 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Learning of Efficient Fulfilment and Routing Strategies in E-Commerce
Nov 20, 2023This paper presents an integrated algorithmic framework for minimising product delivery costs in e-commerce (known as the cost-to-serve or C2S). One of the major challenges in e-commerce is the large volume of spatio-temporally diverse orders from multiple customers, each of which has to be fulfilled from one of several warehouses using a fleet of vehicles. This results in two levels of decision-making: (i) selection of a fulfillment node for each order (including the option of deferral to a future time), and then (ii) routing of vehicles (each of which can carry multiple orders originating from the same warehouse). We propose an approach that combines graph neural networks and reinforcement learning to train the node selection and vehicle routing agents. We include real-world constraints such as warehouse inventory capacity, vehicle characteristics such as travel times, service times, carrying capacity, and customer constraints including time windows for delivery. The complexity of this problem arises from the fact that outcomes (rewards) are driven both by the fulfillment node mapping as well as the routing algorithms, and are spatio-temporally distributed. Our experiments show that this algorithmic pipeline outperforms pure heuristic policies.
DCT: Dual Channel Training of Action Embeddings for Reinforcement Learning with Large Discrete Action Spaces
Jun 28, 2023



The ability to learn robust policies while generalizing over large discrete action spaces is an open challenge for intelligent systems, especially in noisy environments that face the curse of dimensionality. In this paper, we present a novel framework to efficiently learn action embeddings that simultaneously allow us to reconstruct the original action as well as to predict the expected future state. We describe an encoder-decoder architecture for action embeddings with a dual channel loss that balances between action reconstruction and state prediction accuracy. We use the trained decoder in conjunction with a standard reinforcement learning algorithm that produces actions in the embedding space. Our architecture is able to outperform two competitive baselines in two diverse environments: a 2D maze environment with more than 4000 discrete noisy actions, and a product recommendation task that uses real-world e-commerce transaction data. Empirical results show that the model results in cleaner action embeddings, and the improved representations help learn better policies with earlier convergence.
Learning to Minimize Cost-to-Serve for Multi-Node Multi-Product Order Fulfilment in Electronic Commerce
Dec 16, 2021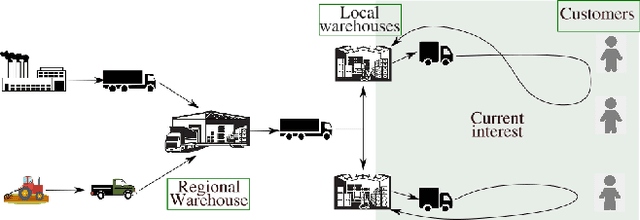
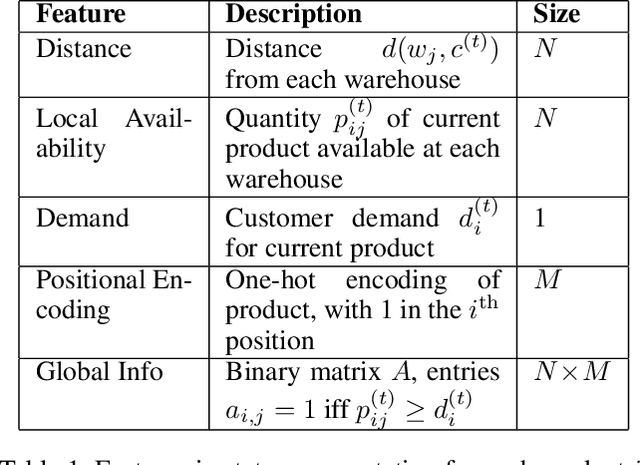

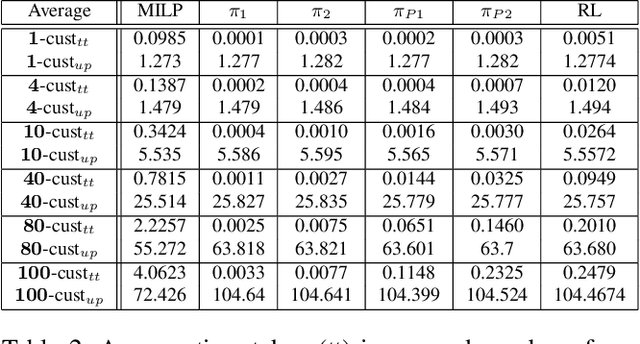
We describe a novel decision-making problem developed in response to the demands of retail electronic commerce (e-commerce). While working with logistics and retail industry business collaborators, we found that the cost of delivery of products from the most opportune node in the supply chain (a quantity called the cost-to-serve or CTS) is a key challenge. The large scale, high stochasticity, and large geographical spread of e-commerce supply chains make this setting ideal for a carefully designed data-driven decision-making algorithm. In this preliminary work, we focus on the specific subproblem of delivering multiple products in arbitrary quantities from any warehouse to multiple customers in each time period. We compare the relative performance and computational efficiency of several baselines, including heuristics and mixed-integer linear programming. We show that a reinforcement learning based algorithm is competitive with these policies, with the potential of efficient scale-up in the real world.