 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Conceptualization in Bottleneck Models
Paper and Code
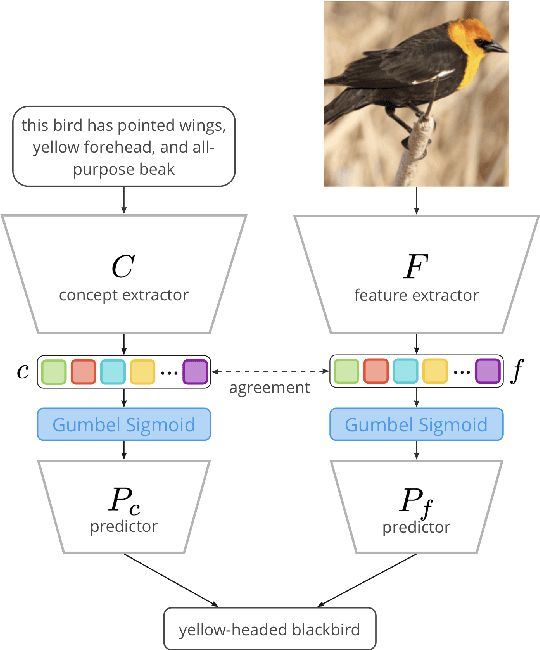
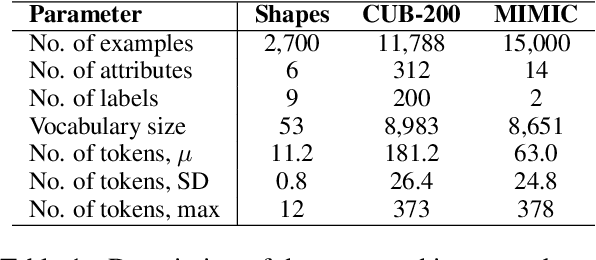
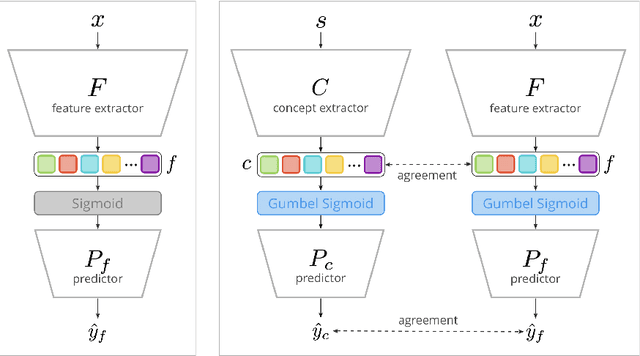
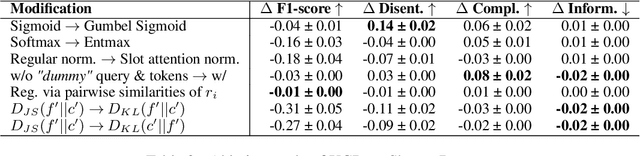
Concept Bottleneck Models (CBMs) assume that training examples (e.g., x-ray images) are annotated with high-level concepts (e.g., types of abnormalities), and perform classification by first predicting the concepts, followed by predicting the label relying on these concepts. The main difficulty in using CBMs comes from having to choose concepts that are predictive of the label and then having to label training examples with these concepts. In our approach, we adopt a more moderate assumption and instead use text descriptions (e.g., radiology reports), accompanying the images in training, to guide the induction of concepts. Our cross-modal approach treats concepts as discrete latent variables and promotes concepts that (1) are predictive of the label, and (2) can be predicted reliably from both the image and text. Through experiments conducted on datasets ranging from synthetic datasets (e.g., synthetic images with generated descriptions) to realistic medical imaging datasets, we demonstrate that cross-modal learning encourages the induction of interpretable concepts while also facilitating disentanglement. Our results also suggest that this guidance leads to increased robustness by suppressing the reliance on shortcut features.