 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory Grammar Semantic Matching for Literary Study
Feb 17, 2025
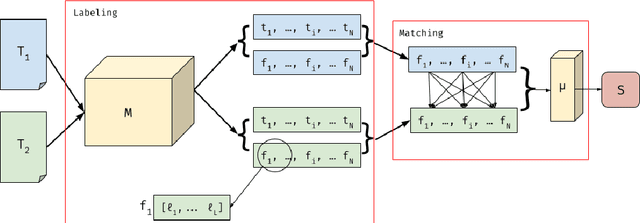
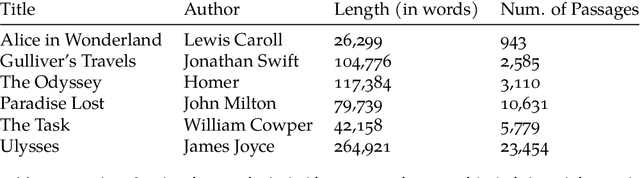
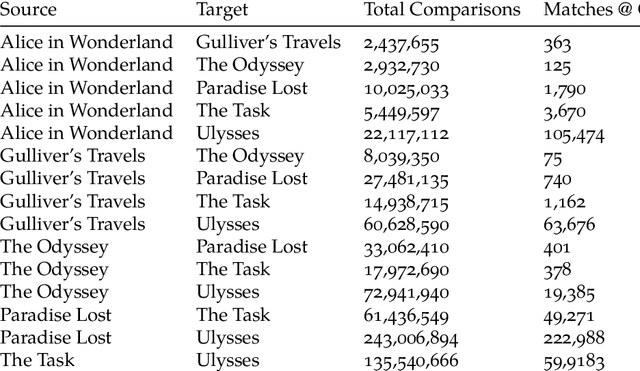
In Natural Language Processing (NLP), semantic matching algorithms have traditionally relied on the feature of word co-occurrence to measure semantic similarity. While this feature approach has proven valuable in many contexts, its simplistic nature limits its analytical and explanatory power when used to understand literary texts. To address these limitations, we propose a more transparent approach that makes use of story structure and related elements. Using a BERT language model pipeline, we label prose and epic poetry with story element labels and perform semantic matching by only considering these labels as features. This new method, Story Grammar Semantic Matching, guides literary scholars to allusions and other semantic similarities across texts in a way that allows for characterizing patterns and literary technique.