 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory Grammar Semantic Matching for Literary Study
Feb 17, 2025
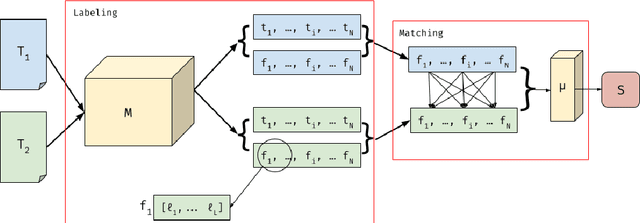
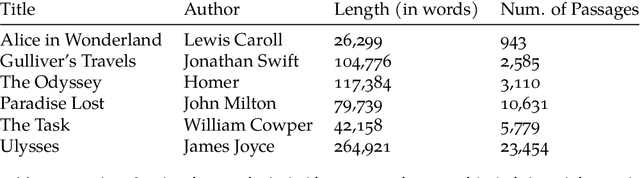
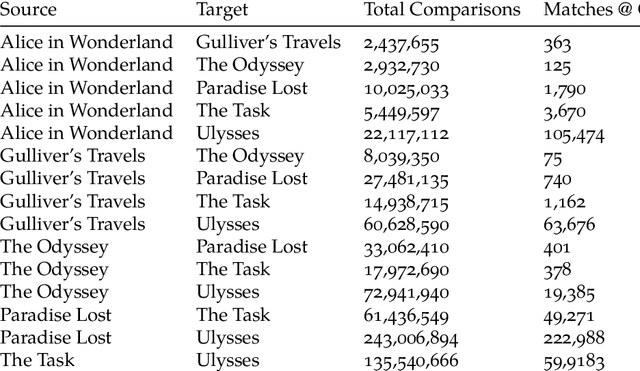
In Natural Language Processing (NLP), semantic matching algorithms have traditionally relied on the feature of word co-occurrence to measure semantic similarity. While this feature approach has proven valuable in many contexts, its simplistic nature limits its analytical and explanatory power when used to understand literary texts. To address these limitations, we propose a more transparent approach that makes use of story structure and related elements. Using a BERT language model pipeline, we label prose and epic poetry with story element labels and perform semantic matching by only considering these labels as features. This new method, Story Grammar Semantic Matching, guides literary scholars to allusions and other semantic similarities across texts in a way that allows for characterizing patterns and literary technique.
Nostra Domina at EvaLatin 2024: Improving Latin Polarity Detection through Data Augmentation
Apr 11, 2024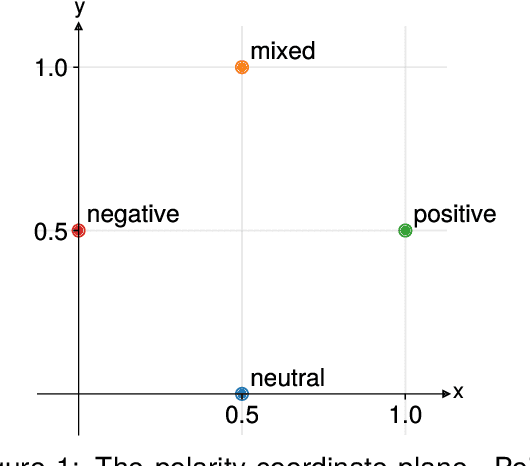
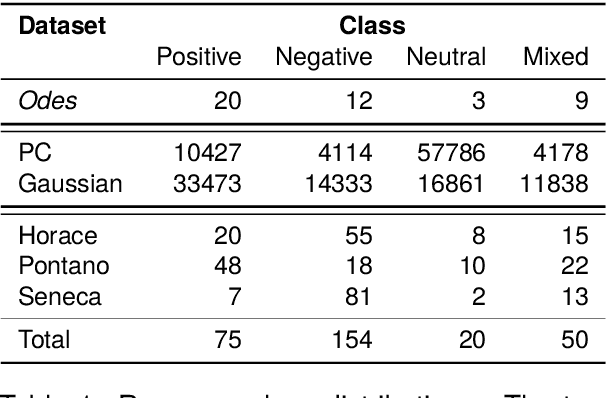
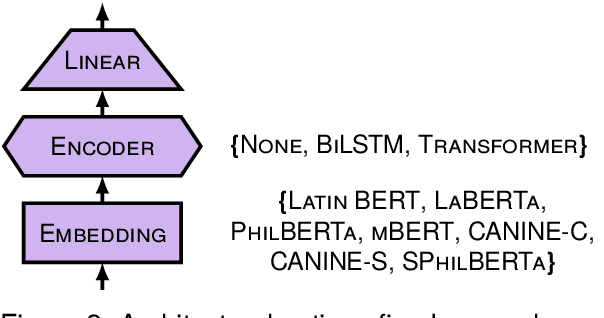
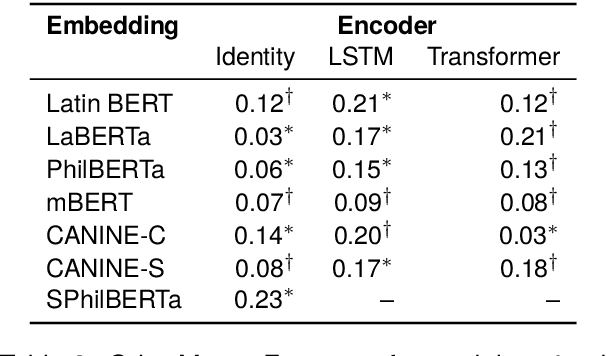
This paper describes submissions from the team Nostra Domina to the EvaLatin 2024 shared task of emotion polarity detection. Given the low-resource environment of Latin and the complexity of sentiment in rhetorical genres like poetry, we augmented the available data through automatic polarity