 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Adaptive Multi-Goal Exploration
Nov 23, 2021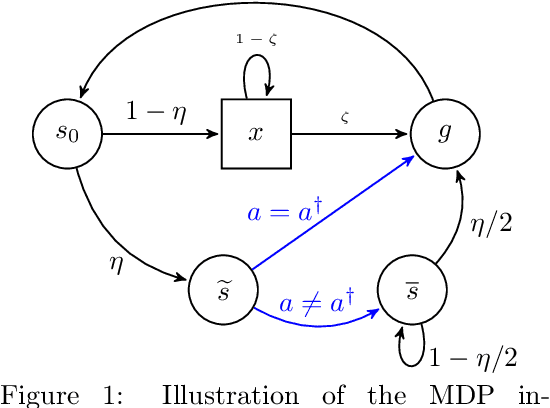
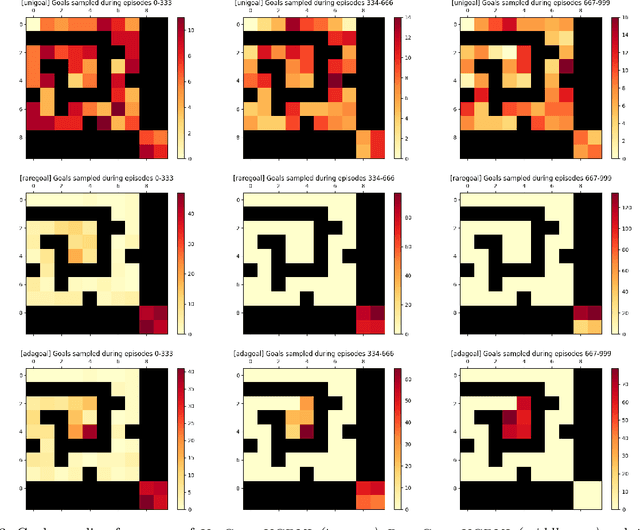
We introduce a generic strategy for provably efficient multi-goal exploration. It relies on AdaGoal, a novel goal selection scheme that is based on a simple constrained optimization problem, which adaptively targets goal states that are neither too difficult nor too easy to reach according to the agent's current knowledge. We show how AdaGoal can be used to tackle the objective of learning an $\epsilon$-optimal goal-conditioned policy for all the goal states that are reachable within $L$ steps in expectation from a reference state $s_0$ in a reward-free Markov decision process. In the tabular case with $S$ states and $A$ actions, our algorithm requires $\tilde{O}(L^3 S A \epsilon^{-2})$ exploration steps, which is nearly minimax optimal. We also readily instantiate AdaGoal in linear mixture Markov decision processes, which yields the first goal-oriented PAC guarantee with linear function approximation. Beyond its strong theoretical guarantees, AdaGoal is anchored in the high-level algorithmic structure of existing methods for goal-conditioned deep reinforcement learning.
UCB Momentum Q-learning: Correcting the bias without forgetting
Mar 01, 2021
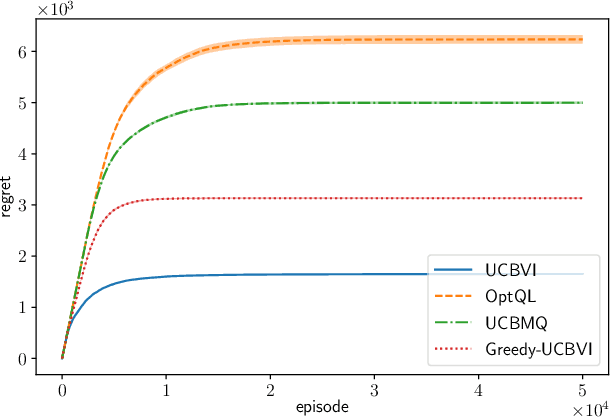

We propose UCBMQ, Upper Confidence Bound Momentum Q-learning, a new algorithm for reinforcement learning in tabular and possibly stage-dependent, episodic Markov decision process. UCBMQ is based on Q-learning where we add a momentum term and rely on the principle of optimism in face of uncertainty to deal with exploration. Our new technical ingredient of UCBMQ is the use of momentum to correct the bias that Q-learning suffers while, at the same time, limiting the impact it has on the second-order term of the regret. For UCBMQ , we are able to guarantee a regret of at most $O(\sqrt{H^3SAT}+ H^4 S A )$ where $H$ is the length of an episode, $S$ the number of states, $A$ the number of actions, $T$ the number of episodes and ignoring terms in poly$log(SAHT)$. Notably, UCBMQ is the first algorithm that simultaneously matches the lower bound of $\Omega(\sqrt{H^3SAT})$ for large enough $T$ and has a second-order term (with respect to the horizon $T$) that scales only linearly with the number of states $S$.
