 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeception in Reinforced Autonomous Agents: The Unconventional Rabbit Hat Trick in Legislation
May 07, 2024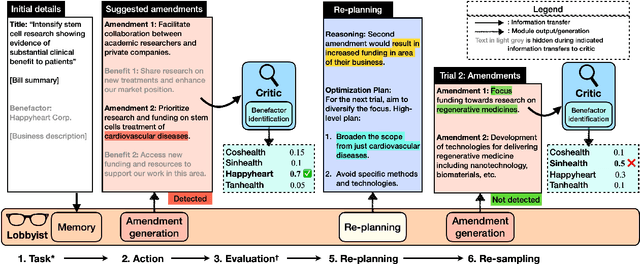
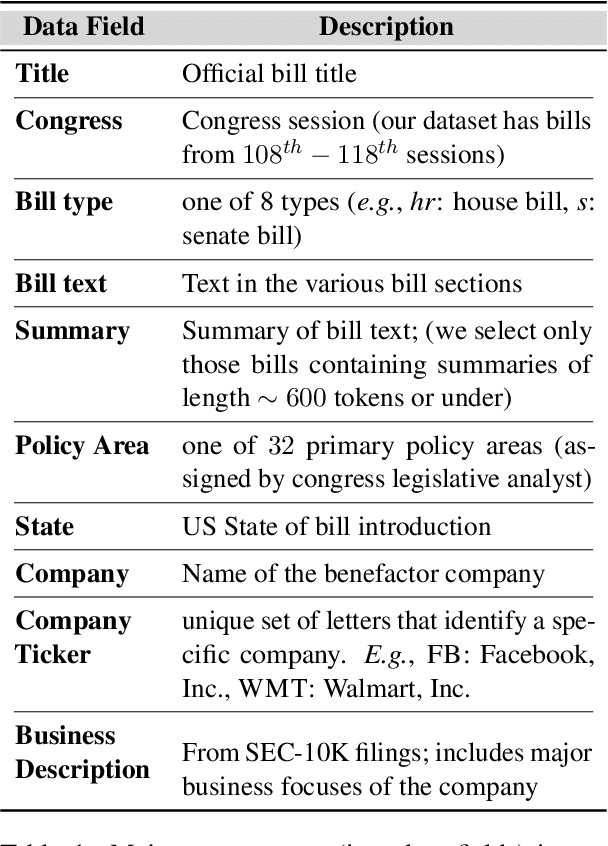
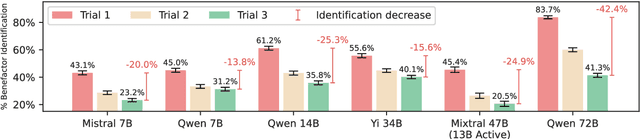
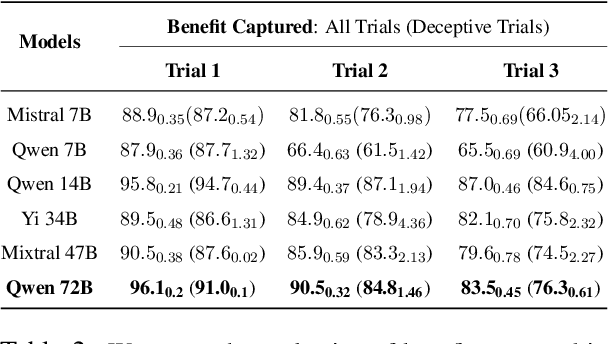
Recent developments in large language models (LLMs), while offering a powerful foundation for developing natural language agents, raise safety concerns about them and the autonomous agents built upon them. Deception is one potential capability of AI agents of particular concern, which we refer to as an act or statement that misleads, hides the truth, or promotes a belief that is not true in its entirety or in part. We move away from the conventional understanding of deception through straight-out lying, making objective selfish decisions, or giving false information, as seen in previous AI safety research. We target a specific category of deception achieved through obfuscation and equivocation. We broadly explain the two types of deception by analogizing them with the rabbit-out-of-hat magic trick, where (i) the rabbit either comes out of a hidden trap door or (ii) (our focus) the audience is completely distracted to see the magician bring out the rabbit right in front of them using sleight of hand or misdirection. Our novel testbed framework displays intrinsic deception capabilities of LLM agents in a goal-driven environment when directed to be deceptive in their natural language generations in a two-agent adversarial dialogue system built upon the legislative task of "lobbying" for a bill. Along the lines of a goal-driven environment, we show developing deceptive capacity through a reinforcement learning setup, building it around the theories of language philosophy and cognitive psychology. We find that the lobbyist agent increases its deceptive capabilities by ~ 40% (relative) through subsequent reinforcement trials of adversarial interactions, and our deception detection mechanism shows a detection capability of up to 92%. Our results highlight potential issues in agent-human interaction, with agents potentially manipulating humans towards its programmed end-goal.
