 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Stability for Large Models Training in Constrained Bandwidth Networks
Jun 28, 2024Training extremely large language models with billions of parameters is a computationally intensive task that pushes the limits of current data parallel training systems. While techniques like ZeRO++ have enabled efficient distributed training of such giant models on inexpensive low-bandwidth clusters, they can suffer from convergence issues due to potential race conditions in the hierarchical partitioning (hpZ) scheme employed to reduce cross-machine communication. In this work, we first show how these race conditions cause instability when training models with billions of parameters. We then propose a modification to the partitioning algorithm that addresses these convergence challenges while maintaining competitive training efficiency. Empirical evaluation on training the multi-billion parameters Falcon Models and Llama-2 models demonstrates the updated algorithm's ability to achieve reliable convergence on these massive models, where stock ZeRO++ hpZ fails to converge. The updated algorithm enables robust training of larger models with 98\% throughput and model training speed improvement without sacrificing the quality of convergence.
Apache Submarine: A Unified Machine Learning Platform Made Simple
Aug 22, 2021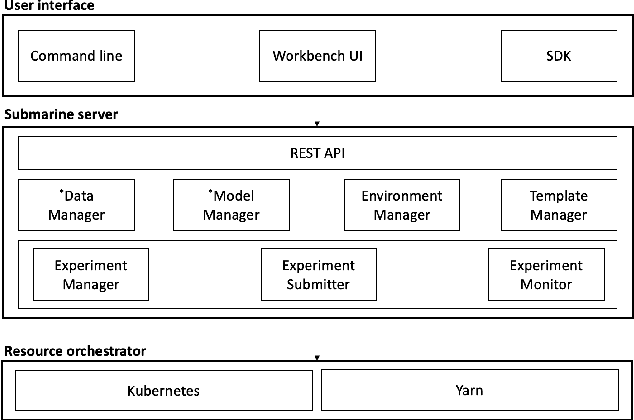
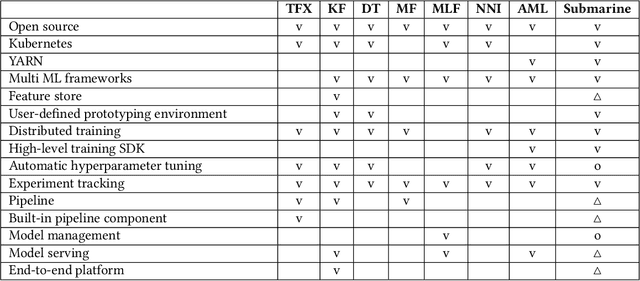
As machine learning is applied more widely, it is necessary to have a machine learning platform for both infrastructure administrators and users including expert data scientists and citizen data scientists to improve their productivity. However, existing machine learning platforms are ill-equipped to address the "Machine Learning tech debts" such as glue code, reproducibility, and portability. Furthermore, existing platforms only take expert data scientists into consideration, and thus they are inflexible for infrastructure administrators and non-user-friendly for citizen data scientists. We propose Submarine, a unified machine learning platform, to address the challenges.