 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Gaze-based Volumetric Medical Image Segmentation
May 21, 2025Accurate segmentation of anatomical structures in volumetric medical images is crucial for clinical applications, including disease monitoring and cancer treatment planning. Contemporary interactive segmentation models, such as Segment Anything Model 2 (SAM-2) and its medical variant (MedSAM-2), rely on manually provided prompts like bounding boxes and mouse clicks. In this study, we introduce eye gaze as a novel informational modality for interactive segmentation, marking the application of eye-tracking for 3D medical image segmentation. We evaluate the performance of using gaze-based prompts with SAM-2 and MedSAM-2 using both synthetic and real gaze data. Compared to bounding boxes, gaze-based prompts offer a time-efficient interaction approach with slightly lower segmentation quality. Our findings highlight the potential of using gaze as a complementary input modality for interactive 3D medical image segmentation.
Gaze-Assisted Medical Image Segmentation
Oct 23, 2024The annotation of patient organs is a crucial part of various diagnostic and treatment procedures, such as radiotherapy planning. Manual annotation is extremely time-consuming, while its automation using modern image analysis techniques has not yet reached levels sufficient for clinical adoption. This paper investigates the idea of semi-supervised medical image segmentation using human gaze as interactive input for segmentation correction. In particular, we fine-tuned the Segment Anything Model in Medical Images (MedSAM), a public solution that uses various prompt types as additional input for semi-automated segmentation correction. We used human gaze data from reading abdominal images as a prompt for fine-tuning MedSAM. The model was validated on a public WORD database, which consists of 120 CT scans of 16 abdominal organs. The results of the gaze-assisted MedSAM were shown to be superior to the results of the state-of-the-art segmentation models. In particular, the average Dice coefficient for 16 abdominal organs was 85.8%, 86.7%, 81.7%, and 90.5% for nnUNetV2, ResUNet, original MedSAM, and our gaze-assisted MedSAM model, respectively.
Awareness of uncertainty in classification using a multivariate model and multi-views
Apr 16, 2024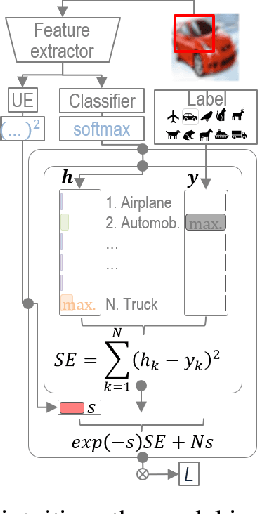
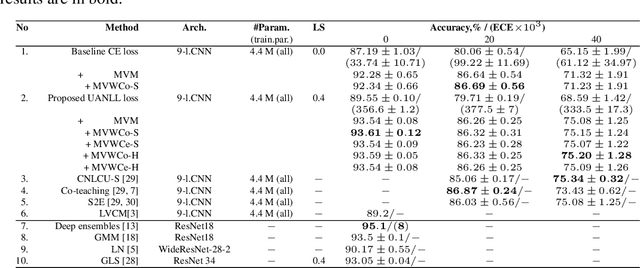
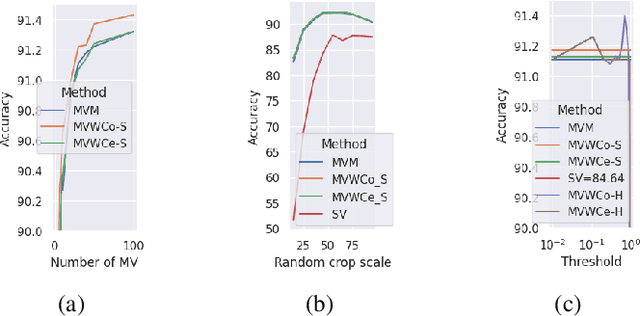
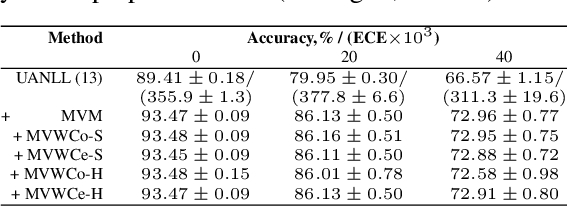
One of the ways to make artificial intelligence more natural is to give it some room for doubt. Two main questions should be resolved in that way. First, how to train a model to estimate uncertainties of its own predictions? And then, what to do with the uncertain predictions if they appear? First, we proposed an uncertainty-aware negative log-likelihood loss for the case of N-dimensional multivariate normal distribution with spherical variance matrix to the solution of N-classes classification tasks. The loss is similar to the heteroscedastic regression loss. The proposed model regularizes uncertain predictions, and trains to calculate both the predictions and their uncertainty estimations. The model fits well with the label smoothing technique. Second, we expanded the limits of data augmentation at the training and test stages, and made the trained model to give multiple predictions for a given number of augmented versions of each test sample. Given the multi-view predictions together with their uncertainties and confidences, we proposed several methods to calculate final predictions, including mode values and bin counts with soft and hard weights. For the latter method, we formalized the model tuning task in the form of multimodal optimization with non-differentiable criteria of maximum accuracy, and applied particle swarm optimization to solve the tuning task. The proposed methodology was tested using CIFAR-10 dataset with clean and noisy labels and demonstrated good results in comparison with other uncertainty estimation methods related to sample selection, co-teaching, and label smoothing.
