 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWALL-WM: Carving World Action Modeling at the Event Joints
Jun 01, 2026WALL-WM is a World Action Model that shifts video-action learning from chunk-centric optimization to event-grounded Vision-Language-Action pretraining, using semantically coherent action events as the atomic unit of learning. Existing WAMs commonly initialize from multimodal or video foundation models and then optimize fixed-length action chunks conditioned directly on the current observation and instruction. Although convenient, this chunk-centric formulation creates a fundamental granularity mismatch. Language describes semantic goals and events, vision evolves through continuous scene dynamics, and actions operate at control-level timescales; forcing all three into the same fixed-length prediction window turns VLA training into short-horizon correlation fitting. WALL-WM addresses this mismatch by organizing both supervision and data around semantic events. Specifically, it pairs event-grounded VLA pretraining with a data ecosystem built from event-level captions and cluster-balanced sampling, enabling scalable learning over diverse behaviors, scenes, and task structures. From the same event-pretrained backbone, WALL-WM supports two complementary inference modes. The event mode consumes next-event descriptions and enables variable-length execution chunks, while the unified mode uses a VLM with Staircase Decoding to condition conventional fixed-length chunk inference while preserving a gradient-continuous VLA path. Together with Muon-optimizer-based large-scale pretraining infrastructure, WALL-WM provides a practical scale-up recipe for general-purpose WAMs. Experiments show that WALL-WM generalizes broadly across language, scenes, and tasks, achieving state-of-the-art performance in large-scale real-world generalization evaluation.
Measuring Form and Function in Language Models
May 27, 2026We introduce quantitative metrics for child language acquisition to evaluate language models. Our focus is on the formal syntactic and functional discourse properties of determiners in English, which young children acquire early and accurately. We propose Contextual Alternative Choice (CAC), a new prompting method which provides targeted tests for both syntactic and discourse knowledge of language. The method enables direct comparison of language models against children, and more importantly, against statistical benchmarks independently established in empirical research. No current model trained on a comparable amount of data simultaneously meet both formal and functional benchmarks like human children, but some very large models do. We present our results as methodological and technical contributions, with specific emphasis on cognitive status of language models.
Evaluating Neural Language Models as Cognitive Models of Language Acquisition
