 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Dropped Pronouns in Chinese Conversations via Modeling Their Referents
May 17, 2019
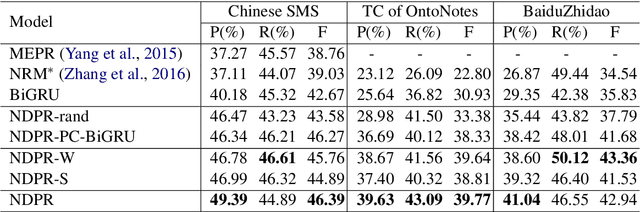
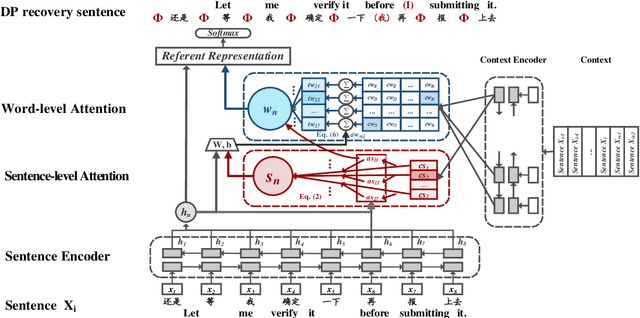
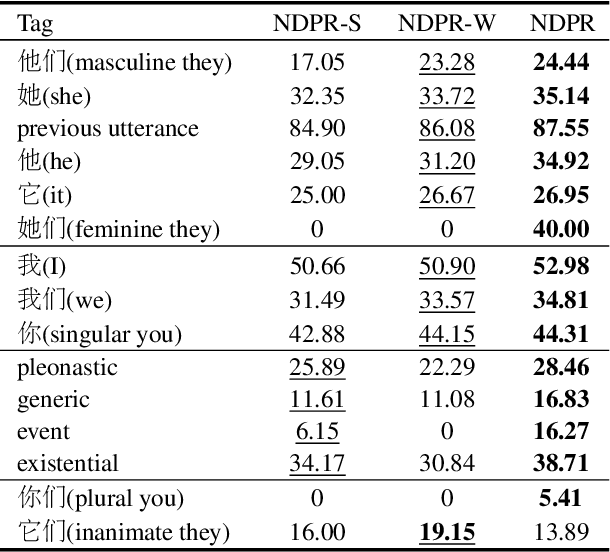
Pronouns are often dropped in Chinese sentences, and this happens more frequently in conversational genres as their referents can be easily understood from context. Recovering dropped pronouns is essential to applications such as Information Extraction where the referents of these dropped pronouns need to be resolved, or Machine Translation when Chinese is the source language. In this work, we present a novel end-to-end neural network model to recover dropped pronouns in conversational data. Our model is based on a structured attention mechanism that models the referents of dropped pronouns utilizing both sentence-level and word-level information. Results on three different conversational genres show that our approach achieves a significant improvement over the current state of the art.
Pre-training of Context-aware Item Representation for Next Basket Recommendation
Apr 14, 2019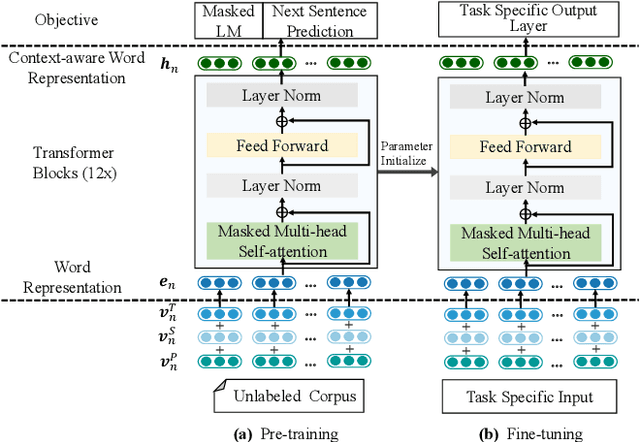
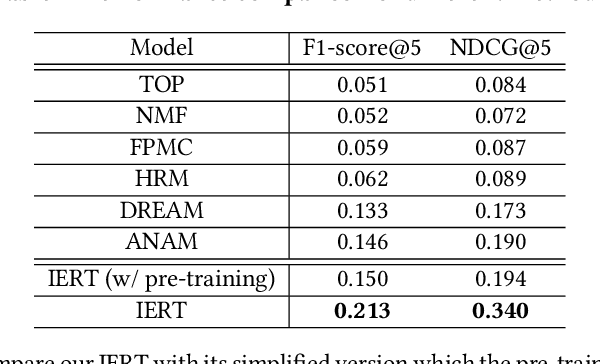
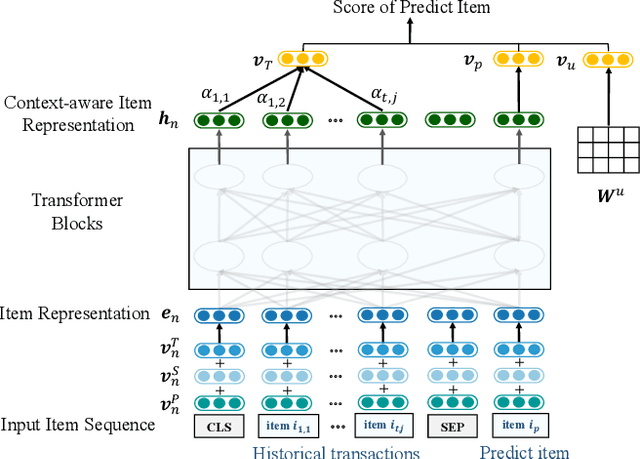
Next basket recommendation, which aims to predict the next a few items that a user most probably purchases given his historical transactions, plays a vital role in market basket analysis. From the viewpoint of item, an item could be purchased by different users together with different items, for different reasons. Therefore, an ideal recommender system should represent an item considering its transaction contexts. Existing state-of-the-art deep learning methods usually adopt the static item representations, which are invariant among all of the transactions and thus cannot achieve the full potentials of deep learning. Inspired by the pre-trained representations of BERT in natural language processing, we propose to conduct context-aware item representation for next basket recommendation, called Item Encoder Representations from Transformers (IERT). In the offline phase, IERT pre-trains deep item representations conditioning on their transaction contexts. In the online recommendation phase, the pre-trained model is further fine-tuned with an additional output layer. The output contextualized item embeddings are used to capture users' sequential behaviors and general tastes to conduct recommendation. Experimental results on the Ta-Feng data set show that IERT outperforms the state-of-the-art baseline methods, which demonstrated the effectiveness of IERT in next basket representation.