Cross-Modal Conceptualization in Bottleneck Models
Oct 23, 2023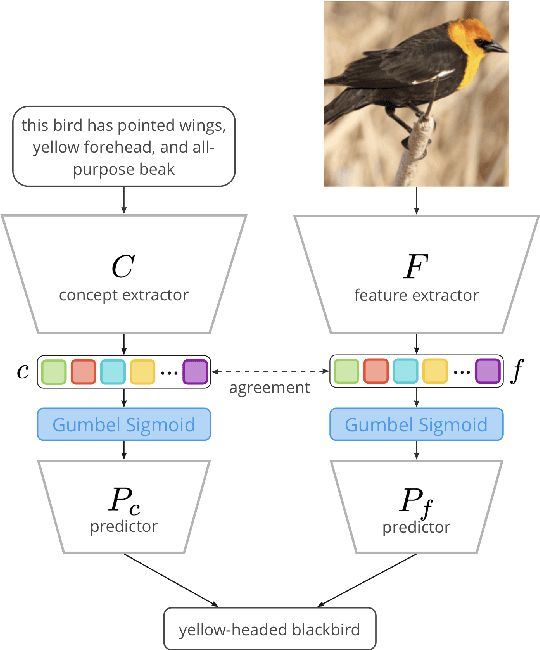
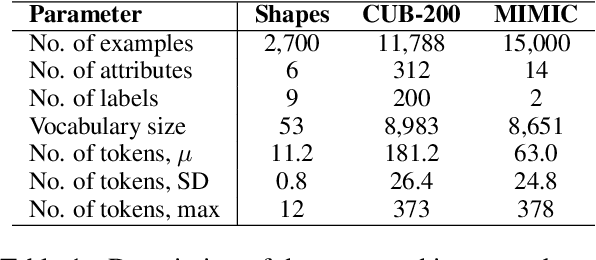
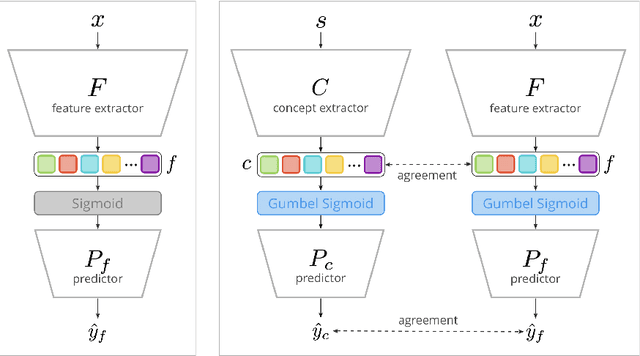
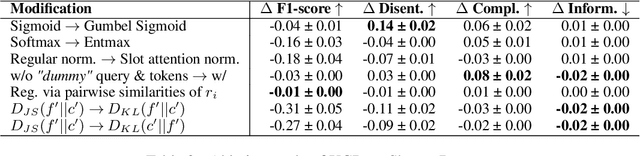
Concept Bottleneck Models (CBMs) assume that training examples (e.g., x-ray images) are annotated with high-level concepts (e.g., types of abnormalities), and perform classification by first predicting the concepts, followed by predicting the label relying on these concepts. The main difficulty in using CBMs comes from having to choose concepts that are predictive of the label and then having to label training examples with these concepts. In our approach, we adopt a more moderate assumption and instead use text descriptions (e.g., radiology reports), accompanying the images in training, to guide the induction of concepts. Our cross-modal approach treats concepts as discrete latent variables and promotes concepts that (1) are predictive of the label, and (2) can be predicted reliably from both the image and text. Through experiments conducted on datasets ranging from synthetic datasets (e.g., synthetic images with generated descriptions) to realistic medical imaging datasets, we demonstrate that cross-modal learning encourages the induction of interpretable concepts while also facilitating disentanglement. Our results also suggest that this guidance leads to increased robustness by suppressing the reliance on shortcut features.