Oct 31, 2023The success of neural language models (LMs) on many technological tasks has brought about their potential relevance as scientific theories of language despite some clear differences between LM training and child language acquisition. In this paper we argue that some of the most prominent benchmarks for evaluating the syntactic capacities of LMs may not be sufficiently rigorous. In particular, we show that the template-based benchmarks lack the structural diversity commonly found in the theoretical and psychological studies of language. When trained on small-scale data modeling child language acquisition, the LMs can be readily matched by simple baseline models. We advocate for the use of the readily available, carefully curated datasets that have been evaluated for gradient acceptability by large pools of native speakers and are designed to probe the structural basis of grammar specifically. On one such dataset, the LI-Adger dataset, LMs evaluate sentences in a way inconsistent with human language users. We conclude with suggestions for better connecting LMs with the empirical study of child language acquisition.
The Greedy and Recursive Search for Morphological Productivity
May 12, 2021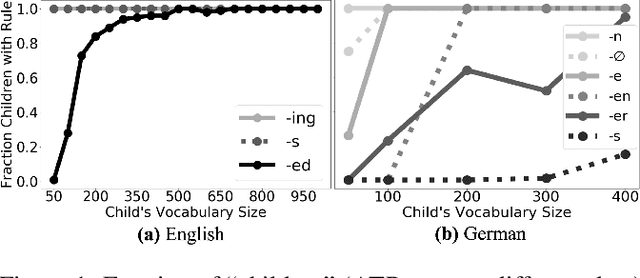
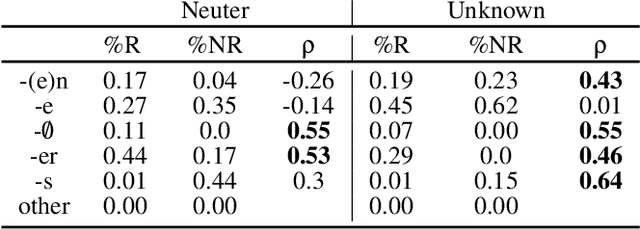
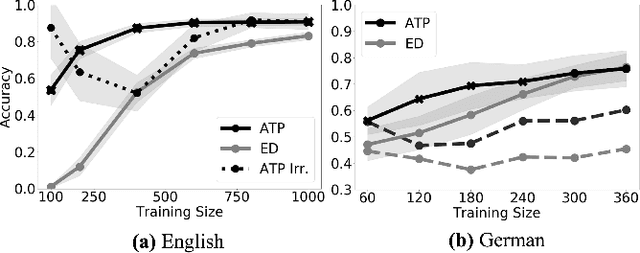
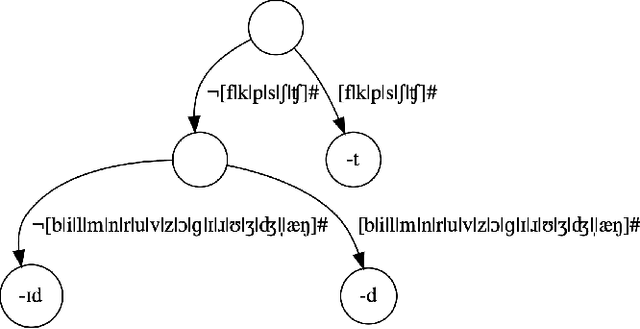
As children acquire the knowledge of their language's morphology, they invariably discover the productive processes that can generalize to new words. Morphological learning is made challenging by the fact that even fully productive rules have exceptions, as in the well-known case of English past tense verbs, which features the -ed rule against the irregular verbs. The Tolerance Principle is a recent proposal that provides a precise threshold of exceptions that a productive rule can withstand. Its empirical application so far, however, requires the researcher to fully specify rules defined over a set of words. We propose a greedy search model that automatically hypothesizes rules and evaluates their productivity over a vocabulary. When the search for broader productivity fails, the model recursively subdivides the vocabulary and continues the search for productivity over narrower rules. Trained on psychologically realistic data from child-directed input, our model displays developmental patterns observed in child morphology acquisition, including the notoriously complex case of German noun pluralization. It also produces responses to nonce words that, despite receiving only a fraction of the training data, are more similar to those of human subjects than current neural network models' responses are.
A Grounded Approach to Modeling Generic Knowledge Acquisition
May 07, 2021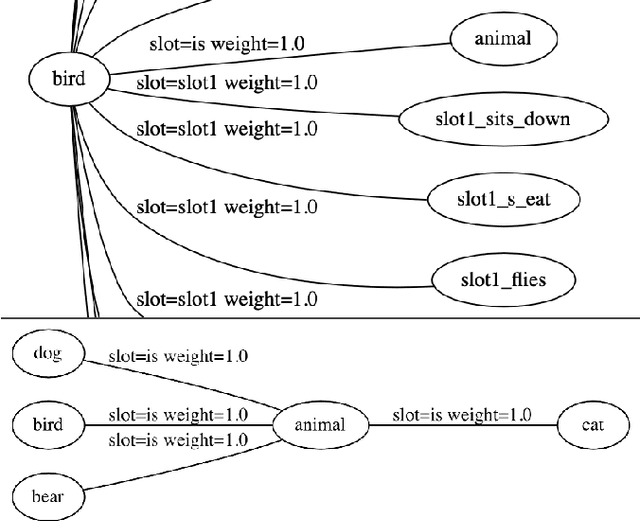
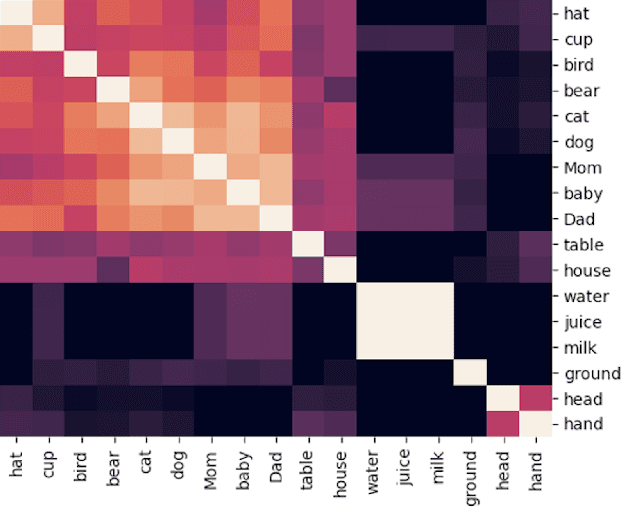

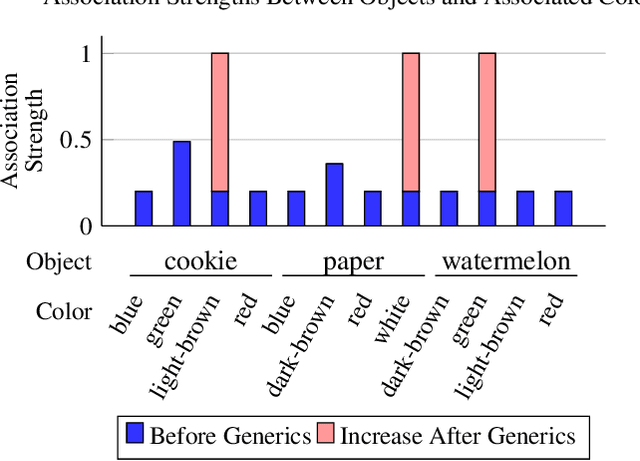
We introduce and implement a cognitively plausible model for learning from generic language, statements that express generalizations about members of a category and are an important aspect of concept development in language acquisition (Carlson & Pelletier, 1995; Gelman, 2009). We extend a computational framework designed to model grounded language acquisition by introducing the concept network. This new layer of abstraction enables the system to encode knowledge learned from generic statements and represent the associations between concepts learned by the system. Through three tasks that utilize the concept network, we demonstrate that our extensions to ADAM can acquire generic information and provide an example of how ADAM can be used to model language acquisition.
