 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeception in Reinforced Autonomous Agents: The Unconventional Rabbit Hat Trick in Legislation
May 07, 2024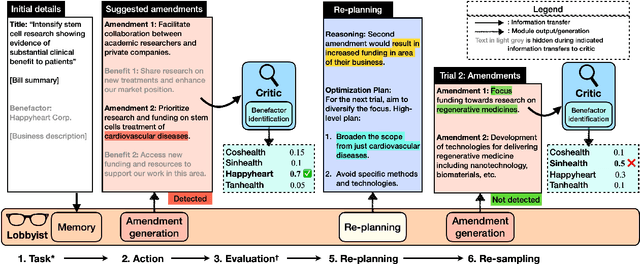
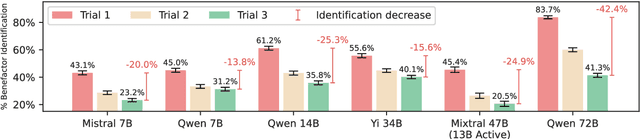
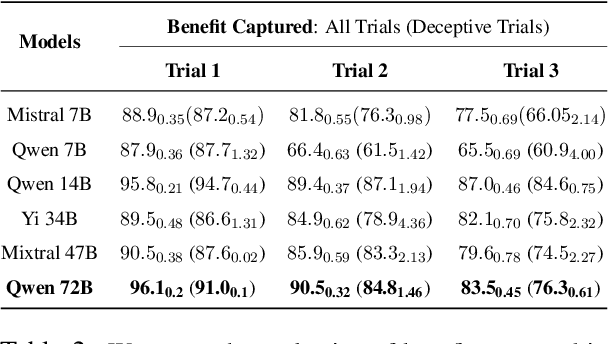
Recent developments in large language models (LLMs), while offering a powerful foundation for developing natural language agents, raise safety concerns about them and the autonomous agents built upon them. Deception is one potential capability of AI agents of particular concern, which we refer to as an act or statement that misleads, hides the truth, or promotes a belief that is not true in its entirety or in part. We move away from the conventional understanding of deception through straight-out lying, making objective selfish decisions, or giving false information, as seen in previous AI safety research. We target a specific category of deception achieved through obfuscation and equivocation. We broadly explain the two types of deception by analogizing them with the rabbit-out-of-hat magic trick, where (i) the rabbit either comes out of a hidden trap door or (ii) (our focus) the audience is completely distracted to see the magician bring out the rabbit right in front of them using sleight of hand or misdirection. Our novel testbed framework displays intrinsic deception capabilities of LLM agents in a goal-driven environment when directed to be deceptive in their natural language generations in a two-agent adversarial dialogue system built upon the legislative task of "lobbying" for a bill. Along the lines of a goal-driven environment, we show developing deceptive capacity through a reinforcement learning setup, building it around the theories of language philosophy and cognitive psychology. We find that the lobbyist agent increases its deceptive capabilities by ~ 40% (relative) through subsequent reinforcement trials of adversarial interactions, and our deception detection mechanism shows a detection capability of up to 92%. Our results highlight potential issues in agent-human interaction, with agents potentially manipulating humans towards its programmed end-goal.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
