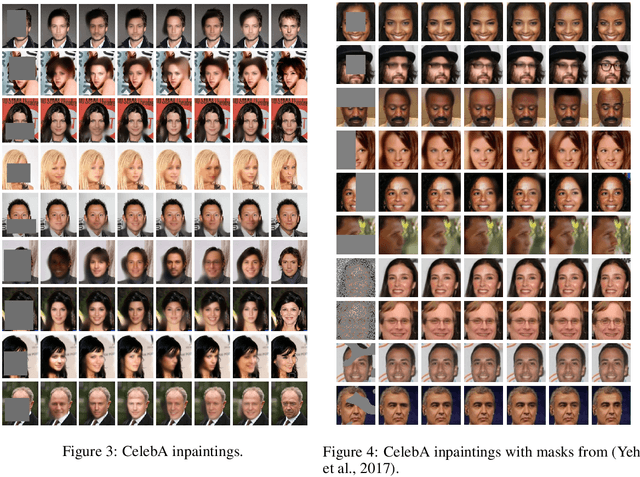
We propose a single neural probabilistic model based on variational autoencoder that can be conditioned on an arbitrary subset of observed features and then sample the remaining features in "one shot". The features may be both real-valued and categorical. Training of the model is performed by stochastic variational Bayes. The experimental evaluation on synthetic data, as well as feature imputation and image inpainting problems, shows the effectiveness of the proposed approach and diversity of the generated samples.
Adaptive Cardinality Estimation
Nov 22, 2017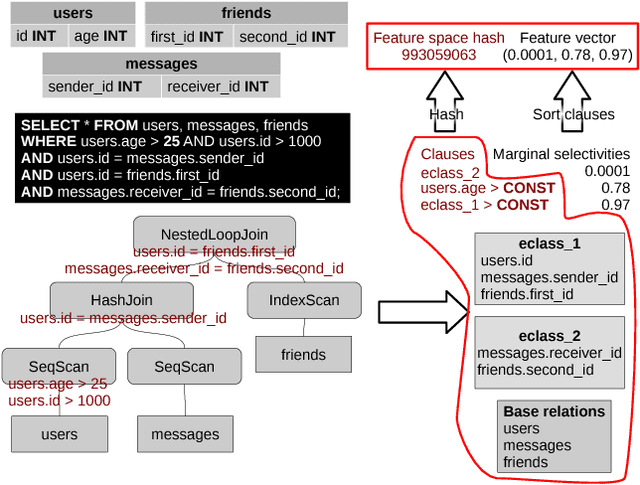
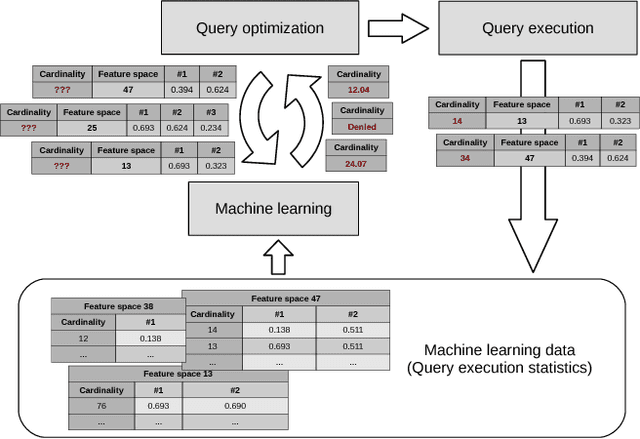
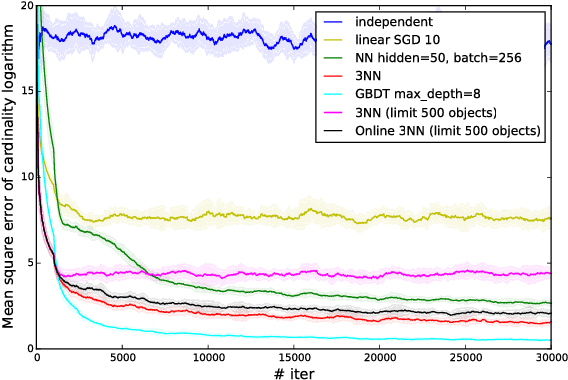
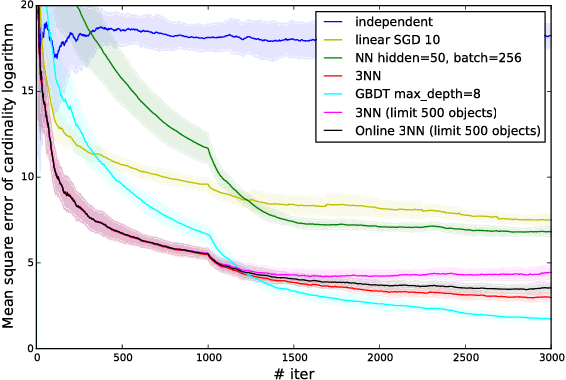
In this paper we address cardinality estimation problem which is an important subproblem in query optimization. Query optimization is a part of every relational DBMS responsible for finding the best way of the execution for the given query. These ways are called plans. The execution time of different plans may differ by several orders, so query optimizer has a great influence on the whole DBMS performance. We consider cost-based query optimization approach as the most popular one. It was observed that cost-based optimization quality depends much on cardinality estimation quality. Cardinality of the plan node is the number of tuples returned by it. In the paper we propose a novel cardinality estimation approach with the use of machine learning methods. The main point of the approach is using query execution statistics of the previously executed queries to improve cardinality estimations. We called this approach adaptive cardinality estimation to reflect this point. The approach is general, flexible, and easy to implement. The experimental evaluation shows that this approach significantly increases the quality of cardinality estimation, and therefore increases the DBMS performance for some queries by several times or even by several dozens of times.