annotation. We present two methods for doing so on the basis of the $k$-means algorithm, and we employ a variety of Latin large language models (LLMs) in a neural architecture to better capture the underlying contextual sentiment representations. Our best approach achieved the second highest macro-averaged Macro-$F_1$ score on the shared task's test set.
Using Random Perturbations to Mitigate Adversarial Attacks on Sentiment Analysis Models
Feb 11, 2022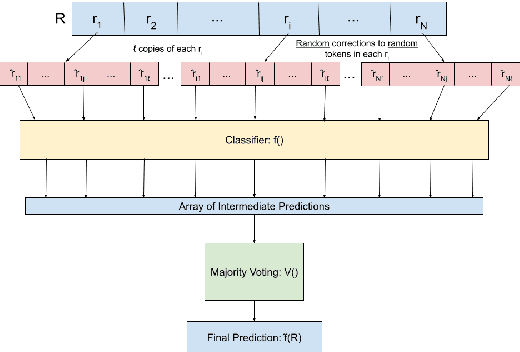
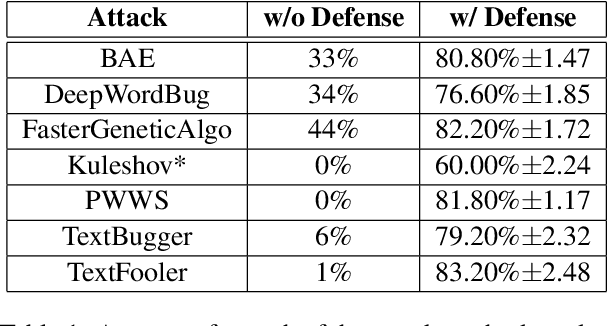
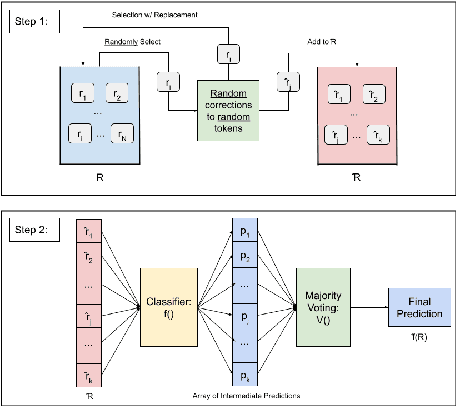
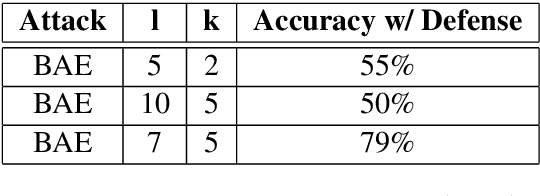
Attacks on deep learning models are often difficult to identify and therefore are difficult to protect against. This problem is exacerbated by the use of public datasets that typically are not manually inspected before use. In this paper, we offer a solution to this vulnerability by using, during testing, random perturbations such as spelling correction if necessary, substitution by random synonym, or simply dropping the word. These perturbations are applied to random words in random sentences to defend NLP models against adversarial attacks. Our Random Perturbations Defense and Increased Randomness Defense methods are successful in returning attacked models to similar accuracy of models before attacks. The original accuracy of the model used in this work is 80% for sentiment classification. After undergoing attacks, the accuracy drops to accuracy between 0% and 44%. After applying our defense methods, the accuracy of the model is returned to the original accuracy within statistical significance.