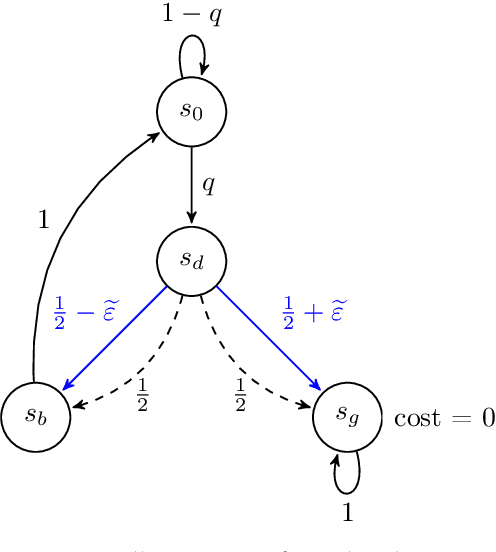
Episodic Reinforcement Learning in Finite MDPs: Minimax Lower Bounds Revisited
Oct 07, 2020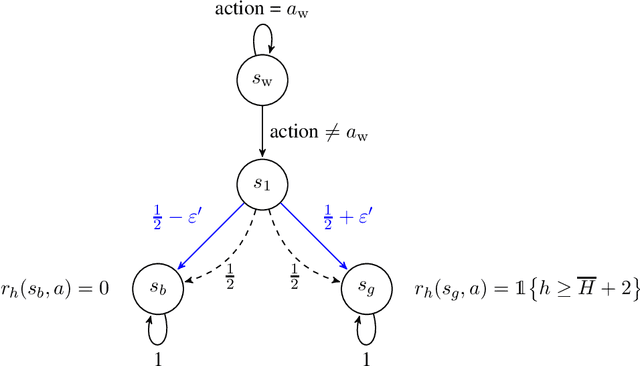
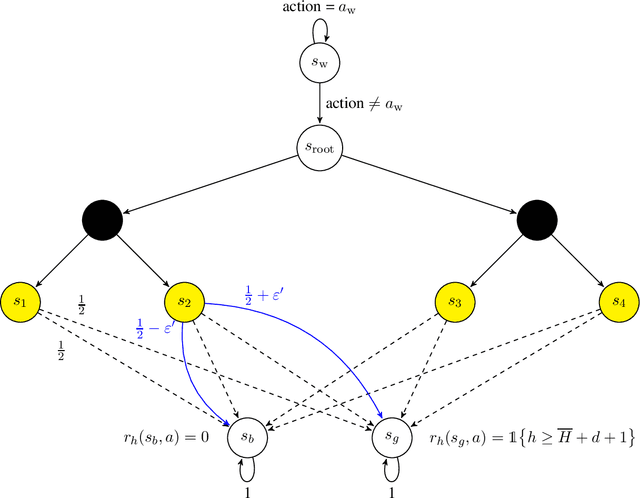
In this paper, we propose new problem-independent lower bounds on the sample complexity and regret in episodic MDPs, with a particular focus on the non-stationary case in which the transition kernel is allowed to change in each stage of the episode. Our main contribution is a novel lower bound of $\Omega((H^3SA/\epsilon^2)\log(1/\delta))$ on the sample complexity of an $(\varepsilon,\delta)$-PAC algorithm for best policy identification in a non-stationary MDP. This lower bound relies on a construction of "hard MDPs" which is different from the ones previously used in the literature. Using this same class of MDPs, we also provide a rigorous proof of the $\Omega(\sqrt{H^3SAT})$ regret bound for non-stationary MDPs. Finally, we discuss connections to PAC-MDP lower bounds.
