 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Lexica Testing Computational Hypotheses with Deep Convolutional Neural Networks
Apr 13, 2021


Gow's (2012) dual lexicon model suggests that the primary purpose of words is to mediate the mappings between acoustic-phonetic input and other forms of linguistic representation. Motivated by evidence from functional imaging, aphasia, and behavioral results, the model argues for the existence of two parallel wordform stores: the dorsal and ventral processing streams. In this paper, we tested the hypothesis that the complex, but systematic mapping between sound and articulation in the dorsal stream poses different computational pressures on feature sets than the more arbitrary mapping between sound and meaning. To test this hypothesis, we created two deep convolutional neural networks (CNNs). While the dorsal network was trained to identify individual spoken words, the ventral network was trained to map them onto semantic classes. We then extracted patterns of network activation from the penultimate level of each network and tested how well features generated by the network supported generalization to linguistic categorization associated with the dorsal versus ventral processing streams. Our preliminary results showed both models successfully learned their tasks. Secondary generalization testing showed the ventral CNN outperformed the dorsal CNN on a semantic task: concreteness classification, while the dorsal CNN outperformed the ventral CNN on articulation tasks: classification by onset phoneme class and syllable length. These results are consistent with the hypothesis that the divergent processing demands of the ventral and dorsal processing streams impose computational pressures for the development of multiple lexica.
Subregular Complexity and Deep Learning
Oct 14, 2017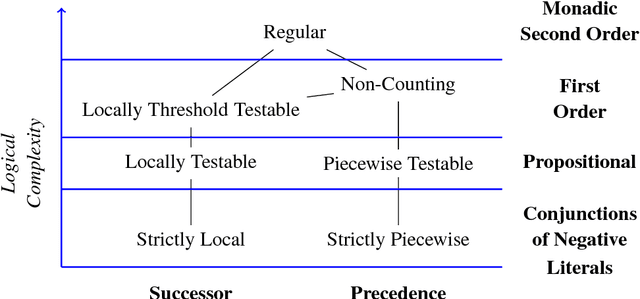

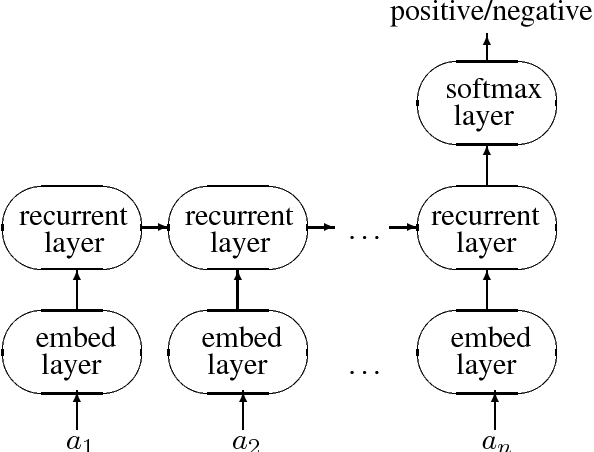
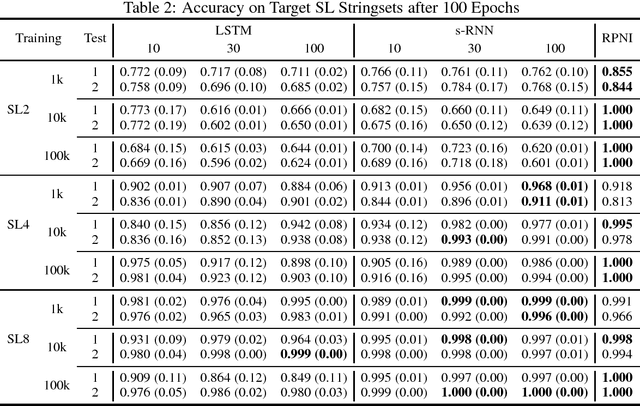
This paper argues that the judicial use of formal language theory and grammatical inference are invaluable tools in understanding how deep neural networks can and cannot represent and learn long-term dependencies in temporal sequences. Learning experiments were conducted with two types of Recurrent Neural Networks (RNNs) on six formal languages drawn from the Strictly Local (SL) and Strictly Piecewise (SP) classes. The networks were Simple RNNs (s-RNNs) and Long Short-Term Memory RNNs (LSTMs) of varying sizes. The SL and SP classes are among the simplest in a mathematically well-understood hierarchy of subregular classes. They encode local and long-term dependencies, respectively. The grammatical inference algorithm Regular Positive and Negative Inference (RPNI) provided a baseline. According to earlier research, the LSTM architecture should be capable of learning long-term dependencies and should outperform s-RNNs. The results of these experiments challenge this narrative. First, the LSTMs' performance was generally worse in the SP experiments than in the SL ones. Second, the s-RNNs out-performed the LSTMs on the most complex SP experiment and performed comparably to them on the others.