 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniREx: A Unified Learning Framework for Language Model Rationale Extraction
Paper and Code
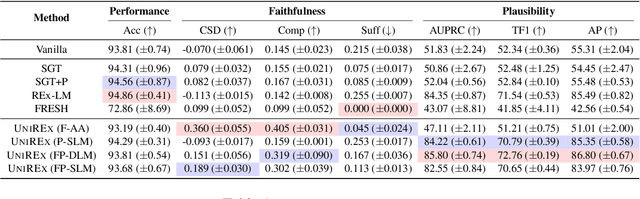
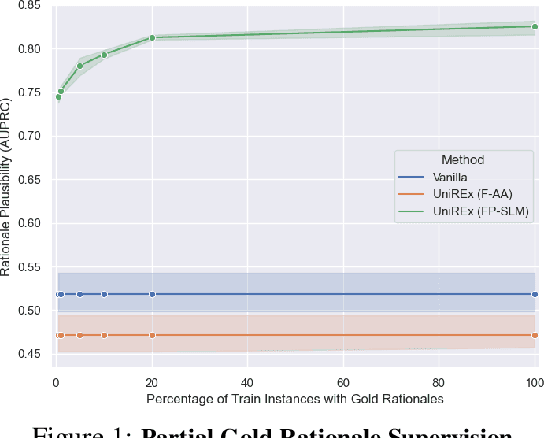
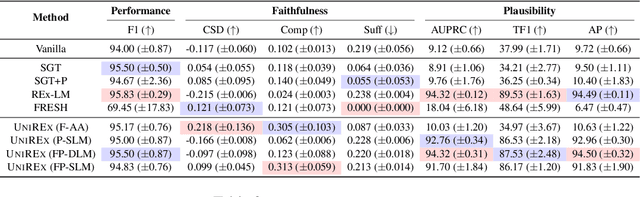
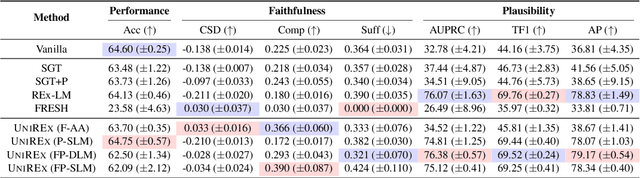
An extractive rationale explains a language model's (LM's) prediction on a given task instance by highlighting the text inputs that most influenced the output. Ideally, rationale extraction should be faithful (reflects LM's behavior), plausible (makes sense to humans), data-efficient, and fast, without sacrificing the LM's task performance. Prior rationale extraction works consist of specialized approaches for addressing various subsets of these desiderata -- but never all five. Narrowly focusing on certain desiderata typically comes at the expense of ignored ones, so existing rationale extractors are often impractical in real-world applications. To tackle this challenge, we propose UniREx, a unified and highly flexible learning framework for rationale extraction, which allows users to easily account for all five factors. UniREx enables end-to-end customization of the rationale extractor training process, supporting arbitrary: (1) heuristic/learned rationale extractors, (2) combinations of faithfulness and/or plausibility objectives, and (3) amounts of gold rationale supervision. Across three text classification datasets, our best UniREx configurations achieve a superior balance of the five desiderata, when compared to strong baselines. Furthermore, UniREx-trained rationale extractors can even generalize to unseen datasets and tasks.