 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAME: Evaluating Simulatability Metrics for Free-Text Rationales
Paper and Code
Jul 02, 2022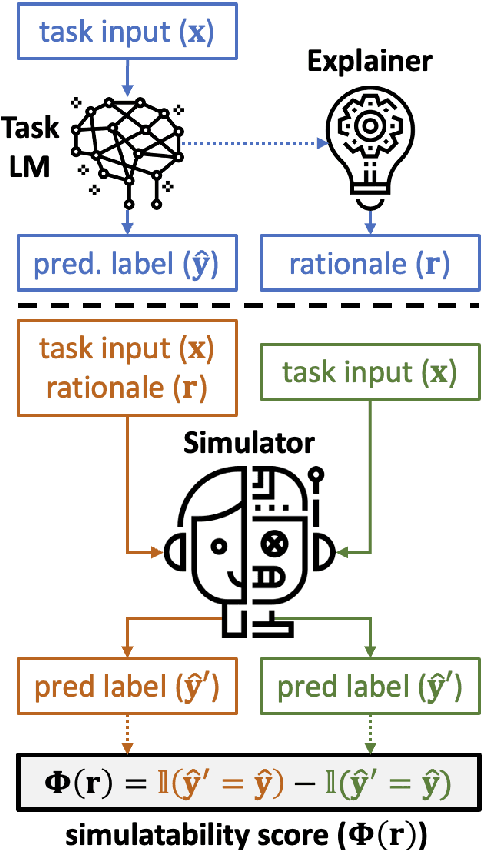
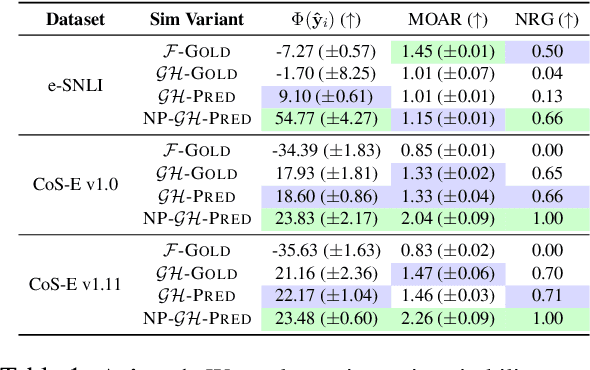

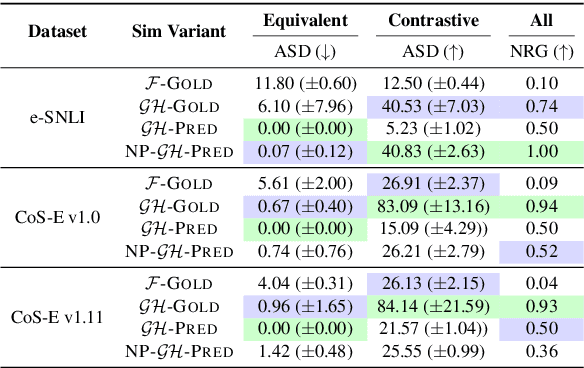
Free-text rationales aim to explain neural language model (LM) behavior more flexibly and intuitively via natural language. To ensure rationale quality, it is important to have metrics for measuring rationales' faithfulness (reflects LM's actual behavior) and plausibility (convincing to humans). All existing free-text rationale metrics are based on simulatability (association between rationale and LM's predicted label), but there is no protocol for assessing such metrics' reliability. To investigate this, we propose FRAME, a framework for evaluating free-text rationale simulatability metrics. FRAME is based on three axioms: (1) good metrics should yield highest scores for reference rationales, which maximize rationale-label association by construction; (2) good metrics should be appropriately sensitive to semantic perturbation of rationales; and (3) good metrics should be robust to variation in the LM's task performance. Across three text classification datasets, we show that existing simulatability metrics cannot satisfy all three FRAME axioms, since they are implemented via model pretraining which muddles the metric's signal. We introduce a non-pretraining simulatability variant that improves performance on (1) and (3) by an average of 41.7% and 42.9%, respectively, while performing competitively on (2).