ADAM: A Sandbox for Implementing Language Learning
May 05, 2021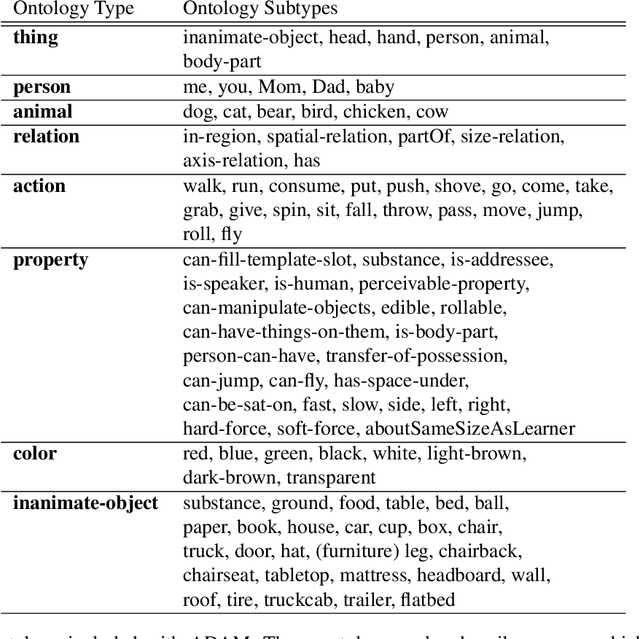

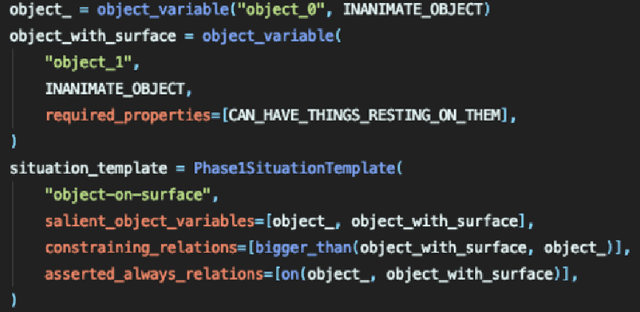
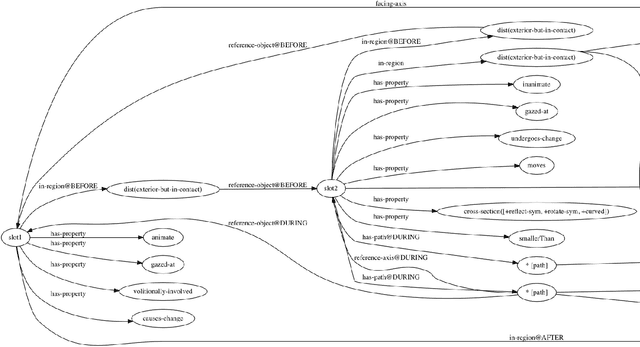
We present ADAM, a software system for designing and running child language learning experiments in Python. The system uses a virtual world to simulate a grounded language acquisition process in which the language learner utilizes cognitively plausible learning algorithms to form perceptual and linguistic representations of the observed world. The modular nature of ADAM makes it easy to design and test different language learning curricula as well as learning algorithms. In this report, we describe the architecture of the ADAM system in detail, and illustrate its components with examples. We provide our code.