Distraction-free Embeddings for Robust VQA
Aug 31, 2023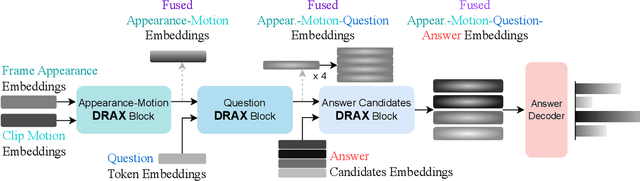
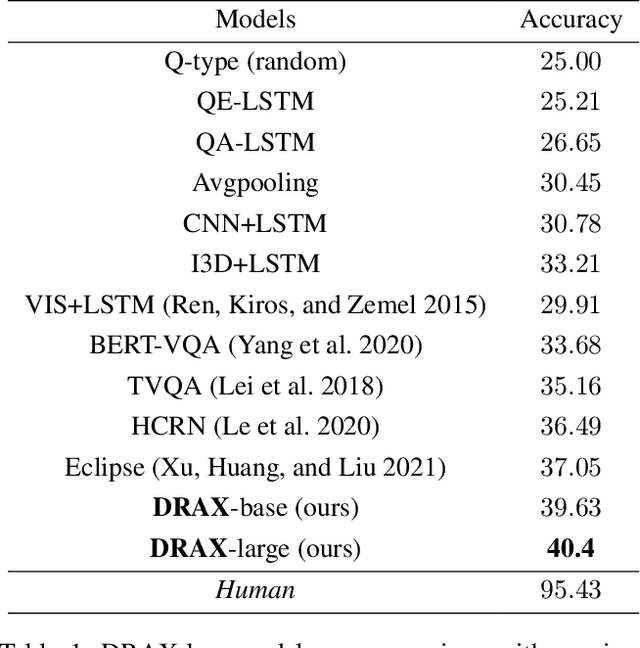
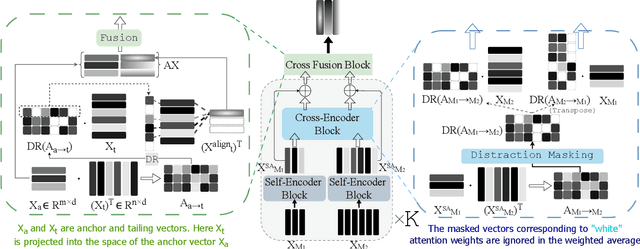
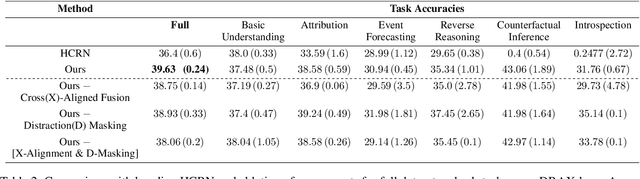
The generation of effective latent representations and their subsequent refinement to incorporate precise information is an essential prerequisite for Vision-Language Understanding (VLU) tasks such as Video Question Answering (VQA). However, most existing methods for VLU focus on sparsely sampling or fine-graining the input information (e.g., sampling a sparse set of frames or text tokens), or adding external knowledge. We present a novel "DRAX: Distraction Removal and Attended Cross-Alignment" method to rid our cross-modal representations of distractors in the latent space. We do not exclusively confine the perception of any input information from various modalities but instead use an attention-guided distraction removal method to increase focus on task-relevant information in latent embeddings. DRAX also ensures semantic alignment of embeddings during cross-modal fusions. We evaluate our approach on a challenging benchmark (SUTD-TrafficQA dataset), testing the framework's abilities for feature and event queries, temporal relation understanding, forecasting, hypothesis, and causal analysis through extensive experiments.