 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Classification Using Fewer Frames
Paper and Code
Feb 27, 2019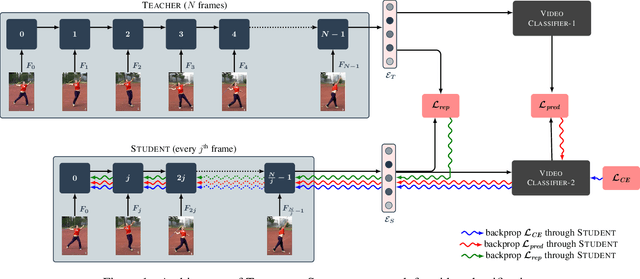
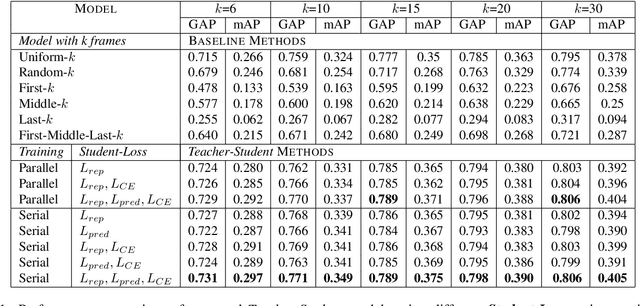
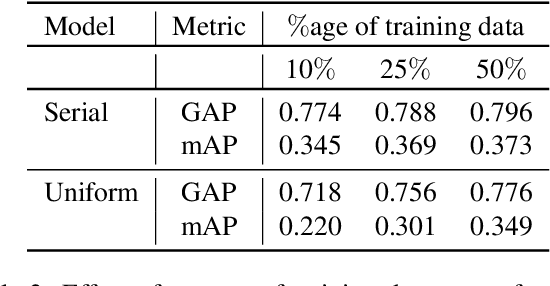
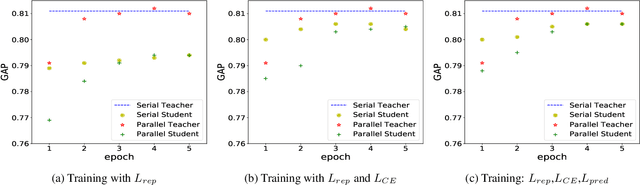
Recently,there has been a lot of interest in building compact models for video classification which have a small memory footprint (<1 GB). While these models are compact, they typically operate by repeated application of a small weight matrix to all the frames in a video. E.g. recurrent neural network based methods compute a hidden state for every frame of the video using a recurrent weight matrix. Similarly, cluster-and-aggregate based methods such as NetVLAD, have a learnable clustering matrix which is used to assign soft-clusters to every frame in the video. Since these models look at every frame in the video, the number of floating point operations (FLOPs) is still large even though the memory footprint is small. We focus on building compute-efficient video classification models which process fewer frames and hence have less number of FLOPs. Similar to memory efficient models, we use the idea of distillation albeit in a different setting. Specifically, in our case, a compute-heavy teacher which looks at all the frames in the video is used to train a compute-efficient student which looks at only a small fraction of frames in the video. This is in contrast to a typical memory efficient Teacher-Student setting, wherein both the teacher and the student look at all the frames in the video but the student has fewer parameters. Our work thus complements the research on memory efficient video classification. We do an extensive evaluation with three types of models for video classification,viz.(i) recurrent models (ii) cluster-and-aggregate models and (iii) memory-efficient cluster-and-aggregate models and show that in each of these cases, a see-it-all teacher can be used to train a compute efficient see-very-little student. We show that the proposed student network can reduce the inference time by 30% and the number of FLOPs by approximately 90% with a negligible drop in the performance.