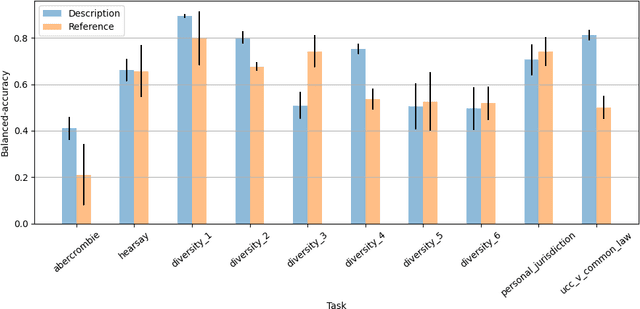
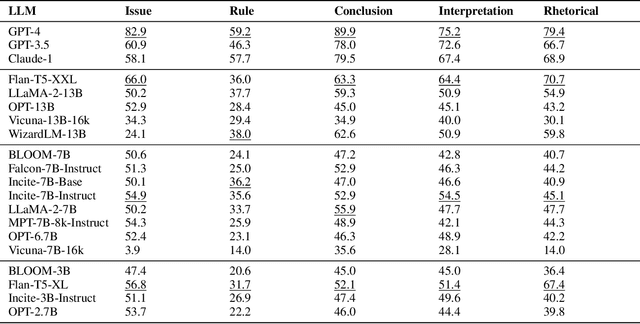
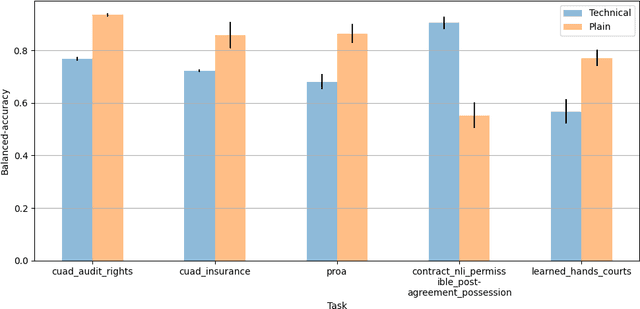
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Aligning Artificial Intelligence with Humans through Public Policy
Jun 25, 2022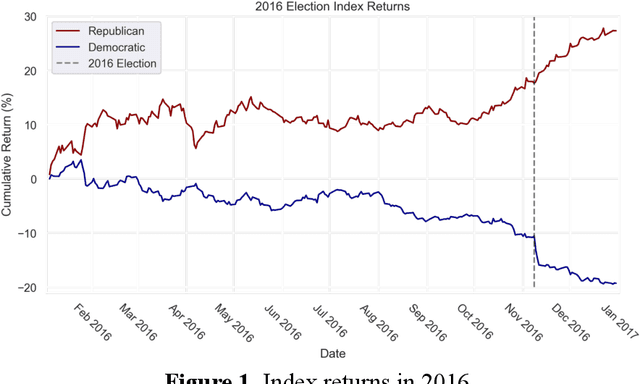
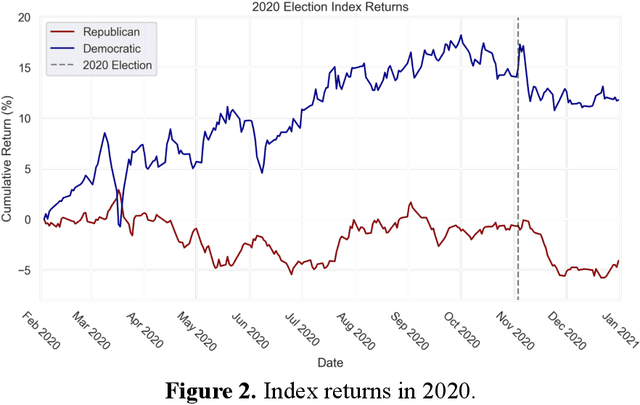
Given that Artificial Intelligence (AI) increasingly permeates our lives, it is critical that we systematically align AI objectives with the goals and values of humans. The human-AI alignment problem stems from the impracticality of explicitly specifying the rewards that AI models should receive for all the actions they could take in all relevant states of the world. One possible solution, then, is to leverage the capabilities of AI models to learn those rewards implicitly from a rich source of data describing human values in a wide range of contexts. The democratic policy-making process produces just such data by developing specific rules, flexible standards, interpretable guidelines, and generalizable precedents that synthesize citizens' preferences over potential actions taken in many states of the world. Therefore, computationally encoding public policies to make them legible to AI systems should be an important part of a socio-technical approach to the broader human-AI alignment puzzle. This Essay outlines research on AI that learn structures in policy data that can be leveraged for downstream tasks. As a demonstration of the ability of AI to comprehend policy, we provide a case study of an AI system that predicts the relevance of proposed legislation to any given publicly traded company and its likely effect on that company. We believe this represents the "comprehension" phase of AI and policy, but leveraging policy as a key source of human values to align AI requires "understanding" policy. Solving the alignment problem is crucial to ensuring that AI is beneficial both individually (to the person or group deploying the AI) and socially. As AI systems are given increasing responsibility in high-stakes contexts, integrating democratically-determined policy into those systems could align their behavior with human goals in a way that is responsive to a constantly evolving society.