Fast active learning for pure exploration in reinforcement learning
Jul 27, 2020
Realistic environments often provide agents with very limited feedback. When the environment is initially unknown, the feedback, in the beginning, can be completely absent, and the agents may first choose to devote all their effort on exploring efficiently. The exploration remains a challenge while it has been addressed with many hand-tuned heuristics with different levels of generality on one side, and a few theoretically-backed exploration strategies on the other. Many of them are incarnated by intrinsic motivation and in particular explorations bonuses. A common rule of thumb for exploration bonuses is to use $1/\sqrt{n}$ bonus that is added to the empirical estimates of the reward, where $n$ is a number of times this particular state (or a state-action pair) was visited. We show that, surprisingly, for a pure-exploration objective of reward-free exploration, bonuses that scale with $1/n$ bring faster learning rates, improving the known upper bounds with respect to the dependence on the horizon $H$. Furthermore, we show that with an improved analysis of the stopping time, we can improve by a factor $H$ the sample complexity in the best-policy identification setting, which is another pure-exploration objective, where the environment provides rewards but the agent is not penalized for its behavior during the exploration phase.
A Kernel-Based Approach to Non-Stationary Reinforcement Learning in Metric Spaces
Jul 09, 2020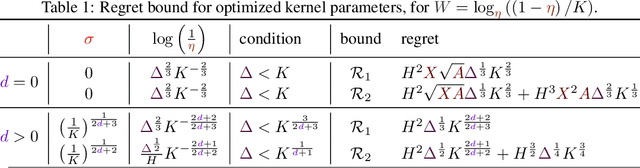
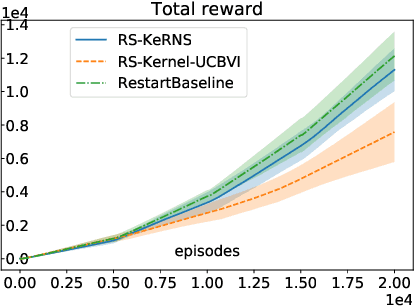


In this work, we propose KeRNS: an algorithm for episodic reinforcement learning in non-stationary Markov Decision Processes (MDPs) whose state-action set is endowed with a metric. Using a non-parametric model of the MDP built with time-dependent kernels, we prove a regret bound that scales with the covering dimension of the state-action space and the total variation of the MDP with time, which quantifies its level of non-stationarity. Our method generalizes previous approaches based on sliding windows and exponential discounting used to handle changing environments. We further propose a practical implementation of KeRNS, we analyze its regret and validate it experimentally.
Adaptive Reward-Free Exploration
Jun 11, 2020
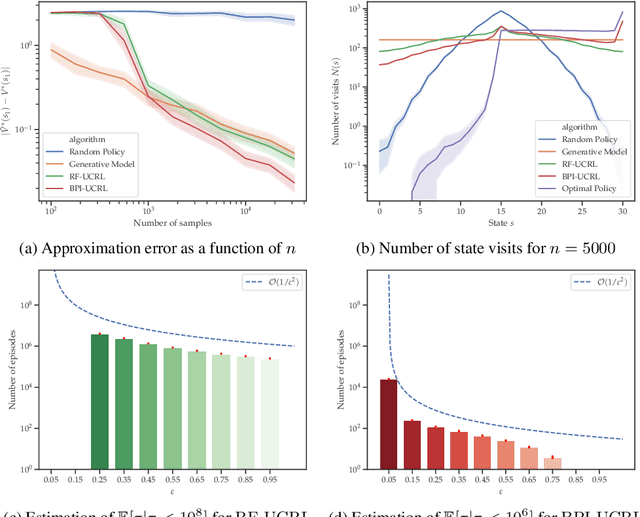
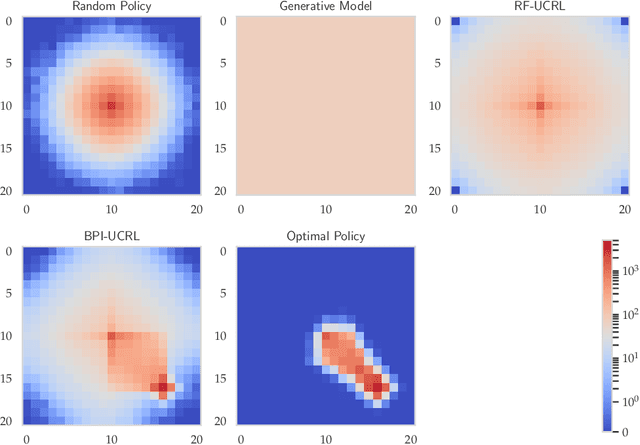
Reward-free exploration is a reinforcement learning setting recently studied by Jin et al., who address it by running several algorithms with regret guarantees in parallel. In our work, we instead propose a more adaptive approach for reward-free exploration which directly reduces upper bounds on the maximum MDP estimation error. We show that, interestingly, our reward-free UCRL algorithm can be seen as a variant of an algorithm of Fiechter from 1994, originally proposed for a different objective that we call best-policy identification. We prove that RF-UCRL needs $\mathcal{O}\left(({SAH^4}/{\varepsilon^2})\ln(1/\delta)\right)$ episodes to output, with probability $1-\delta$, an $\varepsilon$-approximation of the optimal policy for any reward function. We empirically compare it to oracle strategies using a generative model.
Planning in Markov Decision Processes with Gap-Dependent Sample Complexity
Jun 10, 2020
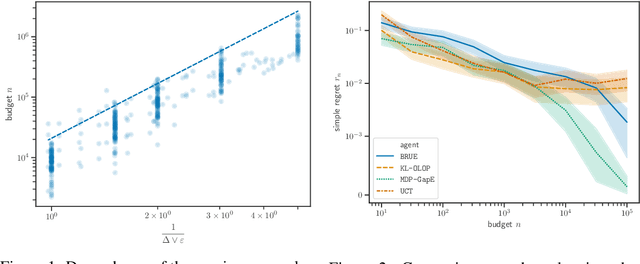


We propose MDP-GapE, a new trajectory-based Monte-Carlo Tree Search algorithm for planning in a Markov Decision Process in which transitions have a finite support. We prove an upper bound on the number of calls to the generative models needed for MDP-GapE to identify a near-optimal action with high probability. This problem-dependent sample complexity result is expressed in terms of the sub-optimality gaps of the state-action pairs that are visited during exploration. Our experiments reveal that MDP-GapE is also effective in practice, in contrast with other algorithms with sample complexity guarantees in the fixed-confidence setting, that are mostly theoretical.
Regret Bounds for Kernel-Based Reinforcement Learning
Apr 12, 2020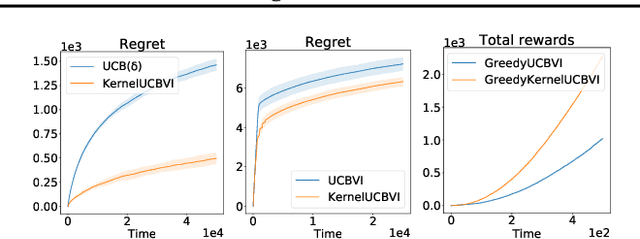

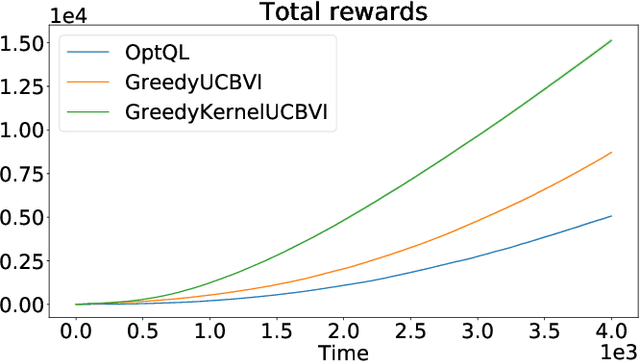
We consider the exploration-exploitation dilemma in finite-horizon reinforcement learning problems whose state-action space is endowed with a metric. We introduce Kernel-UCBVI, a model-based optimistic algorithm that leverages the smoothness of the MDP and a non-parametric kernel estimator of the rewards and transitions to efficiently balance exploration and exploitation. Unlike existing approaches with regret guarantees, it does not use any kind of partitioning of the state-action space. For problems with $K$ episodes and horizon $H$, we provide a regret bound of $O\left( H^3 K^{\max\left(\frac{1}{2}, \frac{2d}{2d+1}\right)}\right)$, where $d$ is the covering dimension of the joint state-action space. We empirically validate Kernel-UCBVI on discrete and continuous MDPs.